This topic describes how to use the AnalyticDB for MySQL import tool to import on-premises data to an AnalyticDB for MySQL cluster.
Overview
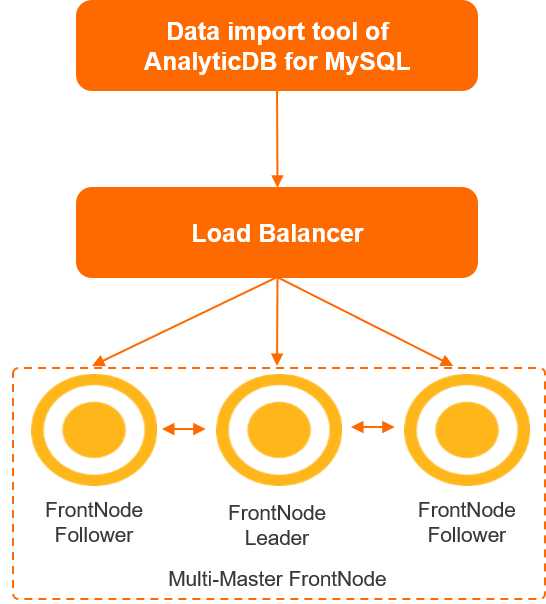
How the import tool works
The AnalyticDB for MySQL import tool connects to a Server Load Balancer (SLB) instance by using the Java Database Connectivity (JDBC) protocol. The SLB instance is attached to multiple front nodes that parse MySQL protocols and SQL statements, write data, and schedule queries. Data is transferred from the front nodes to storage nodes for import.
Benefits
Compared with the LOAD DATA statement, the AnalyticDB for MySQL import tool has the following benefits:
Allows you to configure parameters such as
batchSizeand concurrency to control the import speed and maximize the import throughput. For more information about the parameters, see the "Step 3. Prepare the script" section of this topic.Allows you to import a single file or import multiple files or folders at a time. If you use the LOAD DATA statement, you must initiate multiple processes to import multiple files in parallel.
Provides better performance by using technologies such as concurrency, batch processing, pooling, non-serial reads and writes, GC-less programming, sequential reads of large blocks. If the import tool is properly configured, the write throughput of an AnalyticDB for MySQL cluster can be maximized.
Procedure
Step | Description |
Download and decompress the AnalyticDB for MySQL import tool. | |
Prepare the data that you want to import. | |
Prepare the data import script by modifying the values of parameters in the import template. | |
Execute the import script to import on-premises data to an AnalyticDB for MySQL cluster. |
Step 1: Download and decompress the import tool
Run the following command to create a directory. In this example, a directory named /u01/loadata is created.
mkdir -p /u01/loadataRun the following command to go to the directory:
# cd /u01/loadataRun the following command to download the import tool:
wget https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20220811/gpvn/adb-import-tool.tar.gzRun the following command to decompress the import tool:
tar zxvf adb-import-tool.tar.gzThe following files are extracted from the compressed package:
adb-import.sh.template adb-import.sh.template.md5 adb-import-tool.jar adb-import-tool.jar.md5NoteYou can run the
java -versioncommand to check whether Java 1.8 or later is installed.
Step 2. Prepare the data to be imported
You can run the split command on Linux to split a large file into segments. A segment size of 1 to 2 GB is recommended. After you split the file, the segments can be concurrently read by the AnalyticDB for MySQL import tool, which improves the import speed.
In the following sample statement, a 128 GB file named filename.txt is split into 64 segments, each of which is 2 GB in size. The AnalyticDB for MySQL import tool reads the 64 files in a concurrent manner.
# split -l$((`wc -l < filename.txt`/64 + 1)) filename.txt filename.txt.split -da 2;Check the absolute path of the files or folders that you want to import.
Check the row delimiter and column delimiter of the files that you want to import. For more information about delimiters, see the "Step 3. Prepare the script" section of this topic.
Make sure that the columns of the files are in the same order as those defined in the CREATE TABLE statement. You can execute the SHOW CREATE TABLE statement in the database to check the column order. A file must contain at least two columns.
The following code block contains a sample statement that can be used to define the table schema:
CREATE TABLE `product_info` ( `id` bigint NOT NULL, `name` varchar, `price` decimal(15, 2) NOT NULL ) DISTRIBUTED BY HASH(`id`) INDEX_ALL='Y';A valid file may contain the following information:
1|tv|1000.0 2|computer|2000.0 3|cup|15.8Do not concern with unnecessary column delimiters that are contained in the last column of the file.
For example, both
1|abc|3.0and1|abc|3.0|are valid.NoteThe import tool treats empty strings as null by default. For example, if the file contains a
4||5.0row, null instead of the''string is added to thenamecolumn.The import tool can process auto-increment columns without the need to pre-process the file.
Step 3. Prepare the script
The adb-import.sh.template file is a template script whose name can be modified. For example, if the table that you want to import is named product_info, you can name the script adb-import-product_info.sh. You can create copies of the template script and modify the parameter values based on data import scenarios.
# Description of parameters in the script #
#-------------------------------- #
# The following parameters are required:
# -------------------------------- #
####################################
# The path of the Java command.
# Note: If you can run Java commands in the console, you do not need to specify this parameter.
####################################
java_cmd=java
####################################
# The absolute path of the JAR package of the import tool.
# If the tool is run in the same directory as the script, you do not need to specify this parameter.
####################################
jar_path=adb-import-tool.jar
####################################
# Configure database connection parameters.
# Note: Make sure that the database has been created in the AnalyticDB for MySQL cluster.
# If you set encryptPassword to true, you must specify a Base64-encrypted password.
####################################
host=host
port=3306
user=adbuser
password=pwd
database=dbname
encryptPassword=false
####################################
# The name of the table to be imported.
####################################
tableName=please_set_table_name
####################################
# The absolute path of the file or folder that you want to import. You can perform one of the following operations:
# 1. Import a single file or folder.
# or
# 2. Import multiple files whose paths are separated by commas (,).
####################################
dataPath=please_set_data_file_path_or_dir_path
####################################
# The number of files that are imported in a concurrent manner.
# Note: To fully leverage the performance of AnalyticDB for MySQL, we recommend that you set this parameter to a number within the range of 16 to 96.
####################################
concurrency=64
####################################
# The number of values that are written when the import operation is performed.
# Note: You must specify this parameter based on the lengths of individual rows. To fully leverage the performance of AnalyticDB for MySQL, we recommend that you set this parameter to a number within the range of 1024 to 4096.
####################################
batchSize=4096
####################################
# The encoding standard of the imported file. Valid values: UTF-8 and GBK.
####################################
encoding=UTF-8
####################################
# The row delimiter.
# Both printable characters such as \\n and non-printable characters are supported.
# If you want to use non-printable characters, you must specify them in hexadecimal notation.
* For example, \x0d\x06\x08\x0a must be specified as hex0d06080a.
####################################
lineSeparator="\\n"
####################################
# The column delimiter.
# Both printable characters such as \\| and non-printable characters are supported.
# If you want to use non-printable characters, you must specify them in hexadecimal notation.
* For example, \x07\x07 must be specified as hex0707.
####################################
delimiter="\\|"
# -------------------------------- #
# The following parameters are optional:
# -------------------------------- #
####################################
# The jvm parameters.
####################################
jvmopts="-Xmx12G -Xms12G"
####################################
# The number of files that are concurrently read when dataFile is set to a folder.
####################################
maxConcurrentNumOfFilesToImport=64
####################################
# Specifies whether to replace empty strings with two quotation marks (").
# If you set this parameter to false, empty strings are replaced with null. If you set this parameter to true, empty strings are replaced with the '' string.
# The default value is false. We recommend that you use this value.
####################################
nullAsQuotes=false
####################################
# Specifies whether to display the actual number of rows of the destination table each time a file is imported.
# Default value: false.
####################################
printRowCount=false
####################################
# The maximum length of the SQL statements that are displayed when they fail to be executed.
# Default value: 1000.
####################################
failureSqlPrintLengthLimit=1000
####################################
# Specifies whether to execute the INSERT statement. If you set this parameter to true, the INSERT statement is only displayed and not executed. If you set this parameter to false, the INSERT statement is executed.
# Default value: false.
####################################
disableInsertOnlyPrintSql=false
####################################
# Specifies whether to skip the table header. Default value: false.
####################################
skipHeader=false
####################################
# The size of the buffer pool when the INSERT statement is executed.
# This ensures that I/O and computing are separated when data is sent to AnalyticDB for MySQL to improve the performance of the client.
####################################
windowSize=128
####################################
# Specifies whether to escape the backslashes (\) and apostrophes (') in the columns. Default value: true.
# If you set this parameter to true, the performance of your client may be compromised when the strings are parsed.
# If you are sure that no backslashes (\) and apostrophes (') exist in the table, set this parameter to false.
####################################
escapeSlashAndSingleQuote=true
####################################
# Specifies whether to ignore the batches of data that failed to be imported.
####################################
ignoreErrors=false
####################################
# Specifies whether to display the SQL statements that failed to be executed.
####################################
printErrorSql=true
####################################
# Specifies whether to display the stack information when errors occur and printErrorSql is set to true.
####################################
printErrorStackTrace=trueStep 4. Execute the import script
Run the following command to import the script:
sh adb-import-product_info.sh;When the following log entry is returned, the script is executed.
[2021-03-13 17:50:24.730] add consumer consumer-01During the data import process, the import tool does not inform you of the progress. To query the import progress, run the following command to query the total number of rows in the destination table:
mysql > select count(*) from dbname.product_info;NoteWhen an error occurs during the data import process, the import tool immediately terminates the import operation and provides the details of the failed SQL statements. The data is incomplete in the destination table. You can execute the
TRUNCATE TABLE table_namestatement to clear the destination table and then perform the import operation again. You can also execute theDROP TABLE table_namestatement to delete the destination table and then create another table for import.After the import is complete, the following information is displayed: the number of rows read in each file, the amount of time it took to read each file, the total amount of time it took to complete the import, and whether all files are imported. If all files are imported,
all import finished successfullyis displayed. If not,all import finished with ERROR!is displayed. To verify the number of imported rows, query the database.
FAQ
Q: How do I know whether bottlenecks exist in the client or its server?
A: You can run the following commands to check whether bottlenecks exist in the client or its server. If bottlenecks exist, the workloads on the database during stress testing cannot be maximized.
Command
Description
top
Displays the CPU utilization.
free
Displays the memory usage.
vmstat 1 1000
Displays the overall system loads.
dstat -all --disk-util or iostat 1 1000
Displays the usage or read bandwidth of the disks.
jstat -gc <pid> 1000
Displays details about the Java garbage collection (GC) process of the import tool. If GC is frequently performed, you can set the
jvmoptsparameter to a larger value such as-Xmx16G -Xms16G.Q: How do I import multiple tables by using a single script?
A: If the row delimiter and column delimiter of the imported files are the same, you can modify the
tableNameanddataPathparameter values to import multiple tables by using a single script.For example, the tableName and dataPath parameters can be set to the following values:
tableName=$1 dataPath=$2Run the following commands to import the files:
# sh adb-import.sh table_name001 /path/table_001 # sh adb-import.sh table_name002 /path/table_002 # sh adb-import.sh table_name003 /path/table_003Q: How do I run the import tool in the background?
A: You can run the following command to run the import tool in the background:
# nohup sh adb-import.sh &After the import tool is started, you can run the following command to check the logs. If error information is returned, troubleshoot based on the returned information.
# tail -f nohup.outYou can also run the following command to check whether the import process is being executed normally:
# ps -ef|grep importQ: How do I ignore the errors when the import is in progress?
A: Errors may occur due to the following reasons:
SQL statements fail to be executed.
You can ignore the errors by setting the
ignoreErrorsparameter to true. The following information is included in the execution results: the files where errors occurred, the start row number, and the failed statements. If thebatchSizeparameter is specified, the faulty row number is less than or equal to the start row number plus thebatchSizevalue.The number of columns in a file does not match the expected number.
When the number of columns in a file does not match the expected number, the import tool immediately stops importing the current file and returns the error information. However, this error is not ignored because the error is caused by an invalid file, and you must manually check the validity of the file. In this case, an error message similar to the following one is returned:
[ERROR] 2021-03-22 00:46:40,444 [producer- /test2/data/lineitem.csv.split00.100-41] analyticdb.tool.ImportTool (ImportTool.java:591) -bad line found and stop import! 16, file = /test2/data/tpch100g/lineitem.csv.split00.100, rowCount = 7, current row = 3|123|179698|145|73200.15|0.06|0.00|R|F|1994-02-02|1994-01-04|1994-02- 23|NONE|AIR|ongside of the furiously brave acco|
Q: How do I narrow down the cause of an import error?
A: You can use the following methods to narrow down the cause of an import error:
When the import fails, the AnalyticDB for MySQL import tool returns the error log and the detailed error cause. A maximum of 1,000 characters of SQL statements can be returned. If you need to extend the limit, you can run the following commands and set the
failureSqlPrintLengthLimitparameter to a larger value such as 1500:printErrorSql=true failureSqlPrintLengthLimit=1500;Thousands of SQL statements may be concurrently executed based on the
batchSizevalue, which makes it difficult to identify the faulty rows. To facilitate troubleshooting, you can set thebatchSizeparameter to a smaller value such as 10, as shown in the following example:batchSize=10;If the file is split and the segment that contains the faulty rows is identified, you can specify the
dataPathparameter to import the segment that contains the faulty rows, as shown in the following example:dataPath=/u01/this/is/the/directory/where/product_info/stores/file007;
Q: How do I run the import tool in the Windows operating system?
A: The batch script is not provided on Windows. You can call a JAR file to execute the import script by using the following method:
usage: java -jar adb-import-tool.jar [-a <arg>] [-b <arg>] [-B <arg>] [-c <arg>] [-D <arg>] [-d <arg>] [-E <arg>] [-f <arg>] [-h <arg>] [-I <arg>] [-k <arg>] [-l <arg>] [-m <arg>] [-n <arg>] [-N <arg>] [-O <arg>] [-o <arg>] [-p <arg>] [-P <arg>] [-Q <arg>] [-s <arg>] [-S <arg>] [-t <arg>] [-T <arg>] [-u <arg>] [-w <arg>][-x <arg>] [-y <arg>] [-z <arg>]Parameter
Required
Description
-h,--ip <arg>Yes
The endpoint of the AnalyticDB for MySQL cluster.
-u,--username <arg>The database account of the AnalyticDB for MySQL cluster.
-p,--password <arg>The password corresponding to the database account of the AnalyticDB for MySQL cluster.
-P,--port <arg>The port number used to connect to the AnalyticDB for MySQL cluster.
-D,--databaseName <arg>The database name of the AnalyticDB for MySQL cluster.
-f,--dataFile <arg>The absolute path of the file or folder that you want to import. You can perform one of the following operations:
Import a single file or folder.
Import multiple files whose paths are separated by commas (,).
-t,--tableName <arg>The name of the table to be imported.
-a,--createEmptyFinishFilePath <arg>No
Specifies whether to generate a file to indicate that the import is complete. The default value of this parameter is an empty string, which indicates that no such file is generated. If you want to generate such a file, set this parameter to the file name. For example, if you set this parameter to
-a file_a, a file named-a file_ais generated.-b,--batchSize <arg>The number of values that are concurrently written in the
INSERT INTO tablename VALUES (..),(..)statement. Default value: 1.NoteTo strike a balance between import speed and system performance, we recommend that you set this parameter to a number within the range of 1024 to 4096.
-B,--encryptPassword <arg>Specifies whether to encrypt the password of the database account. Default value: false.
-c,--printRowCount <arg>Specifies whether to display the actual number of rows of the destination table each time a file is imported. Default value: false.
-d,--skipHeader <arg>Specifies whether to skip the table header. Default value: false.
-E,--escapeSlashAndSingleQuote <arg>Specifies whether to escape the backslashes (
\) and apostrophes (') in the columns. Default value: true.NoteIf you set this parameter to true, the performance of your client may be compromised when the strings are parsed. If you are sure that no backslashes (\) or apostrophes (') exist in the table, set this parameter to false.
-I,--ignoreErrors <arg>Specifies whether to ignore the batches of data that failed to be imported. Default value: false.
-k,--skipLineNum <arg>The number of skipped rows. The purpose of this parameter is similar to that of the
IGNORE number {LINES | ROWS}parameter. The default value of this parameter is 0, which indicates that no rows are skipped.-l,--delimiter <arg>The column delimiter. By default,
\\|is used as the column delimiter in AnalyticDB for MySQL. You can also use non-printable characters as column delimiters. If you want to use non-printable characters, you must specify them in hexadecimal notation. For example,\x07\x07must be specified ashex0707.-m,--maxConcurrentNumOfFilesToImport <arg>The number of files that are concurrently read when dataFile is set to a folder. The default value of this parameter is
Integer.MAX_VALUE, which indicates that all files are concurrently read.-n,--nullAsQuotes <arg>Specifies whether to replace
||with''. Default value: false. If you set this parameter to false,||is replaced with null instead of''.-N,--printErrorSql <arg>Specifies whether to display the SQL statements that fail to be executed. Default value: true.
-O,--connectionPoolSize <arg>The size of the AnalyticDB for MySQL database connection pool. Default value: 2.
-o,--encoding <arg>The encoding standard of the imported file. Valid values: GBK and UTF-8. Default value: UTF-8.
-Q,--disableInsertOnlyPrintSql <arg>Specifies whether to execute the INSERT statement. If you set this parameter to true, the INSERT statement is only displayed and not executed. If you set this parameter to false, the INSERT statement is executed. Default value: false.
-s,--lineSeparator <arg>The row delimiter. By default,
\\nis used as the row delimiter in AnalyticDB for MySQL. You can also use non-printable characters as column delimiters. If you want to use non-printable characters, you must specify them in hexadecimal notation. For example,\x0d\x06\x08\x0amust be specified ashex0d06080a.-S,--printErrorStackTrace <arg>Specifies whether to display the stack information when errors occur and
printErrorSqlis set to true Default value: false.-w,--windowSize <arg>The size of the buffer pool when the INSERT statement is executed. This ensures that I/O and computing are separated and all procedures are accelerated when data is sent to AnalyticDB for MySQL to improve the performance of the client. Default value: 128.
-x,--insertWithColumnNames <arg>Specifies whether to append column names when the
INSERT INTOstatement is executed. For example, data can be imported by executing theINSERT INTO tb(column1, column2)statement. Default value: true.-y,--failureSqlPrintLengthLimit <arg>The maximum length of the SQL statements that are displayed when the INSERT statement fails to be executed. Default value: 1000.
-z,--connectionUrlParam <arg>The configurations of the database connection parameters. Default value:
?characterEncoding=utf-8.Example:
?characterEncoding=utf-8&autoReconnect=true.Example 1: In the following command, the default parameter configurations are used to import a single file:
java -Xmx8G -Xms8G -jar adb-import-tool.jar -hyourhost.ads.aliyuncs.com -uadbuser -ppassword -P3306 -Dtest --dataFile /data/lineitem.sample --tableName LINEITEMExample 2: In the following command, values of related parameters are modified to import all files of a folder with a maximum throughput:
java -Xmx16G -Xms16G -jar adb-import-tool.jar -hyourhost.ads.aliyuncs.com -uadbuser -ppassword -P3306 -Dtest --dataFile /data/tpch100g --tableName LINEITEM --concurrency 64 --batchSize 2048