After a model is trained, the model is usually deployed as an inference service. The number of calls to an inference service dynamically changes based on the business requirements. Elastic scaling is required to handle different loads and reduce costs. Conventional deployment solutions cannot meet the elasticity requirement of large-scale and highly concurrent systems. Container Service for Kubernetes (ACK) allows you to deploy workloads in elastic node pools to enable elastic scaling for inference services. This topic describes how to run elastic inference workloads on Elastic Compute Service (ECS) instances.
Prerequisites
A model is trained. In this topic, a BERT model trained with TensorFlow 1.15 is used.
The ack-alibaba-cloud-metrics-adapter component is installed. For more information, see Manage components.
AI Dashboard is installed. For more information, see Deploy the cloud-native AI suite.
Procedure
Create an elastic node pool.
Log on to the ACK console. In the left-side navigation pane, click Clusters.
On the Clusters page, find the cluster that you want to manage and click the name of the cluster or click Details in the Actions column. The details page of the cluster appears.
In the left-side navigation pane of the details page, choose .
In the upper-right corner of the Node Pools page, click Create Node Pool.
In the Create Node Pool dialog box, set the parameters and click Confirm Order. The following table describes the key parameters. For more information about other parameters, see Create and manage a node pool.
Parameter
Description
Auto Scaling
Select Auto, and configure the Min. Instances and Max. Instances.
Billing Method
Select Preemptible Instance.
Node Labels
Set Key to
inferenceand Value totensorflow.Scaling Policy
Select Cost Optimization, and set Percentage of Pay-as-you-go Instances to 30%.
Upload the trained model to an Object Storage Service (OSS) bucket. For more information, see Upload objects.
Create a persistent volume (PV) and a persistent volume claim (PVC).
Create a file named
pvc.yamland copy the following content into the file:apiVersion: v1 kind: PersistentVolume metadata: name: model-csi-pv spec: capacity: storage: 5Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: model-csi-pv // The value must be the same as the name of the PV. volumeAttributes: bucket: "<Your Bucket>" url: "<Your oss url>" akId: "<Your Access Key Id>" akSecret: "<Your Access Key Secret>" otherOpts: "-o max_stat_cache_size=0 -o allow_other" --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: model-pvc spec: accessModes: - ReadWriteMany resources: requests: storage: 5GiParameter
Description
bucket
The name of the OSS bucket, which is globally unique in OSS. For more information, see Bucket naming conventions.
url
The URL that is used to access an object in the bucket. For more information, see Obtain the URL of a single object or the URLs of multiple objects.
akId
The AccessKey ID and AccessKey secret that are used to access the OSS bucket. We recommend that you access the OSS bucket as a Resource Access Management (RAM) user. For more information, see Create an AccessKey pair.
akSecret
otherOpts
Custom parameters for mounting the OSS bucket.
Set
-o max_stat_cache_size=0to disable metadata caching. If this feature is disabled, the system retrieves the latest metadata from OSS each time it attempts to access objects in OSS.Set
-o allow_otherto allow other users to access the OSS bucket that you mounted.
For more information about other parameters, see Custom parameters supported by ossfs.
Run the following command to create the PV and PVC:
kubectl apply -f pvc.yaml
Run the following command to deploy the inference service:
arena serve tensorflow \ --name=bert-tfserving \ --model-name=chnsenticorp \ --selector=inference:tensorflow \ --gpus=1 \ --image=tensorflow/serving:1.15.0-gpu \ --data=model-pvc:/models \ --model-path=/models/tensorflow \ --version-policy=specific:1623831335 \ --limits=nvidia.com/gpu=1 \ --requests=nvidia.com/gpu=1Parameter
Description
selectorThe
selectorparameter is used to select the pods for the TensorFlow training job based on labels. In this example, the value is set toinference: tensorflow.limits: nvidia.com/gpuThe maximum number of GPUs that can be used by the service.
requests: nvidia.com/gpuThe minimum number of GPUs that are required by the service.
model-nameThe name of the model.
model-pathThe path of the model.
Configure a Horizontal Pod Autoscaler (HPA). The HPA can automatically adjust the number of replicated pods in a Kubernetes cluster based on workloads.
Create a file named
hpa.yamland copy the following content into the file:apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: bert-tfserving-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: bert-tfserving-202107141745-tensorflow-serving minReplicas: 1 maxReplicas: 10 metrics: - type: External external: metricName: sls_ingress_qps metricSelector: matchLabels: sls.project: "k8s-log-c210fbedb96674b9eaf15f2dc47d169a8" sls.logstore: "nginx-ingress" sls.ingress.route: "default-bert-tfserving-202107141745-tensorflow-serving-8501" targetAverageValue: 10Parameter
Description
scaleTargetRefThe object to which the HPA is bound. In this example, the value is set to the name of the Deployment of the inference service.
minReplicasThe minimum number of replicated pods.
maxReplicasThe maximum number of replicated pods.
sls.projectThe name of the Simple Log Service project that is used by the cluster. The value of the parameter must be in the format of
k8s-log-{cluster id}.sls.logstoreThe name of the Simple Log Service Logstore. The default value is
nginx-ingress.sls.ingress.routeThe Ingress that is used to expose the service. In this example, the value is set to
{namespace}-{service name}-{service port}.metricnameThe metric name. In this example, the value is set to
sls_ingress_qps.targetaverageValueThe queries per second (QPS) value that triggers scale-out activities. In this example, the value of this parameter is set to
10. A scale-out activity is triggered when the QPS value is greater than 10.Run the following command to deploy the HPA:
kubectl apply -f hpa.yaml
Configure an Internet-facing Ingress.
By default, the inference service that is deployed by running the
arena serve tensorflowcommand uses a ClusterIP Service, which cannot be accessed over the Internet. Therefore, you must create an Internet-facing Ingress for the inference service.Log on to the ACK console. In the left-side navigation pane, click Clusters.
On the Clusters page, find the cluster that you want to manage and click its name. In the left-side pane, choose .
In the upper part of the Ingresses page, select the namespace where the inference service resides from the Namespace drop-down list, and click Create Ingress. Set the parameters that are described in the following table. For more information about the parameters, see Create an NGINX Ingress.
Name: In this example, the value is set to
bert-tfserving.Rule:
Domain Name: Enter a custom domain name, such as
test.example.com.Mappings
Path: The root path
/is used in this example.Rule: The default rule (ImplementationSpecific) is used in this example.
Service Name: Enter the service name that is returned by the
kubectl get servicecommand.Port: In this example, set this parameter to 8501.
After you create the Ingress, go to the Ingresses page and find the Ingress. The value in the Rules column contains the endpoint of the Ingress.
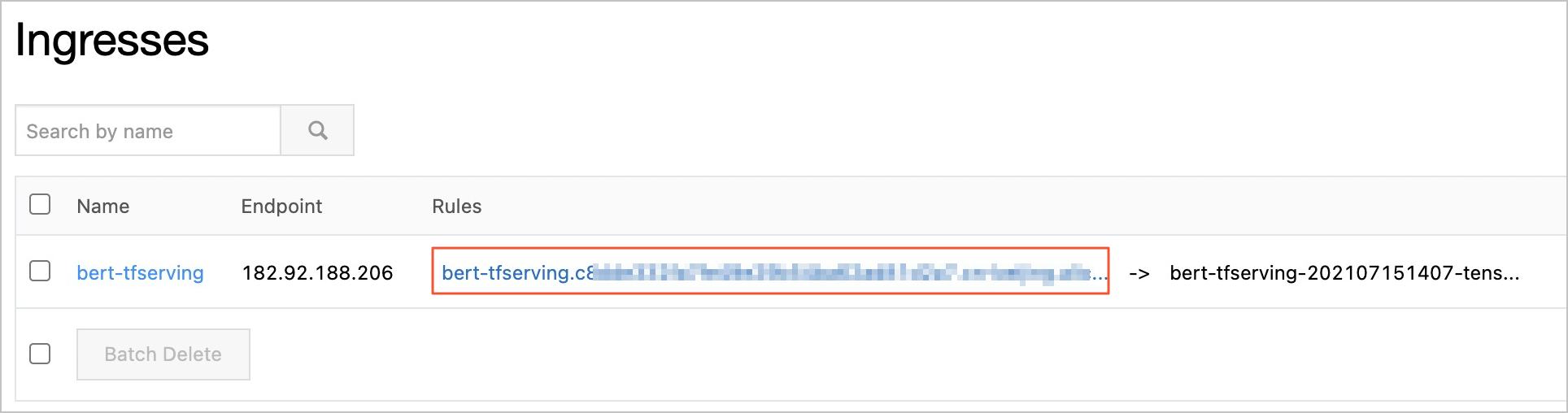
Use the obtained Ingress address to perform stress tests on the inference service.
Log on to AI Dashboard. For more information, see Access AI Dashboard.
ImportantBefore you log on to AI Dashboard, you must install the cloud-native AI suite and specify the access method. For more information, see Deploy the cloud-native AI suite.
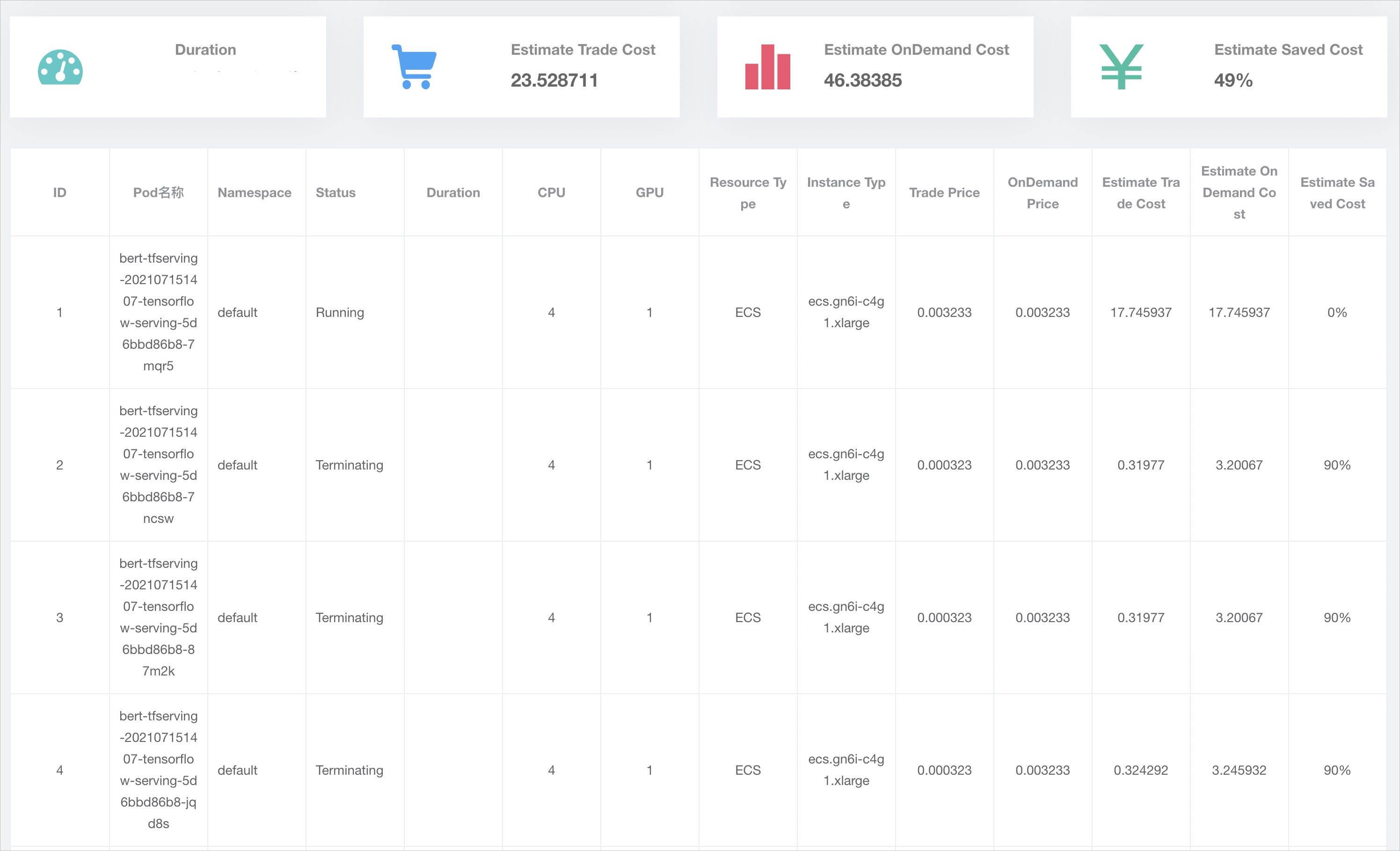
In the left-side navigation pane of AI Dashboard, choose . Click the Inference Job tab to view the details about the inference service.
The following figure shows that all pods created in a scale-out activity run on ECS instances. Both pay-as-you-go and preemptible ECS instances are provisioned. The ratio of pay-as-you-go ECS instances equals the percentage value that you specified when you created the node pool.