This topic describes how to use Data Transmission Service (DTS) to migrate data from a self-managed PostgreSQL database to an AnalyticDB for PostgreSQL instance.
Prerequisites
You have created the destination AnalyticDB for PostgreSQL instance. For more information, see Create an instance.
NoteFor information about the supported versions of the source and destination databases, see Overview of data migration scenarios.
The available disk space of the destination AnalyticDB for PostgreSQL instance is larger than the disk space occupied by the source self-managed PostgreSQL database.
Precautions
During schema migration, DTS migrates foreign keys from the source database to the destination database.
During full data migration and incremental data migration, DTS temporarily disables the constraint check and cascade operations on foreign keys at the session level. If you perform the cascade update and delete operations on the source database during data migration, data inconsistency may occur.
Category | Description |
Source database limits |
|
Other limits |
|
Billing
Migration type | Instance configuration fee | Internet traffic fee |
Schema migration and full data migration | Free of charge. | When the Access Method parameter of the destination database is set to Public IP Address, you are charged for Internet traffic. For more information, see Billing overview. |
Incremental data migration | Charged. For more information, see Billing overview. |
Migration types
Schema migration
DTS migrates the schemas of the selected objects from the source database to the destination database.
Full data migration
DTS migrates the historical data of required objects from the source database to the destination database.
Incremental data migration
After full data migration is complete, DTS migrates incremental data from the source database to the destination database. Incremental data migration allows data to be migrated smoothly without interrupting the services of self-managed applications during data migration.
SQL operations that support incremental migration
Operation type | SQL statement |
DML | INSERT, UPDATE, and DELETE Note When data is written to the destination AnalyticDB for PostgreSQL instance, the UPDATE statement is automatically converted to the REPLACE INTO statement. If the UPDATE statement is executed on primary keys, the UPDATE statement is converted to the DELETE and INSERT statements. |
DDL |
|
Permissions required for database accounts
Database | Schema migration | Full migration | Incremental migration |
Self-managed PostgreSQL | USAGE permission on pg_catalog. | Permissions for SELECT statement on the migration objects. | Superuser permissions. |
AnalyticDB for PostgreSQL | Permissions of the schema owner. Note You can also use the initial account. | ||
To create a database account and grant permissions:
For a self-managed PostgreSQL database, see the official documentation for the CREATE USER and GRANT syntax.
For an AnalyticDB for PostgreSQL instance, see Create and manage a user and User permission management.
Preparations
For more information about how to make preparations if your source database is an Amazon RDS for PostgreSQL instance, see the Before you begin section of the "Migrate incremental data from an Amazon RDS for PostgreSQL instance to an ApsaraDB RDS for PostgreSQL instance" topic. For more information about how to make preparations if your source database is an Amazon Aurora PostgreSQL instance, see the Preparation 1: Edit the inbound rule of the Amazon Aurora PostgreSQL instance section of the "Migrate full data from an Amazon Aurora PostgreSQL instance to an ApsaraDB RDS for PostgreSQL instance" topic.
In this example, a self-managed PostgreSQL database that runs on a Linux server is used.
If the version of the self-managed PostgreSQL database is 10.1 or later, you must perform the following operations before you configure a data migration task.
Log on to the server on which the self-managed PostgreSQL database resides.
Modify the
postgresql.confconfiguration file. Set thewal_levelparameter tological, and make sure that the values of themax_wal_sendersandmax_replication_slotsparameters are greater than the sum of the number of used replication slots in the self-managed PostgreSQL database and the number of DTS instances whose source database is the self-managed PostgreSQL database.# - Settings - wal_level = logical # minimal, replica, or logical # (change requires restart) ...... # - Sending Server(s) - # Set these on the master and on any standby that will send replication data. max_wal_senders = 10 # max number of walsender processes # (change requires restart) #wal_keep_segments = 0 # in logfile segments, 16MB each; 0 disables #wal_sender_timeout = 60s # in milliseconds; 0 disables max_replication_slots = 10 # max number of replication slots # (change requires restart)NoteAfter you modify the configuration file, restart the self-managed PostgreSQL database to make the parameter settings take effect.
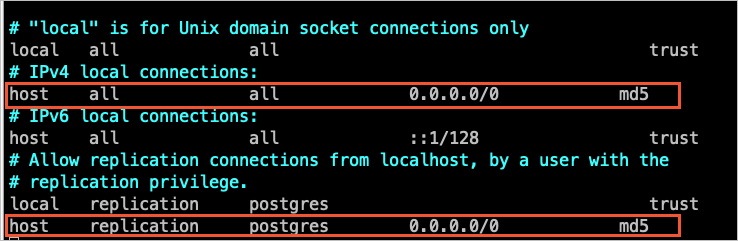
Add the CIDR blocks of DTS servers to the pg_hba.conf configuration file of the self-managed PostgreSQL database. Add only the CIDR blocks of the DTS servers that reside in the same region as the destination database. For more information, see Add DTS server IP addresses to a whitelist.
NoteAfter you modify the configuration file, execute the
SELECT pg_reload_conf();statement or restart the self-managed PostgreSQL database to make the parameter settings take effect.For more information about the pg_hba.conf configuration file, see The pg_hba.conf File. Skip this step if you have set the IP address in the pg_hba.conf file to
0.0.0.0/0. The following figure shows the configurations.
Create the corresponding database and schema in the destination cluster based on the information of the database and schema of the object to be migrated.
If the version of the self-managed PostgreSQL database is 9.4.8 to 10.0, you must perform the following operations before you configure a data migration task:
Download the PostgreSQL source code from the official website, compile the source code, and install PostgreSQL.
Download the source code from the PostgreSQL official website based on the version of the self-managed PostgreSQL database.
Run the
sudo ./configure,sudo make, andsudo make installcommands in sequence to configure and compile the source code, and install PostgreSQL.ImportantWhen you compile and install PostgreSQL, the OS version of PostgreSQL must be consistent with the version of the GNU compiler collection (GCC).
If an error occurs when you run the
sudo ./configurecommand, you can modify the command based on the error message. For example, if the error message isreadline library not found. Use --without-readline to disable readline support., you can modify the command tosudo ./configure --without-readline.If you use another method to install PostgreSQL, you must compile the ali_decoding plug-in in a test environment that has the same operating system version and GCC version.
Download the ali_decoding plug-in provided by DTS, and compile and install the plug-in.
Download ali_decoding.
Copy the ali_decoding directory to the contrib directory of PostgreSQL that is compiled and installed.
Go to the ali_decoding directory and replace the content of the Makefile file with the following script:
# contrib/ali_decoding/Makefile MODULE_big = ali_decoding MODULES = ali_decoding OBJS = ali_decoding.o DATA = ali_decoding--0.0.1.sql ali_decoding--unpackaged--0.0.1.sql EXTENSION = ali_decoding NAME = ali_decoding #subdir = contrib/ali_decoding #top_builddir = ../.. #include $(top_builddir)/src/Makefile.global #include $(top_srcdir)/contrib/contrib-global.mk #PG_CONFIG = /usr/pgsql-9.6/bin/pg_config #pgsql_lib_dir := $(shell $(PG_CONFIG) --libdir) #PGXS := $(shell $(PG_CONFIG) --pgxs) #include $(PGXS) # Run the following commands to install the ali_decoding plug-in: ifdef USE_PGXS PG_CONFIG = pg_config PGXS := $(shell $(PG_CONFIG) --pgxs) include $(PGXS) else subdir = contrib/ali_decoding top_builddir = ../.. include $(top_builddir)/src/Makefile.global include $(top_srcdir)/contrib/contrib-global.mk endifGo to the ali_decoding directory, and run the
sudo makeandsudo make installcommands in sequence to compile the ali_decoding plug-in and obtain the files that are required to install the ali_decoding plug-in.Copy the files to the specified directories.

Create the corresponding database and schema in the destination cluster based on the information of the database and schema of the object to be migrated.
Procedure
Use one of the following methods to go to the Data Migration page and select the region in which the data migration instance resides.
DTS console
Log on to the DTS console.
In the left-side navigation pane, click Data Migration.
In the upper-left corner of the page, select the region in which the data migration instance resides.
DMS console
NoteThe actual operation may vary based on the mode and layout of the DMS console. For more information, see Simple mode and Customize the layout and style of the DMS console.
Log on to the DMS console.
In the top navigation bar, move the pointer over .
From the drop-down list to the right of Data Migration Tasks, select the region in which the data synchronization instance resides.
Click Create Task to go to the task configuration page.
Configure the source and destination databases. The following table describes the parameters.
WarningAfter you select the source and destination instances, we recommend that you carefully read the Limits section at the top of the page. This helps ensure that you can successfully create and execute the migration task.
Category
Configuration
Description
N/A
Task Name
The name of the DTS task. DTS automatically generates a task name. We recommend that you specify an informative name that makes it easy to identify the task. You do not need to specify a unique task name.
Source Database
Select Existing Connection
If you use a database instance that is registered with DTS, select the instance from the drop-down list. DTS automatically populates the following database parameters for the instance. For more information, see Manage database connections.
NoteIn the DMS console, you can select the database instance from the Select a DMS database instance drop-down list.
If you fail to register the instance with DTS, or you do not need to use the instance that is registered with DTS, you must configure the following database information.
Database Type
Select PostgreSQL.
Access Method
Select the deployment location of the source database. This topic uses a Self-managed Database on ECS as an example to describe the configuration process.
NoteIf you select another method to access the self-managed database, you must perform corresponding preparations. For more information, see Preparations.
Instance Region
Select the region where the self-managed PostgreSQL database resides.
ECS Instance ID
Enter the ID of the ECS instance on which the self-managed PostgreSQL database is deployed.
Port Number
The service port of the self-managed PostgreSQL database. Default value: 5432.
Database Name
Enter the name of the database in the self-managed PostgreSQL database to which the migration objects belong.
Database Account
Enter the database account of the self-managed PostgreSQL database. For information about the required permissions, see Permissions required for database accounts.
Database Password
The password that is used to access the database instance.
Encryption
Specifies whether to encrypt the connection to the source database. You can configure this parameter based on your business requirements. In this example, Non-encrypted is selected.
If you want to establish an SSL-encrypted connection to the source database, perform the following steps: Select SSL-encrypted, upload CA Certificate, Client Certificate, and Private Key of Client Certificate as needed, and then specify Private Key Password of Client Certificate.
NoteIf you set Encryption to SSL-encrypted for a self-managed PostgreSQL database, you must upload CA Certificate.
If you want to use the client certificate, you must upload Client Certificate and Private Key of Client Certificate and specify Private Key Password of Client Certificate.
For information about how to configure SSL encryption for an ApsaraDB RDS for PostgreSQL instance, see SSL encryption.
Destination Database
Select Existing Connection
If you use a database instance that is registered with DTS, select the instance from the drop-down list. DTS automatically populates the following database parameters for the instance. For more information, see Manage database connections.
NoteIn the DMS console, you can select the database instance from the Select a DMS database instance drop-down list.
If you fail to register the instance with DTS, or you do not need to use the instance that is registered with DTS, you must configure the following database information.
Database Type
Select AnalyticDB for PostgreSQL.
Access Method
Select Alibaba Cloud Instance.
Instance Region
Select the region where the destination AnalyticDB for PostgreSQL instance resides.
Instance ID
Select the ID of the destination AnalyticDB for PostgreSQL instance.
Database Name
Enter the name of the database in the destination AnalyticDB for PostgreSQL instance to which the migration objects belong.
Database Account
Enter the database account of the destination AnalyticDB for PostgreSQL instance. For information about the required permissions, see Permissions required for database accounts.
Database Password
The password that is used to access the database instance.
Click Test Connectivity and Proceed in the lower part of the page.
NoteMake sure that the CIDR blocks of DTS servers can be automatically or manually added to the security settings of the source and destination databases to allow access from DTS servers. For more information, see Add DTS server IP addresses to a whitelist.
If the source or destination database is a self-managed database and its Access Method is not set to Alibaba Cloud Instance, click Test Connectivity in the CIDR Blocks of DTS Servers dialog box.
Configure the objects to be migrated.
Configure the objects to be migrated.
Configuration
Description
Migration Types
To perform only full data migration, select Schema Migration and Full Data Migration.
To ensure service continuity during data migration, select Schema Migration, Full Data Migration, and Incremental Data Migration.
NoteIf you do not select Schema Migration, make sure a database and a table are created in the destination database to receive data and the object name mapping feature is enabled in Selected Objects.
If you do not select Incremental Data Migration, we recommend that you do not write data to the source database during data migration. This ensures data consistency between the source and destination databases.
Processing Mode of Conflicting Tables
Precheck and Report Errors: checks whether the destination database contains tables that use the same names as tables in the source database. If the source and destination databases do not contain tables that have identical table names, the precheck is passed. Otherwise, an error is returned during the precheck and the data migration task cannot be started.
NoteIf the source and destination databases contain tables with identical names and the tables in the destination database cannot be deleted or renamed, you can use the object name mapping feature to rename the tables that are migrated to the destination database. For more information, see Map object names.
Ignore Errors and Proceed: skips the precheck for identical table names in the source and destination databases.
WarningIf you select Ignore Errors and Proceed, data inconsistency may occur and your business may be exposed to the following potential risks:
If the source and destination databases have the same schema, and a data record has the same primary key as an existing data record in the destination database, the following scenarios may occur:
During full data migration, DTS does not migrate the data record to the destination database. The existing data record in the destination database is retained.
During incremental data migration, DTS migrates the data record to the destination database. The existing data record in the destination database is overwritten.
If the source and destination databases have different schemas, only specific columns are migrated or the data migration task fails. Proceed with caution.
DDL and DML Operations to Be Synchronized
Select the SQL operations for incremental migration at the instance level. For information about the supported operations, see SQL operations that support incremental migration.
NoteTo select SQL operations for incremental migration at the database or table level, right-click a migration object in the Selected Objects section and select the required SQL operations in the pop-up dialog box.
Storage Engine Type
The storage engine type of the destination table. Default value: Beam. Specify this parameter based on your business requirements.
NoteThis parameter is available only the minor version of the destination AnalyticDB for PostgreSQL instance is v7.0.6.6 or later and you specify Schema Migration for the Migration Types parameter.
Capitalization of Object Names in Destination Instance
The capitalization of database names, table names, and column names in the destination instance. By default, DTS default policy is selected. You can select other options to make sure that the capitalization of object names is consistent with that of the source or destination database. For more information, see Specify the capitalization of object names in the destination instance.
Source Objects
Select one or more objects from the Source Objects section. Click the
 icon to add the objects to the Selected Objects section. Note
icon to add the objects to the Selected Objects section. NoteYou can select columns, tables, or schemas as the objects to be migrated. If you select tables or columns as the objects to be migrated, DTS does not migrate other objects, such as views, triggers, or stored procedures, to the destination database.
Selected Objects
To rename an object that you want to migrate to the destination instance, right-click the object in the Selected Objects section. For more information, see Map the name of a single object.
To rename multiple objects at a time, click Batch Edit in the upper-right corner of the Selected Objects section. For more information, see Map multiple object names at a time.
NoteIf you use the object name mapping feature, other objects that depend on the renamed object may fail to be migrated.
To set a WHERE condition to filter data, right-click the table to be migrated in the Selected Objects box and set the filter condition in the dialog box that appears. For more information, see Set filter conditions.
To select SQL operations for migration at the database or table level, right-click the object to be migrated in the Selected Objects box, and in the dialog box that appears, select the desired SQL operations.
Click Next: Advanced Settings to configure advanced settings.
Configuration
Description
Dedicated Cluster for Task Scheduling
By default, DTS schedules the data migration task to the shared cluster if you do not specify a dedicated cluster. If you want to improve the stability of data migration tasks, purchase a dedicated cluster. For more information, see What is a DTS dedicated cluster.
Retry Time for Failed Connections
The retry time range for failed connections. If the source or destination database fails to be connected after the data migration task is started, DTS immediately retries a connection within the retry time range. Valid values: 10 to 1,440. Unit: minutes. Default value: 720. We recommend that you set the parameter to a value greater than 30. If DTS is reconnected to the source and destination databases within the specified retry time range, DTS resumes the data migration task. Otherwise, the data migration task fails.
NoteIf you specify different retry time ranges for multiple data migration tasks that share the same source or destination database, the value that is specified later takes precedence.
When DTS retries a connection, you are charged for the DTS instance. We recommend that you specify the retry time range based on your business requirements. You can also release the DTS instance at the earliest opportunity after the source database and destination instance are released.
Retry Time for Other Issues
The retry time range for other issues. For example, if DDL or DML operations fail to be performed after the data migration task is started, DTS immediately retries the operations within the retry time range. Valid values: 1 to 1440. Unit: minutes. Default value: 10. We recommend that you set the parameter to a value greater than 10. If the failed operations are successfully performed within the specified retry time range, DTS resumes the data migration task. Otherwise, the data migration task fails.
ImportantThe value of the Retry Time for Other Issues parameter must be smaller than the value of the Retry Time for Failed Connections parameter.
Enable Throttling for Full Data Migration
Specifies whether to enable throttling for full data migration. During full data migration, DTS uses the read and write resources of the source and destination databases. This may increase the loads of the database servers. You can enable throttling for full data migration based on your business requirements. To configure throttling, you must configure the Queries per second (QPS) to the source database, RPS of Full Data Migration, and Data migration speed for full migration (MB/s) parameters. This reduces the loads of the destination database server.
NoteYou can configure this parameter only if you select Full Data Migration for the Migration Types parameter.
Enable Throttling for Incremental Data Migration
Specifies whether to enable throttling for incremental data migration. To configure throttling, you must configure the RPS of Incremental Data Migration and Data migration speed for incremental migration (MB/s) parameters. This reduces the loads of the destination database server.
NoteYou can configure this parameter only if you select Incremental Data Migration for the Migration Types parameter.
Environment Tag
You can select an environment tag to identify the instance if needed. This setting is optional.
Configure ETL
Specifies whether to enable the extract, transform, and load (ETL) feature. For more information, see What is ETL? Valid values:
Yes: configures the ETL feature. You can enter data processing statements in the code editor. For more information, see Configure ETL in a data migration or data synchronization task.
No: does not configure the ETL feature.
Monitoring and Alerting
Specifies whether to configure alerting for the data migration task. If the task fails or the migration latency exceeds the specified threshold, the alert contacts receive notifications. Valid values:
No: does not configure alerting.
Yes: configures alerting. In this case, you must also configure the alert threshold and alert notification settings. For more information, see the Configure monitoring and alerting when you create a DTS task section of the Configure monitoring and alerting topic.
Click Next Step: Data Verification to configure the data verification task.
For more information about how to use the data verification feature, see Configure a data verification task.
After you complete the preceding configurations, click Next: Configure Database and Table Fields at the bottom of the page. On the next page, configure the primary key and distribution columns for the migrated tables in the destination AnalyticDB for PostgreSQL instance.
NoteThis page is displayed only when Migration Types is set to Schema Migration. For more information about primary key columns and distribution columns, see Data Table Management and Table Distribution Definition.
Save the task settings and run a precheck.
To view the parameters to be specified when you call the relevant API operation to configure the DTS task, move the pointer over Next: Save Task Settings and Precheck and click Preview OpenAPI parameters.
If you do not need to view or have viewed the parameters, click Next: Save Task Settings and Precheck in the lower part of the page.
NoteBefore you can start the data migration task, DTS performs a precheck. You can start the data migration task only after the task passes the precheck.
If the task fails to pass the precheck, click View Details next to each failed item. After you analyze the causes based on the check results, troubleshoot the issues. Then, run a precheck again.
If an alert is triggered for an item during the precheck:
If an alert item cannot be ignored, click View Details next to the failed item and troubleshoot the issues. Then, run a precheck again.
If the alert item can be ignored, click Confirm Alert Details. In the View Details dialog box, click Ignore. In the message that appears, click OK. Then, click Precheck Again to run a precheck again. If you ignore the alert item, data inconsistency may occur, and your business may be exposed to potential risks.
Purchase the instance.
Wait until Success Rate becomes 100%. Then, click Next: Purchase Instance.
On the Purchase Instance page, configure the Instance Class parameter for the data migration instance. The following table describes the parameters.
Section
Parameter
Description
New Instance Class
Resource Group
The resource group to which the data migration instance belongs. Default value: default resource group. For more information, see What is Resource Management?
Instance Class
DTS provides instance classes that vary in the migration speed. You can select an instance class based on your business scenario. For more information, see Instance classes of data migration instances.
Read and agree to Data Transmission Service (Pay-as-you-go) Service Terms by selecting the check box.
Click Buy and Start. In the message that appears, click OK.
You can view the progress of the task on the Data Migration page.
NoteIf a data migration task cannot be used to migrate incremental data, the task automatically stops. The Completed is displayed in the Status section.
If a data migration task can be used to migrate incremental data, the task does not automatically stop. The incremental data migration task never stops or completes. The Running is displayed in the Status section.