When a High-speed Service Framework (HSF) service provider has unhealthy instances, the consumer has no built-in way to detect them. Requests routed to these instances fail, degrading the consumer's availability. Outlier instance removal solves this by continuously monitoring provider instances, automatically ejecting unhealthy ones from the load balancing pool, and restoring them after recovery.
How it works
Consider a system where Application A calls instances of Applications B, C, and D. If Application B has one unhealthy instance and Applications C and D each have two, a portion of requests from Application A fail. As more provider instances become unhealthy, Application A's overall performance degrades.
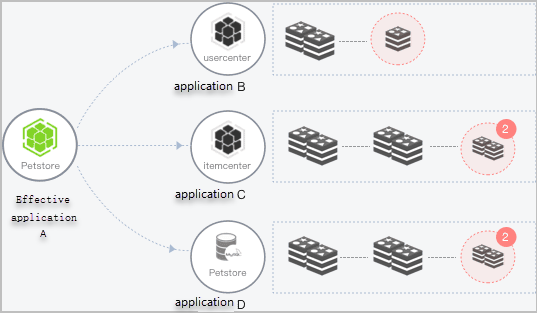
To protect Application A, configure an outlier ejection policy on the consumer side. Enterprise Distributed Application Service (EDAS) then manages each provider instance through this lifecycle:
Detect. EDAS monitors provider instances and identifies those whose error rate exceeds the configured threshold within the statistics time window.
Eject. EDAS removes unhealthy instances from the load balancing pool, subject to the maximum instance removal ratio. Requests from Application A stop routing to ejected instances.
Probe. EDAS periodically checks whether ejected instances have recovered. The probe interval starts at the configured recovery detection unit time and increases linearly with each consecutive failed probe.
Cap. When consecutive failed probes reach the configured maximum, the probe interval stops increasing and remains at its maximum value.
Restore. After an ejected instance recovers, EDAS adds it back to the pool and resets the probe interval to the initial value.
If the ratio of unhealthy instances exceeds the maximum instance removal ratio, EDAS only ejects instances up to that ratio. This prevents removing too many instances at once.
If a provider has only one available instance, EDAS does not eject it, even when its error rate exceeds the threshold.
Create an outlier ejection policy
HSF applications support outlier ejection policies at two levels:
Application-level -- Applies to all services provided by the application. Uses
"ipDimension": truein the configuration.Service-level -- Targets a specific service and version. Takes precedence over the application-level policy.
Before you begin, make sure you have:
An HSF application deployed on EDAS
Access to the EDAS console
Step 1: Open configuration management
Log on to the EDAS console.
In the left-side navigation pane, choose Application Management > Microservice Configurations > Configurations.
In the top navigation bar, select a region. On the Configurations page, select a microservices namespace from the drop-down list.
Click Create Configuration.
Step 2: Set policy parameters
In the Create Configuration panel, set the following parameters:
Parameter | Description |
Region | Pre-populated with the region you selected. Cannot be changed. |
Microservice Namespace | Pre-populated with the namespace you selected. Cannot be changed. |
Data ID | Enter the ID in the format |
Group | Fixed to |
Data encryption | Turn on to encrypt sensitive policy data and reduce the risk of data leaks. |
Configuration Format | Select the data format. The system validates the content against this format. |
Configuration Content | Enter the JSON policy configuration. See the examples below. |
Step 3: Enter the policy configuration
Use the following JSON examples as templates. Replace the parameter values based on your requirements.
Application-level policy
This configuration applies to all services under the application. Set "ipDimension": true to enable per-instance tracking.
{
"DEFAULT": {
"errorRateThreshold": 0.5,
"isolationTime": 60000,
"maxIsolationRate": 0.2,
"maxIsolationTimeMultiple": 15,
"qosEnabled": true,
"requestThreshold": 20,
"timeWindowInSeconds": 10,
"ipDimension": true
}
}Service-level policy
Define a DEFAULT block for the baseline and add a "service:version" block for service-specific overrides. The service-level block takes precedence.
{
"DEFAULT": {
"errorRateThreshold": 0.5,
"isolationTime": 60000,
"maxIsolationRate": 0.2,
"maxIsolationTimeMultiple": 15,
"qosEnabled": true,
"requestThreshold": 20,
"timeWindowInSeconds": 10
},
"service:version": {
"errorRateThreshold": 0.5,
"isolationTime": 60000,
"maxIsolationRate": 0.2,
"maxIsolationTimeMultiple": 15,
"qosEnabled": true,
"requestThreshold": 20,
"timeWindowInSeconds": 10
}
}Replace service:version with the actual service name and version, for example com.alibaba.edas.OrderService:1.0.0.
Step 4: Save the policy
Click Create at the bottom of the panel.
Parameter reference
Configure outlier ejection through configuration management (JSON properties) or JVM -D parameters. Configuration management settings take precedence over -D parameters.
Parameter | Property | JVM parameter | Default | Description |
Enable outlier instance removal |
|
|
| Enable or disable outlier ejection for the application or service. |
Request threshold |
|
|
| Minimum number of requests in the current statistics window before ejection can occur. Prevents ejection based on insufficient sample data. |
Error rate threshold |
|
|
| Error rate above which an instance is ejected. |
Maximum instance removal ratio |
|
|
| Maximum proportion of instances that can be ejected at once. The result is rounded down. Example: 6 instances x 60% = 3.6, rounded down to 3. If the result is less than 1, one instance can still be ejected. |
Recovery detection unit time |
|
|
| Base probe interval in milliseconds. After ejection, EDAS probes the instance at intervals that increase linearly: 1x, 2x, 3x, ... multiplied by this value. |
Maximum probe count |
|
|
| Maximum number of probes before the interval stops increasing. Example: with a unit time of 60,000 ms and a max count of 60, the longest interval is 60 x 60,000 ms = 60 minutes. If the instance recovers before this count, the interval resets to the base unit time. |
Statistics time window |
|
|
| Sliding window duration for counting requests and calculating error rates. |
Exception type |
|
|
| Determines which exceptions count toward the error rate. Options: |
Verify the result
After the policy takes effect, verify it through application monitoring:
Open the application details page in the EDAS console.
Go to the Topology tab.
Check the following indicators:
Request routing -- Confirm that requests are no longer routed to ejected instances.
Error Rate / 1 Min -- Confirm that the error rate has dropped below the configured
errorRateThreshold.
For detailed monitoring metrics, see Application overview.