This topic describes how ApsaraMQ for RocketMQ clients consume messages and why messages are accumulated. It also describes how to handle message accumulation and delay when you use the SDK for Java to send and receive messages over TCP. This helps you better plan resources and configure settings before business deployment. It also helps you adjust the business logic during O&M to prevent issues caused by message accumulation and delay.
Background information
If the message consumption rate on the client cannot keep up with the message production rate on the broker during message processing, accumulated messages are generated. This further causes delays in message consumption. We recommend that you take special note of message accumulation and delay in the following scenarios:
Messages are continuously accumulated because the consumption capability of the downstream system does not match the production capability of the upstream system. In addition, message consumption cannot be automatically recovered.
The business system has such high requirements on real-time message consumption that even delays caused by temporary message accumulation cannot be accepted.
How does a client consume messages?
The following figure shows how an ApsaraMQ for RocketMQ client consumes messages over TCP.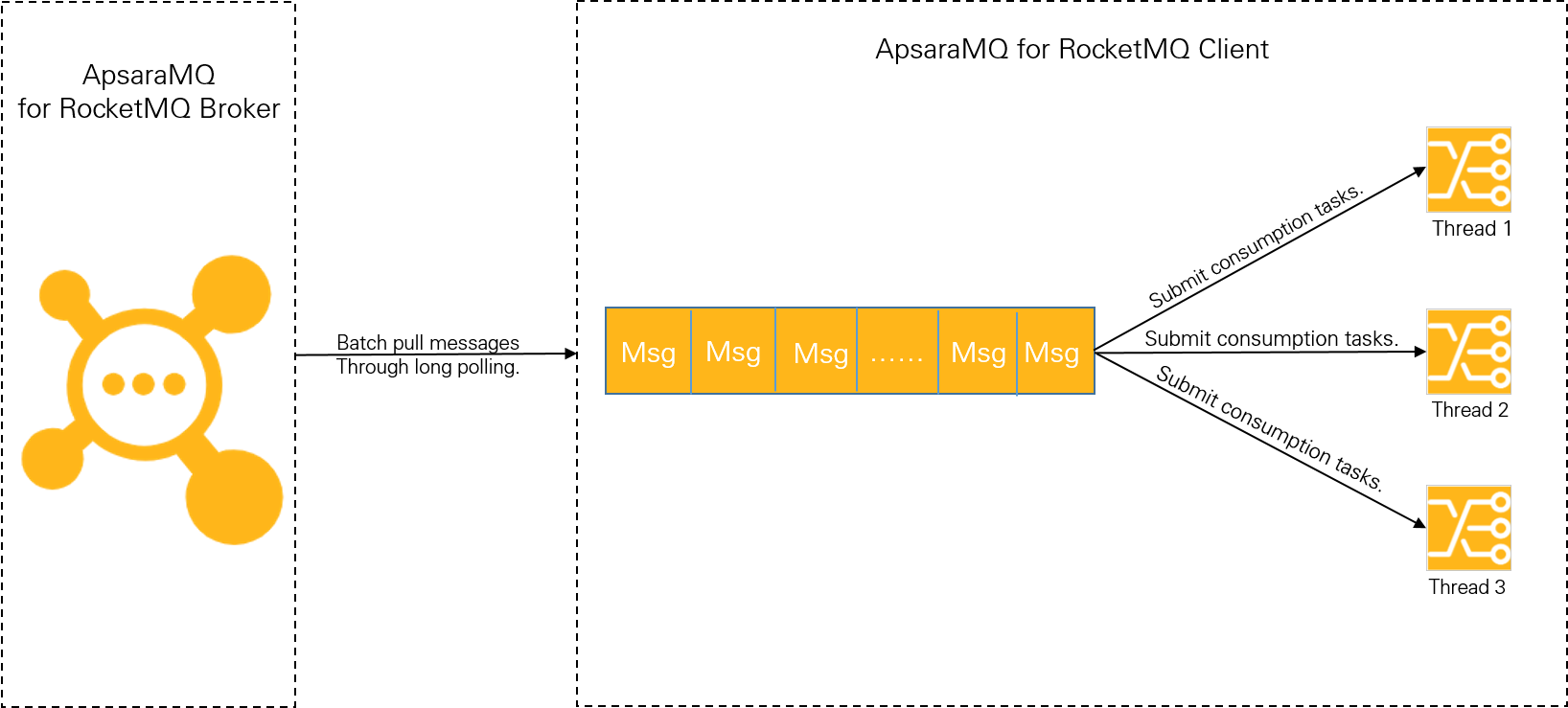
Using a client to consume messages in push mode comprises the following two phases:
Phase 1: Pull messages. The client pulls messages from the ApsaraMQ for RocketMQ broker in batches by using long polling. The pulled messages are then cached in the local buffer queue.
When messages are pulled in batches, high throughput can be achieved in typical internal networks. For example, the transactions per second (TPS) of a low-spec server (4 vCPUs and 8 GB memory) with a single thread and a single partition can be in the range of tens of thousands. For a server with multiple partitions, the TPS can reach hundreds of thousands. Therefore, a bottleneck in message accumulation cannot be caused in this phase.
Phase 2: Submit messages to the consumption thread. The client submits the locally cached messages to the consumption thread, then the thread uses the message consumption logic to process the messages.
The consumption capability of the client depends on the complexity (consumption duration) of the business logic and the consumption concurrency. If the business logic is complex and much time is needed to process a single message, the overall throughput cannot be high. When the number of messages stored in the local buffer queue reaches the upper limit, the client will stop pulling messages from the broker.
The preceding client-side consumption mechanism shows that bottlenecks in message accumulation are caused by the consumption capability of local clients, that is, the consumption duration and consumption concurrency. To prevent and resolve issues caused by message accumulation, you must properly configure the consumption duration and concurrency. Note that consumption duration takes priority over consumption concurrency.
Consumption duration
Factors affecting the consumption duration include CPUs, in-memory computing, and external I/O operations. In most cases, recursion and loops are not defined in the code. Therefore, the internal computing time is almost negligible compared with external I/O operations. External I/O operations typically include the following business logic:
Data reads and writes on external databases, such as MySQL databases.
Data reads and writes on external cache systems, such as Redis.
Downstream system calls, such as Dubbo calls and downstream HTTP interface calls.
You must sort out the logic and system capacity of such external calls to understand the expected time consumed by each call. This lets you determine whether the time consumed by the I/O operations in the consumption logic is reasonable. In most cases, messages are accumulated because the consumption duration is increased due to service exceptions or capacity limits in downstream systems.
For example, you specify a message consumption logic to write data to a database, and the consumption duration of each message is 1 millisecond. When the message volume is small, no exceptions occur. However, during sales promotions, the number of messages written to the databases per second greatly increases, and the capacity limit of the database is soon reached. As a result, the consumption duration of each message increases to 100 milliseconds, causing a sharp drop in the consumption rate. You cannot resolve this issue by simply changing the consumption concurrency of the ApsaraMQ for RocketMQ client. Instead, you must upgrade the database capacity.
Consumption concurrency
The following table describes the methods for calculating consumption concurrency in ApsaraMQ for RocketMQ.
Message type | Consumption concurrency |
Normal messages | Number of threads per node × Number of nodes |
Scheduled and delayed messages | |
Transactional messages | |
Ordered messages | Min (Number of threads per node × Number of nodes, Number of partitions) |
The consumption concurrency of a client is determined by the number of threads per node and the number of nodes. In most cases, you must first adjust the number of threads on a single node. If your hardware resources on the node have reached the upper limit, you must add nodes to increase the consumption concurrency.
The consumption concurrency of ordered messages is also limited by the number of partitions in a topic. To evaluate the number of partitions, contact Alibaba Cloud Customer Services.
When setting the consumption concurrency on a single node, an excessively large number of threads may lead to large overheads of thread switching. Use the following model to calculate the optimal number of threads on a single node in an ideal environment:
The number of vCPUs of a single node is C.
The time consumed for thread switching is ignored, and I/O operations do not consume CPU resources.
The thread has enough messages waiting for processing, and the memory is sufficient.
In the logic, the CPU time is T1, and the external I/O operation time is T2.
A single thread can achieve a TPS of 1/(T1 + T2). If the CPU utilization reaches the desired value 100%, you must set C × (T1 + T2)/T1 threads to make the single node reach its maximum consumption capability.
The maximum number of threads in this example is only the theoretical data obtained under the ideal environment. In the actual application environment, we recommend that you gradually increase the number of threads, observe the effects, then make adjustments.
How can I prevent message accumulation and delay?
To prevent unexpected message accumulation and delay, check and sort out the business logic in the early stage of design. Sort out the performance baseline for normal business operations, so that you can quickly identify issues when faults occur. The main task is to sort out the consumption duration and concurrency.
Sort out the consumption duration
Obtain the consumption duration by performing stress tests and analyzing the code logic of time-consuming operations. For more information about how to query the consumption duration, see Query the consumption duration. Note the following when you sort out the consumption duration:
Check whether the computing complexity of the message consumption logic is excessively high and whether the code has defects, such as infinite loops and recursion.
Check whether I/O operations in the message consumption logic, such as external calls and read/write storage, are required. In addition, check whether solutions, such as local cache, can be used to avoid these operations.
Check whether complex and time-consuming operations in the message consumption logic can be asynchronously processed. If so, check whether they will result in confusing logic. For example, the consumption is completed, but the asynchronous operation is not.
Set the consumption concurrency
Gradually increase the number of threads on a single node. Then, observe the metrics of the node to obtain the optimal number of consumption threads and maximum throughput on the node.
After obtaining the optimal number of threads and throughput on a single node, calculate the number of required nodes. You can do this based on the peak traffic of the upstream and downstream systems, using the following formula: Number of nodes = Peak traffic/Throughput of a single thread.
How do I handle message accumulation and delay?
Configure message accumulation alerts.
Set alert rules by using the monitoring and alerting feature provided by ApsaraMQ for RocketMQ to monitor and handle message accumulation. For more information about how to set alert rules, see Configure message accumulation alerts.
Handle accumulated messages.
For information about how to handle accumulated messages, see How do I handle accumulated messages?