Time properties are the core scheduling conditions that define when and how DataWorks triggers a scheduled task. These properties include the scheduled time, along with advanced configurations such as instance generation mode, scheduling calendar, rerun settings, and timeout policies. Together, these parameters control a task's trigger rules, execution boundaries, and automatic recovery from errors. This guide explains how to configure these time properties to build stable and reliable automated data workflows.
Quick start: Configuration example
Scenario: An e-commerce company needs to automatically calculate the previous day's total sales at 02:00 every day. If the task fails due to factors such as network fluctuations, the system should automatically retry it 3 times.
Step 1: Set the scheduled time
Set the scheduling cycle: Double-click the task name. In the section on the right, set Scheduling Cycle to Day.
Set the scheduled time: Set the scheduled time to 02:00.
Step 2: Set the scheduling policy
Define rerun properties: Set Rerun to Allow Regardless of Running Status.
Auto rerun upon failure: Select Auto Rerun upon Failure, set Retries to
3, and set Interval to5 minutes.Keep the default values for the other properties.
Result:
After you deploy the task, the system automatically triggers it at 02:00 every day, starting from the next day (T+1). If the task fails, the system retries it every 5 minutes. The task runs a maximum of 4 times (1 normal run + 3 retries).
Function introduction
Time property configurations define the entire process of a scheduled task, from generation to execution. They include the following core dimensions:
Scheduling time: Defines the scheduling frequency and specific time for task execution.
Instance lifecycle management: Determines when an instance is created and its validity period. It includes:
Instance generation mode: Controls whether an instance is generated on the
deployment day or the following day.
Effective period: Sets the overall valid time range for the task.
Scheduling calendar: Excludes non-working days, such as public holidays.
Execution policy: Defines the behavior of an instance at its scheduled time, such as a normal run, a dry-run (skip), or a pause.
Exception and fault tolerance: Provides automated handling for exceptions, such as task failures or timeouts, through timeout definitions and rerun settings.

Scheduling time
The scheduling time controls the planned execution time of a task (also called the scheduled time). It determines how often a task node should be automatically triggered in the production environment. The system generates a corresponding number of recurring instances for the task based on the cycle you set. It then uses the scheduled times and scheduling dependencies of these instances to manage the automated execution of the entire workflow.
Scheduled time and business date are the two most important baseline time
concepts in DataWorks. For more information, see Core concepts: Time baselines.
Independence and dependencies of scheduling cycles
Independent frequency: The scheduling frequency of a task, such as hourly or daily, is determined by its own configuration and is independent of the frequencies of its upstream tasks. For example, a daily report task can depend on an hourly data preparation task. For more information about configuring dependencies with different cycle frequencies, see Best practices: Principles and examples of scheduling configurations for complex dependencies.
Instance dependency: Dependencies between tasks with different scheduling cycles (cross-cycle dependencies) are essentially instance dependencies. The system automatically resolves them to ensure that a downstream instance runs only after all its corresponding upstream instances for the same business date are successful.
Dry-run mechanism: To avoid blocking downstream tasks, a non-daily task (such as weekly, monthly, or yearly) generates a dry-run instance on its non-run days. This instance is immediately set to a successful state without executing code or consuming resources. This ensures that downstream daily tasks can be triggered normally.
Scheduled time vs. actual running time
Scheduled time: The time you set in the scheduling configuration is the task's expected start time. This is the earliest time the task can begin to run.
Actual running time: The actual start time of a task depends on two conditions being met simultaneously:
All upstream instances have run successfully.
Computing resources are available.
Scheduling time zone
A task's scheduled time uses the time zone of its workspace region by default. To handle scenarios such as daylight saving time changes, you can change the scheduling time zone. For more information, see Switch scheduling time zones and Scenario: Impact of daylight saving time changes on scheduled tasks.
The following sections provide configuration examples for various scenarios:
Minute scheduling
Set a start and end time and a run interval. The minimum interval is 1 minute. Within the specified time period, the system generates multiple instances at a fixed interval.
Configuration example
The target node is scheduled once every 30 minutes within the time period from 00:00 to 23:59 every day. The following figure shows the configuration details.
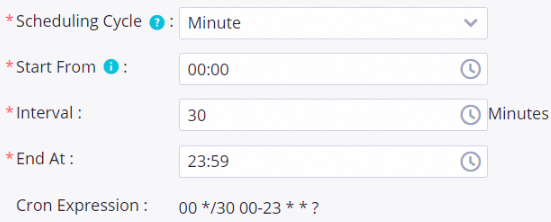
Instance details
The following figure shows the scheduled times and scheduling parameter replacements for a node that is scheduled every 30 minutes.

Hour scheduling
This is suitable for high-frequency synchronization or near-real-time computing scenarios.
Instance generation logic: The system calculates recurring instances based on the closed interval [Start Time, End Time].
Example: If the time range is set to
[00:00, 03:00]with an interval of1 hour, the system generates four instances. Their planned execution times are exactly at 00:00, 01:00, 02:00, and 03:00.
Configuration methods:
Frequency-based trigger: The task runs in a loop at a fixed interval (such as every hour) within a specified time period.
Point-in-time trigger: Directly specify one or more discrete, precise time points for the task to run.
Configuration example
The target task is automatically scheduled once every 6 hours within the time period from 00:00 to 23:59 every day. The following figure shows the configuration details.
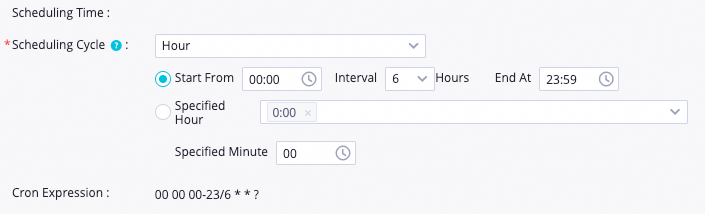
Scheduling details
The scheduling system generates four instances every day and runs them at their scheduled times of 00:00, 06:00, 12:00, and 18:00, as shown in the following figure.

Day scheduling
Day scheduling is the most common scheduling method. It lets you run a task once a day at a specified time within a specified effective period. When you create a task, it is set to day scheduling by default, with a scheduled time randomly generated between 00:00 and 00:30. You can specify a different run time as needed. For example, you can specify the task to run once at 13:00 every day.
Configuration example
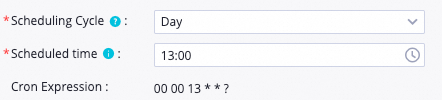
Scheduling details
The scheduling system automatically generates and runs instances for the task. The following figure shows the data transformation times for each business day.

Week scheduling
This is suitable for business summaries or periodic data maintenance that occurs at a fixed weekly frequency.
Instance generation logic: The system generates an instance every day within the effective period.
Normal execution: The code logic is triggered on schedule only on the run days you select (such as Monday and Friday).
Automatic dry-run: Instances generated on unselected days (such as Tuesday, Wednesday, Thursday, Saturday, and Sunday) are automatically set to a successful dry-run state. They do not actually run any logic or consume computing resources.
Configuration example
If the target task is configured to run on a schedule every Monday and Friday, the instances generated on Mondays and Fridays will be scheduled and run normally. The instances generated on Tuesdays, Wednesdays, Thursdays, Saturdays, and Sundays will be dry-run. This means that when their scheduled run time is reached, their status will be set directly to successful without running any code logic. The following figure shows the configuration details.
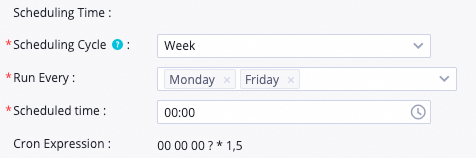
Scheduling details
The scheduling system automatically generates and runs instances for the task.

Month scheduling
This is suitable for data processing scenarios based on calendar months. It is a common cycle for core tasks such as financial settlements, monthly performance reports, and monthly analysis of user behavior.
Instance generation logic: The system generates instances based on the specific days of the month you select. A month scheduling instance represents a full calendar month.
Normal execution: The code logic is triggered on schedule only on the run days you select (such as the 15th or the last day of the month).
Automatic dry-run: Instances generated on unselected days (such as the 1st to the 14th of the month) are automatically set to a dry-run state. They do not actually run any logic or consume computing resources.
Configuration example
If the target task is configured to run a settlement on the last day of each month, the instance generated on the last day of the month will be scheduled and run normally. Instances generated on other days will be dry-run. This means that when their scheduled run time is reached, their status will be set directly to successful without running any code logic. The following figure shows the configuration details.
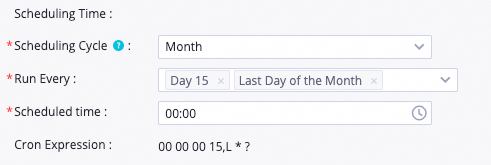
Scheduling details
The scheduling system automatically generates and runs instances for the task, as shown in the following figure.

When you use the data backfill feature to backfill data for a month scheduling task, note that the date you select for backfill is the business date, and business date = scheduled time - 1 day.
For example:
When backfilling data for a task that runs on the first of the month, select the end of the previous month as the data timestamp.
When backfilling data for a task that runs at the end of the month, select the day before the end of the month as the data timestamp.
If you select any other time as the data timestamp for backfill, the data backfill instance will be dry-run.
For more information about dependency scenarios, see Best practices: Principles and examples of scheduling configurations for complex dependencies.
Year scheduling
This is suitable for long-cycle data tasks such as quarterly summaries, annual audits, or tasks for specific holidays.
Instance generation logic: An instance is generated every day of the year, but the actual computation is triggered only on the specified months and dates.
Flexible combinations: Supports selecting multiple dates across different months, such as running only on the first or last day of each quarter.
Dry-run mechanism: On dates that do not meet the execution conditions, the instance is dry-run in seconds. It does not actually run any logic or consume computing resources.
Configuration example
If the target task is configured to run on the 1st and last day of January, April, July, and October each year, the instances generated on these specified dates will be scheduled and run normally. Instances generated on other dates will be dry-run. This means that when their scheduled run time is reached, their status will be set directly to successful without running any code logic. The following figure shows the configuration details.
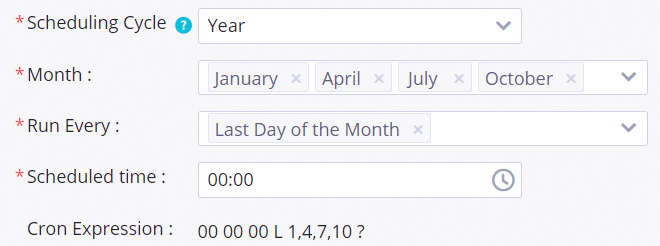
Scheduling details
The scheduling system automatically generates and runs instances for the task, as shown in the following figure.

The cron expression is automatically generated based on your time selection and cannot be manually modified.
Instance lifecycle management
These settings determine whether a task instance is created. They do not control the specific running time of a task. Instead, they manage at a higher level whether an instance should be created and whether the scheduling rule itself is active.
Instance generation mode: Determines whether your configuration changes take effect on the current day or the next day. Next-day activation (default) ensures that changes do not interfere with the current day's tasks, allowing for a smooth transition. Immediate activation forces a reset of the current day's instances to apply the changes. Use this option only for urgent fixes and after you understand and assess the risks of the changes.
Effective period: Defines the validity period for the entire set of scheduling rules.
Scheduling calendar: Allows you to bind the scheduling to a specific calendar, such as running only on "trading days". This is a more flexible control method than "week" scheduling.
Instance generation mode
After you deploy a node to the production environment's scheduling system, the platform generates automatically scheduled instances based on the node's configured Instance Generation Mode. This can be Next Day or Immediately After Deployment. Regardless of which mode you use, you can view the task's latest dependency status on the scheduled tasks page in Operation Center. However, when the recurring instance takes effect or when the dependencies are updated depends on the instance generation mode you choose.
To ensure that an instance generated immediately after deployment is scheduled normally and does not result in an "expired dry-run", make sure that the task's scheduled time is at least 10 minutes after the task deployment time. The task runs its code logic or regenerates instances based on the new configuration at the first scheduled time that occurs at least 10 minutes after you deploy the task.
Regardless of which instance generation mode you choose, changes made during the
23:30–24:00period will take effect on the third day after the node is deployed to the production environment. Avoid making task changes during this time period.
Instance Creation Method | Description |
Next Day |
|
The node generates an instance for the current day immediately after deployment. The generated instance is triggered normally only if its scheduled time is at least 10 minutes after the deployment time. If the scheduled time is earlier than this threshold (including past times and times within the buffer period), the instance is automatically set to a dry-run state. This means it is set to successful without actually running any code.
|
Effective date
Defines the valid time range for automatic task scheduling. After a task's effective period expires, it no longer generates instances and becomes an expired task. You can monitor and manage expired tasks on the O&M Dashboard.
Scheduling calendar
To define the scheduling properties of a task, you can use the following two types of calendars in DataWorks:
Default Calendar: the calendar that is provided by DataWorks and is suitable for common scenarios.
Custom scheduling calendar: You can define a custom calendar that is suitable for industries and scenarios with flexible scheduling date requirements (such as the finance industry). You can configure rules for the workspaces to which the calendar applies, the validity period of the calendar, and the scheduling method for tasks on specified dates. For more information, see Configure a scheduling calendar.
You must schedule the task at the specified time based on the selected scheduling calendar, in combination with other scheduling configurations such as scheduling type and scheduling time.
Execution policy
This configuration defines how a task should be executed after it is triggered.
Scheduling type
DataWorks supports the following scheduling types.
Scheduling Type | Impacts | Scenarios |
Normal | Runs the code and triggers downstream nodes. | A scheduled task running in the Normal state generates recurring instances that are also in the Normal state. |
Skip Execution | When the instance's scheduled time is reached, it does not run and its status changes to failed. This blocks downstream nodes. Pause scheduling is the same as freezing a node in Operation Center. A paused node displays the freeze icon | Suitable for urgently interrupting a business process. When a business process does not need to run for a certain period, you can select this scheduling type to freeze the root node of the business process. When the business needs to run, you can unfreeze the root node. For more information about unfreezing a task, see Freeze and unfreeze tasks. |
Dry Run | When the instance's scheduled time is reached, its status is immediately set to successful (running time is | Select this scheduling type when a node does not need to run for a certain period, and you do not want to block its downstream nodes from running. |
Exception and fault tolerance
This is a key part of ensuring the stability of the data link. It provides solutions for various possible exceptions.
Rerun properties: Determines whether and how the system should automatically retry a task when it fails.
Timeout settings: Sets a reasonable upper limit for a task's running time. If the time is exceeded, the system can automatically send an alert or interrupt the task to prevent a single abnormal node from getting stuck and consuming too many resources.
Timeout definition
You can set the maximum allowed running time for a task. If the running time exceeds this value, the task will be automatically terminated and set to a failed state. This prevents a task from getting stuck for a long time and affecting the entire workflow.
Scope: Applies to recurring instances, data backfill instances, and test instances.
Default value: The default is 3 to 7 days. The system dynamically adjusts the value based on the actual load.
Limits: The maximum value you can set manually is 168 hours (7 days), and the minimum is 1 minute.
Rerun instructions
Rerun policies are used to automatically recover failed tasks.
When using rerun properties, ensure the task's idempotence (except for special tasks) to avoid data quality issues after a task fails and is rerun. For example, when developing in ODPS SQL, use the
insert overwritestatement instead of theinsert intostatement.
Rerun property: Defines whether a task can be rerun.
Type
Scenario
Allow Regardless of Running Status
Suitable for idempotent tasks that can be re-executed without affecting the result.
Allow upon Failure Only
Prevents data contamination caused by accidentally rerunning a successful task.
Disallow Regardless of Running Status
Suitable for non-idempotent tasks (such as some data synchronization tasks). If you select this option, the Auto Rerun upon Failure feature will be unavailable.
Auto Rerun upon Failure: When a task fails, the system automatically triggers a rerun.
Parameter
Description
Number of re-runs
The number of automatic retries after a failure. Range: 1–10 times.
Rerun interval
The time interval between each retry. Range: 1–30 minutes.
NoteA failure caused by a timeout does not trigger an automatic rerun.
FAQ
Q: Why is my task's actual running time different from its scheduled time?
A: The scheduled time is only the task's "expected" start time. The actual run requires two conditions to be met: ① All upstream dependent tasks are successful. ② Scheduling resources are available. If either condition is not met, the task will remain in a waiting state.
Q: My upstream task runs hourly, and my downstream task runs daily. Can they depend on each other?
A: Yes, they can. DataWorks supports dependencies between tasks that have different scheduling cycles. The system uses a complex dependency parsing algorithm to ensure that a downstream task waits for all of its upstream instances to complete before it runs. For more information, see Scheduling configuration principles and examples for complex dependency scenarios.
Q: Why doesn't the bizdate variable show Friday's date after I backfilled data for last Friday?
A: This is usually because you confused the "business date" with the "running date". In DataWorks, the business date = scheduled time - 1 day. When you backfill data for a task scheduled to run in the early morning on Saturday, the business date you need to select is Friday.
Q: My task writes data. Will data be duplicated if it is rerun?
A: Yes, it might. Therefore, we strongly recommend ensuring that your task is idempotent. For data writing tasks, use
INSERT OVERWRITE(overwrite) instead ofINSERT INTO(append) to ensure that rerunning the task multiple times produces the same result.