An error may occur when you use PyTorch on a GPU-accelerated Linux instance because the version of Compute Unified Device Architecture (CUDA) installed on the instance is incompatible with the version of PyTorch. This topic describes the cause of and the solutions to this issue.
Problem description
The following error message is displayed when you use PyTorch on a GPU-accelerated Linux instance that runs an Alibaba Cloud Linux 3:
>>> import torch
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.8/dist-packages/torch/__init__.py", line 235, in <module>
from torch._C import * # noqa: F403
ImportError: /usr/local/lib/python3.8/dist-packages/torch/lib/../../nvidia/cusparse/lib/libcusparse.so.12: undefined symbol: __nvJitLinkAddData_12_1, version libnvJitLink.so.12Cause
The preceding error may be caused by the incompatibility between the version of CUDA installed on the GPU-accelerated instance and the PyTorch version. For more information about the mappings between the CUDA version and the PyTorch version, see Previous PyTorch Versions.
The version of PyTorch installed by running the sudo pip3 install torch command is 2.1.2, and the compatible CUDA version is 12.1. However, the CUDA version automatically installed on the purchased GPU-accelerated instance is 12.0. This version does not match the CUDA version that is compatible with the installed PyTorch version.
Solution
If you selected Auto-install GPU Driver on the Public Images tab in the Image section when you purchased the GPU-accelerated instance in the Elastic Compute Service (ECS) console, you can change the CUDA version to 12.1 by using one of the following methods:
Stop the GPU-accelerated instance.
For more information, see Stop instances.
On the Instance page, find the stopped GPU-accelerated instance and click the
 icon in the Actions column. In the Instance Settings section, click Set User Data.
icon in the Actions column. In the Instance Settings section, click Set User Data. Modify the user data and click OK.
Change the values of the
DRIVER_VERSION,CUDA_VERSION, andCUDNN_VERSIONparameters to the following versions:... DRIVER_VERSION="535.154.05" CUDA_VERSION="12.1.1" CUDNN_VERSION="8.9.7.29" ...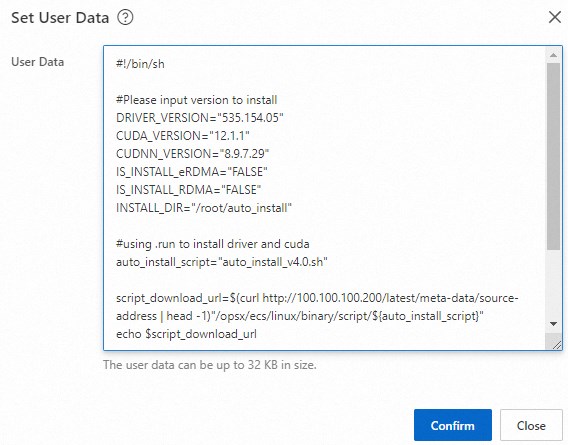
Change the OS of the GPU-accelerated instance.
For more information, see Replace the operating system (system disk) of an instance.
After the GPU-accelerated instance is restarted, the system re-installs the new versions of the NVIDIA Tesla driver, CUDA, and CUDA Deep Neural Network library (cuDNN).