This topic describes how to create an AnalyticDB sink connector to export data from a data source topic of a ApsaraMQ for Kafka instance to an AnalyticDB for MySQL or AnalyticDB for PostgreSQL database by using Alibaba Cloud Function Compute.
Prerequisites
The following requirements must be met:
ApsaraMQ for Kafka
The connector feature is enabled for the ApsaraMQ for Kafka instance. For more information, see Enable the connector feature.
A data source topic is created in the ApsaraMQ for Kafka instance. For more information, see Step 1: Create a topic.
Function Compute
Function Compute is activated. For more information, see Activate Function Compute.
AnalyticDB for MySQL and AnalyticDB for PostgreSQL
If you want to export data to an AnalyticDB for MySQL database, make sure that you have created a cluster and a database account, connected to the cluster, and created a database in the cluster in the AnalyticDB for MySQL console. For more information, see Create a cluster, Create a database account, Connect to an AnalyticDB for MySQL cluster, and Create a database.
If you want to export data to an AnalyticDB for PostgreSQL database, make sure that you have created an instance and a database account and connected to the database in the AnalyticDB for PostgreSQL console. For more information, see Create an instance, Create a database account, and Client connection.
Usage notes
You can only export data from a data source topic of a ApsaraMQ for Kafka instance to an AnalyticDB for MySQL or AnalyticDB for PostgreSQL database through Function Compute within the same region. For information about the limits on connectors, see Limits.
AnalyticDB sink connectors export data by using Function Compute. Function Compute provides a free quota of resources for you. If your usage exceeds this free quota, you are charged for the excess based on the billing rules of Function Compute. For more information, see Billing overview.
Function Compute allows you to query the logs of function calls to troubleshoot issues. For more information, see Configure logging.
ApsaraMQ for Kafka serializes messages into UTF-8-encoded strings for transfer. Message Queue for Apache Kafka does not support binary data.
If you specify a private endpoint of the destination database for the AnalyticDB sink connector, you must specify the same virtual private cloud (VPC ) and vSwitch as those of the destination database for the corresponding function in the Function Compute console. Otherwise, Function Compute cannot access the destination database. For more information, see Update a service.
When you create a connector, ApsaraMQ for Kafka creates a service-linked role for you.
If no service-linked role is available, ApsaraMQ for Kafka automatically creates a service-linked role for you to use an AnalyticDB sink connector to export data from ApsaraMQ for Kafka to AnalyticDB for MySQL or AnalyticDB for PostgreSQL.
If a service-linked role is available, ApsaraMQ for Kafka does not create a new one.
For more information about service-linked roles, see Service-linked roles.
Procedure
This section describes how to use an AnalyticDB sink connector to export data from a data source topic of a ApsaraMQ for Kafka instance to an AnalyticDB for MySQL or AnalyticDB for PostgreSQL database.
Optional: Create the topics and group that are required by an AnalyticDB sink connector.
If you do not want to manually create the topics and group, skip this step and set the Resource Creation Method parameter to Auto in the next step.
ImportantSpecific topics that are required by an AnalyticDB sink connector must use a local storage engine. If the major version of your ApsaraMQ for Kafka instance is 0.10.2, topics that use a local storage engine cannot be manually created. In this version, these topics must be automatically created.
Configure Function Compute and AnalyticDB for MySQL or AnalyticDB for PostgreSQL.
Verify the result.
Create the topics that are required by an AnalyticDB sink connector
In the ApsaraMQ for Kafka console, you can manually create the five topics that are required by an AnalyticDB sink connector. The five topics are the task offset topic, task configuration topic, task status topic, dead-letter queue topic, and error data topic. The five topics differ in storage engine and the number of partitions. For more information, see Parameters in the Configure Source Service step.
Log on to the ApsaraMQ for Kafka console.
In the Resource Distribution section of the Overview page, select the region where the ApsaraMQ for Kafka instance that you want to manage resides.
ImportantYou must create topics in the region where your Elastic Compute Service (ECS) instance is deployed. A topic cannot be used across regions. For example, if the producers and consumers of messages run on an ECS instance that is deployed in the China (Beijing) region, the topic must also be created in the China (Beijing) region.
On the Instances page, click the name of the instance that you want to manage.
In the left-side navigation pane, click Topics.
On the Topics page, click Create Topic.
In the Create Topic panel, specify the properties of the topic and click OK.
Parameter
Description
Example
Name
The topic name.
demo
Description
The topic description.
demo test
Partitions
The number of partitions in the topic.
12
Storage Engine
NoteYou can specify the storage engine type only if you use a Professional Edition instance. If you use a Standard Edition instance, cloud storage is selected by default.
The type of the storage engine that is used to store messages in the topic.
ApsaraMQ for Kafka supports the following types of storage engines:
Cloud Storage: If you select this value, the system uses Alibaba Cloud disks for the topic and stores data in three replicas in distributed mode. This storage engine features low latency, high performance, long durability, and high reliability. If you set the Instance Edition parameter to Standard (High Write) when you created the instance, you can set this parameter only to Cloud Storage.
Local Storage: If you select this value, the system uses the in-sync replicas (ISR) algorithm of open source Apache Kafka and stores data in three replicas in distributed mode.
Cloud Storage
Message Type
The message type of the topic. Valid values:
Normal Message: By default, messages that have the same key are stored in the same partition in the order in which the messages are sent. If a broker in the cluster fails, the order of messages that are stored in the partitions may not be preserved. If you set the Storage Engine parameter to Cloud Storage, this parameter is automatically set to Normal Message.
Partitionally Ordered Message: By default, messages that have the same key are stored in the same partition in the order in which the messages are sent. If a broker in the cluster fails, messages are still stored in the partitions in the order in which the messages are sent. Messages in some partitions cannot be sent until the partitions are restored. If you set the Storage Engine parameter to Local Storage, this parameter is automatically set to Partitionally Ordered Message.
Normal Message
Log Cleanup Policy
The log cleanup policy that is used by the topic.
If you set the Storage Engine parameter to Local Storage, you must configure the Log Cleanup Policy parameter. You can set the Storage Engine parameter to Local Storage only if you use an ApsaraMQ for Kafka Professional Edition instance.
ApsaraMQ for Kafka provides the following log cleanup policies:
Delete: the default log cleanup policy. If sufficient storage space is available in the system, messages are retained based on the maximum retention period. After the storage usage exceeds 85%, the system deletes the earliest stored messages to ensure service availability.
Compact: the log compaction policy that is used in Apache Kafka. Log compaction ensures that the latest values are retained for messages that have the same key. This policy is suitable for scenarios such as restoring a failed system or reloading the cache after a system restarts. For example, when you use Kafka Connect or Confluent Schema Registry, you must store the information about the system status and configurations in a log-compacted topic.
ImportantYou can use log-compacted topics only in specific cloud-native components, such as Kafka Connect and Confluent Schema Registry. For more information, see aliware-kafka-demos.
Compact
Tag
The tags that you want to attach to the topic.
demo
After a topic is created, you can view the topic on the Topics page.
Create the group that is required by an AnalyticDB sink connector
In the ApsaraMQ for Kafka console, you can manually create the group that is required by an AnalyticDB sink connector. The name of the group must be in the connect-Task name format. For more information, see Parameters in the Configure Source Service step.
Log on to the ApsaraMQ for Kafka console.
In the Resource Distribution section of the Overview page, select the region where the ApsaraMQ for Kafka instance that you want to manage resides.
On the Instances page, click the name of the instance that you want to manage.
In the left-side navigation pane, click Groups.
On the Groups page, click Create Group.
In the Create Group panel, enter a group name in the Group ID field and a group description in the Description field, attach tags to the group, and then click OK.
After a consumer group is created, you can view the consumer group on the Groups page.
Create and deploy an AnalyticDB sink connector
Log on to the ApsaraMQ for Kafka console.
In the Resource Distribution section of the Overview page, select the region where the ApsaraMQ for Kafka instance that you want to manage resides.
In the left-side navigation pane, click Connectors.
On the Connectors page, click Create Connector.
In the Create Connector wizard, perform the following steps:
In the Configure Basic Information step, set the parameters that are described in the following table and click Next.
Parameter
Description
Example
Name
The name of the connector. Take note of the following rules when you specify a connector name:
The connector name must be 1 to 48 characters in length. It can contain digits, lowercase letters, and hyphens (-), but cannot start with a hyphen (-).
Each connector name must be unique within a ApsaraMQ for Kafka instance.
The name of the group that is used by the connector task must be in the connect-Task name format. If you have not already created such a group, Message Queue for Apache Kafka automatically creates one for you.
kafka-adb-sink
Instance
The information about the Message Queue for Apache Kafka instance. By default, the name and ID of the instance are displayed.
demo alikafka_post-cn-st21p8vj****
In the Configure Source Service step, select Message Queue for Apache Kafka as the source service, set the parameters that are described in the following table, and then click Next.
Table 1. Parameters in the Configure Source Service step
Parameter
Description
Example
Data Source Topic
The name of the data source topic from which data is to be exported.
adb-test-input
Consumer Thread Concurrency
The number of concurrent consumer threads used to export data from the data source topic. Default value: 6. Valid values:
1
2
3
6
12
6
Consumer Offset
The offset where consumption starts. Valid values:
Earliest Offset: Consumption starts from the earliest offset.
Latest Offset: Consumption starts from the latest offset.
Earliest Offset
VPC ID
The ID of the VPC where the data export task runs. Click Configure Runtime Environment to display the parameter. The default value is the VPC ID that you specified when you deployed the ApsaraMQ for Kafka instance. You do not need to change the value.
vpc-bp1xpdnd3l***
vSwitch ID
The ID of the vSwitch where the data export task runs. Click Configure Runtime Environment to display the parameter. The vSwitch must be deployed in the same VPC as the ApsaraMQ for Kafka instance. The default value is the vSwitch ID that you specified when you deployed the ApsaraMQ for Kafka instance.
vsw-bp1d2jgg81***
Failure Handling Policy
Specifies whether to retain the subscription to the partition where an error causes a message send failure. Click Configure Runtime Environment to display the parameter. Valid values:
Continue Subscription: retains the subscription to the partition where an error occurs and returns the logs.
Stop Subscription: stops the subscription to the partition where an error occurs and returns the logs.
NoteFor information about how to view connector logs, see Manage a connector.
For more information about how to troubleshoot errors based on error codes, see Error codes.
Continue Subscription
Resource Creation Method
The method to create the topics and group that are required by the AnalyticDB sink connector. Click Configure Runtime Environment to display the parameter. Valid values:
Auto
Manual
Auto
Connector Consumer Group
The group that is used by the connector.Group Click Configure Runtime Environment to display the parameter. The name of the group must be in the connect-Task name format.
connect-kafka-adb-sink
Task Offset Topic
The topic that is used to store consumer offsets. Click Configure Runtime Environment to display the parameter.
Topic: We recommend that you start the topic name with connect-offset.
Partitions: The number of partitions in the topic must be greater than 1.
Storage Engine: The storage engine of the topic must be set to Local Storage.
cleanup.policy: The log cleanup policy for the topic must be set to Compact.
connect-offset-kafka-adb-sink
Task Configuration Topic
The topic that is used to store task configurations. Click Configure Runtime Environment to display the parameter.
Topic: We recommend that you start the topic name with connect-config.
Partitions: The topic can contain only one partition.
Storage Engine: The storage engine of the topic must be set to Local Storage.
cleanup.policy: The log cleanup policy for the topic must be set to Compact.
connect-config-kafka-adb-sink
Task Status Topic
The topic that is used to store task status. Click Configure Runtime Environment to display the parameter.
Topic: We recommend that you start the topic name with connect-status.
Partitions: We recommend that you set the number of partitions in the topic to 6.
Storage Engine: The storage engine of the topic must be set to Local Storage.
cleanup.policy: The log cleanup policy for the topic must be set to Compact.
connect-status-kafka-adb-sink
Dead-letter Queue Topic
The topic that is used to store the error data of the Kafka Connect framework. Click Configure Runtime Environment to display the parameter. To save topic resources, you can create a topic as both the dead-letter queue topic and the error data topic.
Topic: We recommend that you start the topic name with connect-error.
Partitions: We recommend that you set the number of partitions in the topic to 6.
Storage Engine: The storage engine of the topic can be set to Local Storage or Cloud Storage.
connect-error-kafka-adb-sink
Error Data Topic
The topic that is used to store the error data of the Sink connector. Click Configure Runtime Environment to display the parameter. To save topic resources, you can create a topic as both the dead-letter queue topic and the error data topic.
Topic: We recommend that you start the topic name with connect-error.
Partitions: We recommend that you set the number of partitions in the topic to 6.
Storage Engine: The storage engine of the topic can be set to Local Storage or Cloud Storage.
connect-error-kafka-adb-sink
In the Configure Destination Service step, select AnalyticDB as the destination service, set the parameters that are described in the following table, and then click Create.
Parameter
Description
Example
Instance Type
The type of the destination database instance. Valid values: AnalyticDB for MySQL and AnalyticDB for PostgreSQL.
AnalyticDB for MySQL
AnalyticDB Instance ID
The ID of the destination AnalyticDB for MySQL or AnalyticDB for PostgreSQL instance.
am-bp139yqk8u1ik****
Database Name
The name of the destination database.
adb_demo
Table Name
The name of the table within the destination database where the exported data is stored.
user
Database Username
The username that you use to log on to the destination database.
adbmysql
Database Password
The password that you use to log on to the destination database. The password is specified when you create the destination AnalyticDB for MySQL AnalyticDB for PostgreSQL instance. If you forget the password, you can reset it.
If you want to reset the password of an AnalyticDB for MySQL database account, perform the steps described in Reset the password of a privileged account.
If you want to reset the password of an AnalyticDB for PostgreSQL database account, log on to the AnalyticDB for PostgreSQL console and click the destination instance. In the left-side navigation pane, click Account Management, locate the database account for which you want to reset the password, and click Reset Password in the Actions column.
********
NoteThe username and password are passed to the functions in Function Compute as environment variables when ApsaraMQ for Kafka creates a data export task. After the task is created, ApsaraMQ for Kafka does not save the username or password.
After the connector is created, you can view it on the Connectors page.
Go to the Connectors page, find the connector that you created, and click Deploy in the Actions column.
Configure the related Function Compute service
After an AnalyticDB sink connector is created and deployed in the ApsaraMQ for Kafka console, Function Compute automatically creates a function service and a function for the connector. The function service is named in the kafka-service-<connector_name>-<Random string> format, and the function is named in the fc-adb-<Random string> format.
On the Connectors page, locate the connector for which you want to configure the Function Compute service and click Configure Function in the Actions column.
The page is redirected to the Function Compute console.
In the Function Compute console, find the automatically created service and configure a VPC and vSwitch for the service. For more information, see Update a service.
Configure AnalyticDB for MySQL or AnalyticDB for PostgreSQL
After the Function Compute service is deployed, you must add the CIDR block for the VPC that you specify in the Function Compute console to the whitelist for the destination AnalyticDB for MySQL or AnalyticDB for PostgreSQL instance. You can view the CIDR block on the vSwitch page of the VPC console. The CIDR block is in the row where the VPC and vSwitch of the Function Compute service reside.
You should log on to the AnalyticDB for MySQL console to set the whitelist for a cluster. For more information, see Configure an IP address whitelist.
You should log on to the AnalyticDB for PostgreSQL console to set the whitelist for a cluster. For more information, see Configure an IP address whitelist.
Send test messages
You can send messages to the data source topic of a ApsaraMQ for Kafka instance to check whether data in the topic can be exported to AnalyticDB for MySQL or AnalyticDB for PostgreSQL.
The value of the Message Content parameter must be in the JSON format and will be parsed to key-value pairs. The keys are the column names of the destination database table and the values are the data in the columns. Therefore, make sure that each key of the message content has a corresponding column name in the destination database table.ApsaraMQ for Kafka You can log on to the AnalyticDB for MySQL console or the AnalyticDB for PostgreSQL console and connect to the destination database to check the column names of the destination database table.
On the Connectors page, find the connector that you want to manage and click Test in the Actions column.
In the Send Message panel, configure the parameters to send a message for testing.
If you set the Sending Method parameter to Console, perform the following steps:
In the Message Key field, enter the message key. Example: demo.
In the Message Content field, enter the message content. Example: {"key": "test"}.
Configure the Send to Specified Partition parameter to specify whether to send the test message to a specific partition.
If you want to send the test message to a specific partition, click Yes and enter the partition ID in the Partition ID field. Example: 0. For information about how to query partition IDs, see View partition status.
If you do not want to send the test message to a specific partition, click No.
If you set the Sending Method parameter to Docker, run the Docker command in the Run the Docker container to produce a sample message section to send the test message.
If you set the Sending Method parameter to SDK, select an SDK for the required programming language or framework and an access method to send and subscribe to the test message.
Verify the data export result
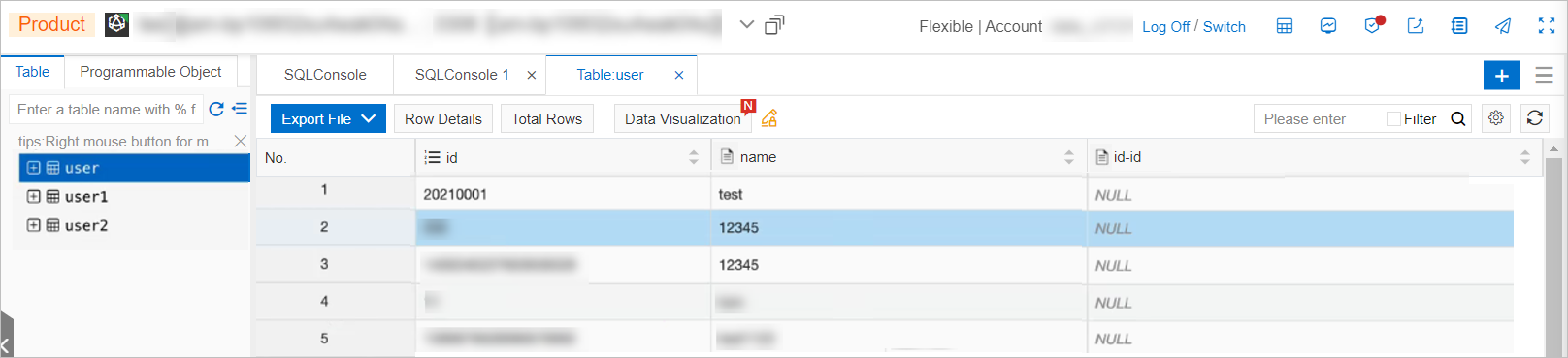
After you send messages to the data source topic of a ApsaraMQ for Kafka instance, log on to the AnalyticDB for MySQL console or the AnalyticDB for PostgreSQL console, and connect to the destination database.On the SQLConsole command window of the Data Management Service 5.0 console, click the destination table to check whether the data in the data source topic is exported successfully.
The following figure shows the result of a data export task from ApsaraMQ for Kafka to AnalyticDB for MySQL: