You can add Elastic Compute Service (ECS) instances of the enterprise-class 8th generation instance family g8i to Container Service for Kubernetes (ACK) clusters as worker nodes and adopt the Intel® Extension for PyTorch (IPEX) technology to accelerate text-to-image inference. You can also create a node pool that supports Trust Domain Extensions (TDX) confidential VMs and then migrate your inference service to the node pool to enhance the security of the inference service. This topic uses a Stable Diffusion XL Turbo model as an example to describe how to use a CPU acceleration policy and the g8i instance family to obtain an accelerated model inference experience same as using GPU-accelerated ECS instances. This allows you to develop stable, high-performance, cost-effective, and secure text-to-image inference services.
Background information
The enterprise-class 8th generation instance family g8i
The 8th generation general-purpose ECS instance family g8i is empowered by Cloud Infrastructure Processing Units (CIPUs) and Apsara Stack. It uses the 5th Gen Intel® Xeon® Scalable processors (code-named Emerald Rapids) to boost performance. In addition, the g8i instance family adopts Advanced Matrix Extensions (AMX), which offers enhanced AI performance and security. All ECS instances of the g8i instance family support Intel® TDX. This technology allows you to deploy your workloads in a Trusted Execution Environment (TEE) without making application-facing changes. It eliminates the technology gap for beginners and enhances the confidentiality of AI applications such as large language models with minimum performance loss. For more information, see g8i, general-purpose instance family.
Intel® TDX
Intel® TDX is a CPU hardware-based technology that provides hardware-assisted isolation and encryption for ECS instances to protect runtime data, such as CPU registers, memory data, and interrupt injections. TDX helps achieve high levels of data privacy and mitigate risks that are associated with unauthorized access to running processes or sensitive data that is being processed. For more information about Intel® TDX, see Intel® Trust Domain Extensions (Intel® TDX).
Intel® TDX provides default out-of-the-box protection for your ECS instances and applications. You can migrate applications to a TDX-enabled instance without the need to modify the application code.
IPEX
Intel® Extension for PyTorch (IPEX) is an open source PyTorch extension maintained by Intel. It greatly improves the performance of AI applications that use PyTorch and run on Intel processors. Intel will continuously optimize IPEX with the cutting-edge hardware and software technologies to empower the PyTorch community. For more information, see IPEX.
Alibaba Cloud does not guarantee the legitimacy, security, and accuracy of the third-party models "Stable Diffusion" and "stabilityai/sdxl-turbo". Alibaba Cloud is not responsible for any loss or damage arising from using these models.
You must abide by the user agreements, usage specifications, and relevant laws and regulations of the third-party models. You agree that your use of the third-party models is at your sole risk.
The sample service in this topic is only for learning, testing, and proof of concept (POC) and the statistics are for reference only. The actual statistics may vary based on your environment.
Prerequisites
An ACK Pro cluster is created in the China (Beijing) region. For more information, see Create an ACK managed cluster.
A node pool is created.
Regular node pool: Create a node pool that contains ECS instances of the g8i instance family and meets the following requirements:
Region and zone: The node pool resides in a region and zone supported by ECS. For more information, see Instance Types Available for Each Region.
Instance types: Select an instance type that provides at least 16 vCPUs. We recommend that you select
ecs.g8i.4xlarge, ecs.g8i.8xlarge, orecs.g8i.12xlarge.Disk space: The disk space of each node in the node pool is at least 200 GiB. You can use a system disk or data disk that is larger than 200 GiB.
Node pool that supports TDX confidential VMs: You can also seamlessly migrate your application to a node pool that supports TDX confidential VMs to enhance the security of your inference service. To do this, make sure that the Prerequisites are met.
A kubectl client is connected to the ACK cluster. For more information, see Connect to an ACK cluster by using kubectl.
Step 1: Prepare a Stable Diffusion XL Turbo model
The Stable Diffusion XL Turbo model stabilityai/sdxl-turbo is used in this example.
Procedure
Use the official stabilityai/sdxl-turbo model
Create a file named values.yaml and add the following content to the file. You can modify the resource configuration based on the instance type of the node pool.
resources:
limits:
cpu: "16"
memory: 32Gi
requests:
cpu: "14"
memory: 24GiUse a custom stabilityai/sdxl-turbo model
You can also use a custom stabilityai/sdxl-turbo model stored in Object Storage Service (OSS). Create a Resource Access Management (RAM) user that has OSS access permissions and obtain the AccessKey pair of the RAM user.
Procedure
Create a file named models-oss-secret.yaml and add the following content to the file.
apiVersion: v1 kind: Secret metadata: name: models-oss-secret namespace: default stringData: akId: <yourAccessKeyID> # Replace with the AccessKey ID of the RAM user. akSecret: <yourAccessKeySecret> # Replace with the AccessKey secret of the RAM user.Run the following command to create a Secret:
kubectl create -f models-oss-secret.yamlExpected output:
secret/models-oss-secret createdCreate a file named models-oss-pv.yaml and add the following content to the file.
apiVersion: v1 kind: PersistentVolume metadata: name: models-oss-pv labels: alicloud-pvname: models-oss-pv spec: capacity: storage: 50Gi accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: models-oss-pv nodePublishSecretRef: name: models-oss-secret namespace: default volumeAttributes: bucket: "<yourBucketName>" # Replace with the name of the OSS bucket to be mounted. url: "<yourOssEndpoint>" # Replace with the endpoint of the OSS bucket to be mounted. We recommend that you use an internal endpoint. In this example, the endpoint is oss-cn-beijing-internal.aliyuncs.com. otherOpts: "-o umask=022 -o max_stat_cache_size=0 -o allow_other" path: "/models" # The path of the model. Make sure that the stabilityai/sdxl-turbo directory can be found in this path.For more information about the OSS parameters, see Method 1: Use a Secret.
Run the following command to create a statically provisioned persistent volume (PV):
kubectl create -f models-oss-pv.yamlExpected output:
persistentvolume/models-oss-pv createdCreate a file named models-oss-pvc.yaml and add the following content to the file:
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: models-oss-pvc spec: accessModes: - ReadOnlyMany resources: requests: storage: 50Gi selector: matchLabels: alicloud-pvname: models-oss-pvRun the following command to create a persistent volume claim (PVC):
kubectl create -f models-oss-pvc.yamlExpected output:
persistentvolumeclaim/models-oss-pvc createdCreate a file named values.yaml and add the following content to the file.
You can modify the resource configuration based on the instance type of the node pool.
resources: limits: cpu: "16" memory: 32Gi requests: cpu: "14" memory: 24Gi useCustomModels: true volumes: models: name: data-volume persistentVolumeClaim: claimName: models-oss-pvc
Service deployment configuration in values.yaml
Step 2: Deploy the sample service
Run the following command to deploy an IPEX-accelerated Stable Diffusion XL Turbo model:
helm install stable-diffusion-ipex https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/pre/charts-incubator/stable-diffusion-ipex-0.1.7.tgz -f values.yamlExpected output:
NAME: stable-diffusion-ipex LAST DEPLOYED: Mon Jan 22 20:42:35 2024 NAMESPACE: default STATUS: deployed REVISION: 1 TEST SUITE: NoneWait 10 minutes and run the following command to query the status of the pod. Make sure that the pod is running.
kubectl get pod |grep stable-diffusion-ipexExpected output:
stable-diffusion-ipex-65d98cc78-vmj49 1/1 Running 0 1m44s
After the service is deployed, generate a publicly accessible text-to-image API. For more information about the API, see API parameters.
Step 3: Test the sample service
Procedure
Run the following command to map the port of the Stable Diffusion XL Turbo model service to a local port:
kubectl port-forward svc/stable-diffusion-ipex 5000:5000Expected output:
Forwarding from 127.0.0.1:5000 -> 5000 Forwarding from [::1]:5000 -> 5000Use text prompts to request the service to generate an image.
In this example, the service generates
512x512or1024x1024images.512x512 image
Run the following command to request the service to generate an image based on the text prompt
A panda listening to music with headphones. highly detailed, 8k.:curl -X POST http://127.0.0.1:5000/api/text2image \ -d '{"prompt": "A panda listening to music with headphones. highly detailed, 8k.", "number": 1}'Expected output:
{ "averageImageGenerationTimeSeconds": 2.0333826541900635, "generationTimeSeconds": 2.0333826541900635, "id": "9ae43577-170b-45c9-ab80-69c783b41a70", "meta": { "input": { "batch": 1, "model": "stabilityai/sdxl-turbo", "number": 1, "prompt": "A panda listening to music with headphones. highly detailed, 8k.", "size": "512x512", "step": 4 } }, "output": [ { "latencySeconds": 2.0333826541900635, "url": "http://127.0.0.1:5000/images/9ae43577-170b-45c9-ab80-69c783b41a70/0_0.png" } ], "status": "success" }You can enter the returned URL into the address bar of your browser to view the image.
1024x1024 image
Run the following command to request the service to generate an image based on the text prompt
A panda listening to music with headphones. highly detailed, 8k.:curl -X POST http://127.0.0.1:5000/api/text2image \ -d '{"prompt": "A panda listening to music with headphones. highly detailed, 8k.", "number": 1, "size": "1024x1024"}'Expected output:
{ "averageImageGenerationTimeSeconds": 8.635204315185547, "generationTimeSeconds": 8.635204315185547, "id": "ac341ced-430d-4952-b9f9-efa57b4eeb60", "meta": { "input": { "batch": 1, "model": "stabilityai/sdxl-turbo", "number": 1, "prompt": "A panda listening to music with headphones. highly detailed, 8k.", "size": "1024x1024", "step": 4 } }, "output": [ { "latencySeconds": 8.635204315185547, "url": "http://127.0.0.1:5000/images/ac341ced-430d-4952-b9f9-efa57b4eeb60/0_0.png" } ], "status": "success" }You can enter the returned URL into the address bar of your browser to view the image.
Test data
The following table describes the duration statistics of the Stable Diffusion XL Turbo model that generates 512x512 and 1024x1024 images on different ECS instance types of g8i instance family. The statistics are for reference only. The actual statistics may vary based on your environment.
Instance type | Pod Request/Limit | Parameter | Average duration each time (512x512) | Average duration each time (1024x1024) |
ecs.g8i.4xlarge (16 vCPUs, 64 GiB) | 14/16 | batch: 1 step: 4 | 2.2s | 8.8s |
ecs.g8i.8xlarge (32 vCPUs, 128 GiB) | 24/32 | batch: 1 step: 4 | 1.3s | 4.7s |
ecs.g8i.12xlarge (48 vCPUs, 192 GiB) | 32/32 | batch: 1 step: 4 | 1.1s | 3.9s |
(Optional) Step 4: Migrate the service to a node pool that supports TDX confidential VMs
After the sample service is deployed, you can seamlessly migrate the service to a node pool that supports TDX confidential VMs to enhance the security of the inference service.
Prerequisites
A node pool that supports TDX confidential VMs is created in the ACK cluster and the node pool meets the requirements. For more information, see Create a node pool that supports TDX confidential VMs.
In addition, the node pool meets the following requirements:
Instance type: Select an instance type that provides at least 16 vCPUs. We recommend that you choose ecs.g8i.4xlarge.
Disk space: The disk space of each node in the node pool is at least 200 GiB. You can use a system disk or data disk that is larger than 200 GiB.
Node label: Add the
nodepool-label=tdx-vm-poollabel to the node pool.
Procedure
Create a file named tdx_values.yaml and add the following content to the file.
For more information about the values.yaml file, see Service deployment configuration in values.yaml.
NoteIn this example, the
nodepool-label=tdx-vm-poollabel is added to the node pool. To add other labels, replace the value ofnodepool-labelin thenodeSelectorsection.nodeSelector: nodepool-label: tdx-vm-poolRun the following command to migrate the Stable Diffusion model to the node pool:
helm upgrade stable-diffusion-ipex https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/pre/charts-incubator/stable-diffusion-ipex-0.1.7.tgz -f tdx_values.yamlExpected output:
Release "stable-diffusion-ipex" has been upgraded. Happy Helming! NAME: stable-diffusion-ipex LAST DEPLOYED: Wed Jan 24 16:38:04 2024 NAMESPACE: default STATUS: deployed REVISION: 2 TEST SUITE: NoneWait 10 minutes and query the status of the pod. Make sure that the pod is running.
kubectl get pod |grep stable-diffusion-ipexExpected output:
stable-diffusion-ipex-7f8c4f88f5-r478t 1/1 Running 0 1m44sRepeat Step 3: Test the sample service to test the Stable Diffusion model in the node pool.
API information
API parameters
After you deploy a Stable Diffusion XL Turbo service from the stabilityai/sdxl-turbo model, the service generates a publicly accessible text-to-image API. The following tables describe the API parameters.
Request syntax
POST /api/text2imageRequest parameters
Sample request
Response parameters
Sample response
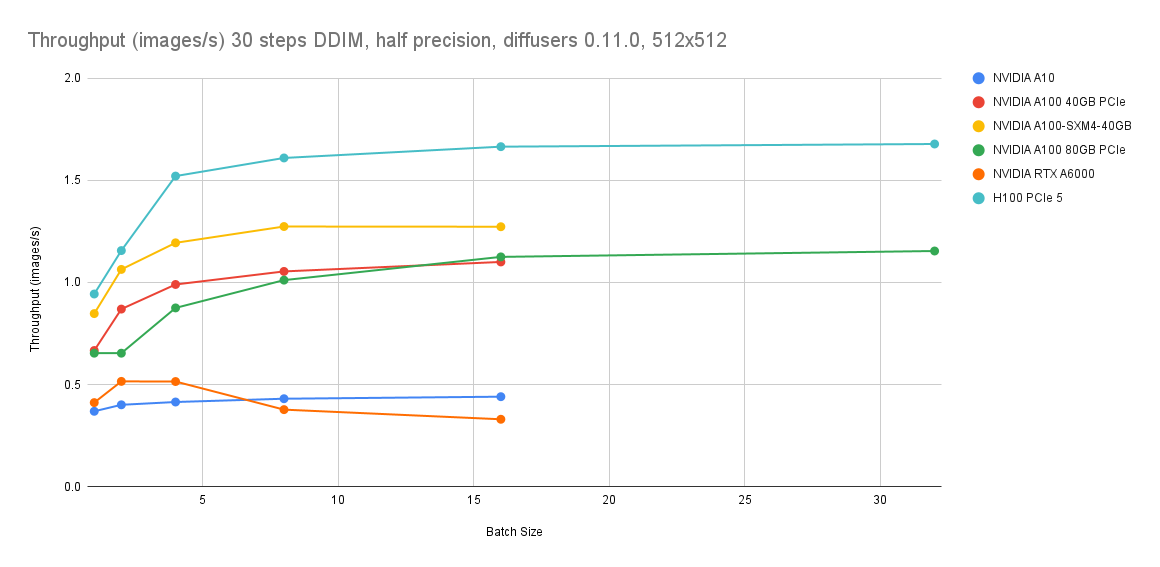
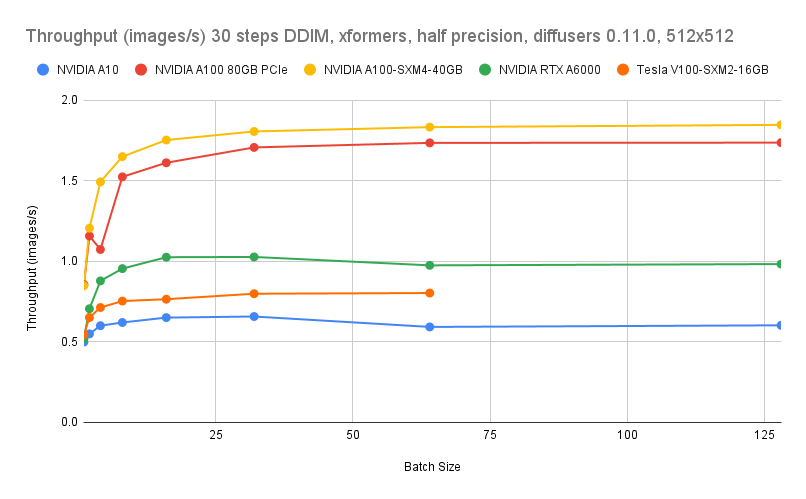
Performance comparison
The node pool that supports TDX confidential VMs contain ECS instances of the g8i instance family empowered by AMX and IPEX. They can efficiently accelerate text-to-image inference and allow you to enable TEE to enhance security. In this example, ECS instances of the ecs.g8i.4xlarge type equipped with the 5th Gen Intel® Xeon® Scalable processors are used to run and fine-tune the stabilityai/sdxl-turbo model. This example demonstrates how to develop cost-effective and secure text-to-image inference service.
In the perspective of image generation speeds, GPU acceleration (A10) still surpasses CPU acceleration. When the instance type is ecs.g8i.8xlarge, step is 30, and batch size is 16, images are generated at a rate of 0.14 images/s. When the instance type is A10 GPU-accelerated instance, step is 30, and batch size 16, images are generated at a rate of 0.4 images/s. However, in the perspective of optimal image quality, when the instance type is ecs.g8i.8xlarge, step is 4, and batch size is 16, images are generated at a rate of 1.2 images/s. This means that one image can still be generated per second without compromising the image quality.
Therefore, this solution provides an alternative to GPU acceleration to help you develop stable, high-performance, cost-effective, and secure text-to-image inference services.
If you require cost-effectiveness, TEE confidential computing, and large-scale resource supply, we recommend that you use the ecs.g8i.4xlarge instance type to run and fine-tune the stabilityai/sdxl-turbo model.
Using ecs.g8i.8xlarge instead of ecs.gn7i-c8g1.2xlarge reduces the cost by 9% and still guarantees an image generation rate of 1.2 images/s.
Using ecs.g8i.4xlarge instead of ecs.gn7i-c8g1.2xlarge slows down image generation to 0.5 images/s but reduces the cost by more than 53%.
The actual prices of ECS instances in different regions on the Pricing tab of the Elastic Compute Service landing page shall prevail.
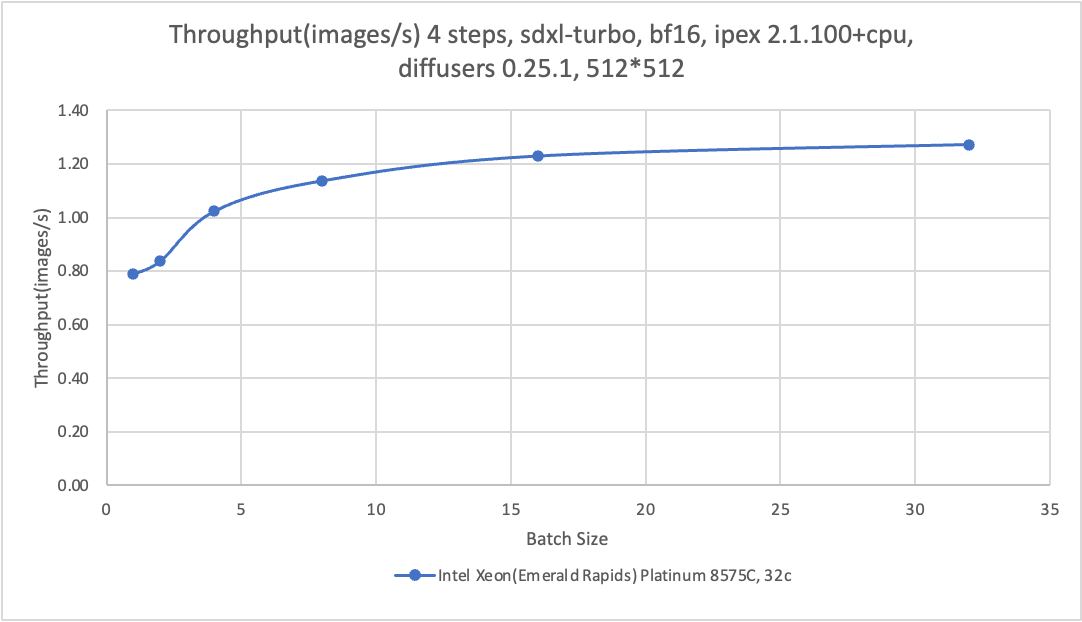
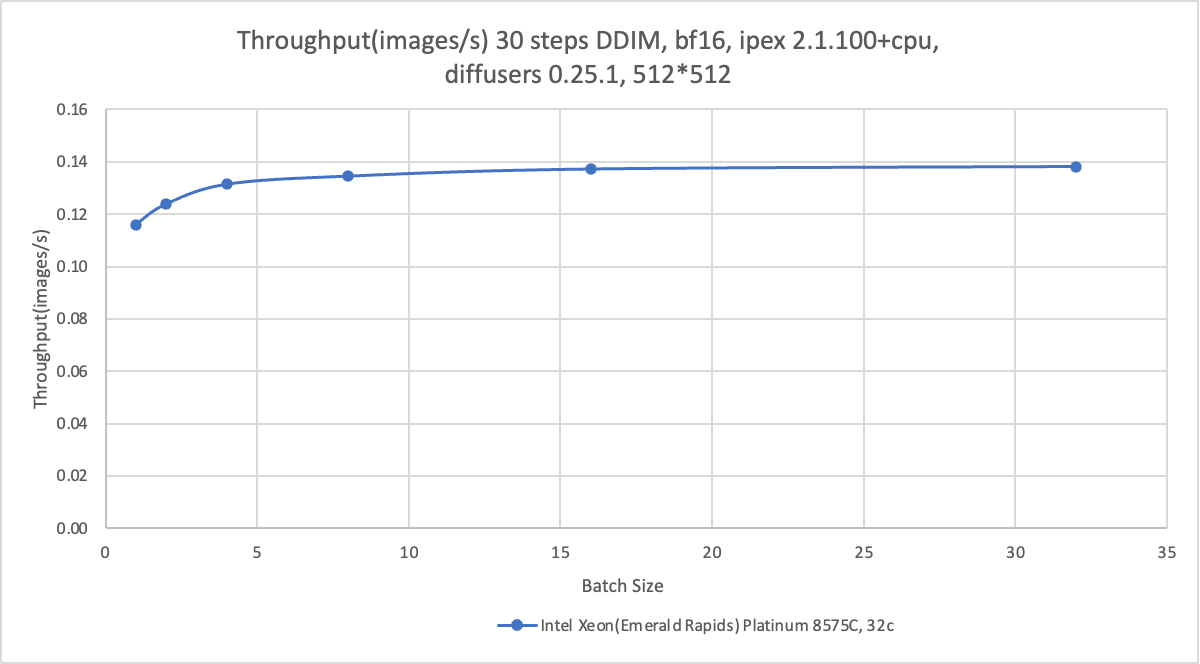
CPU acceleration
The benchmarking data of different inference models is generated based on the ecs.g8i.8xlarge instance type. The following table describes the benchmarking data. For more information, see Benchmark Tools: lambda-diffusers.
The benchmarking data is for reference only. The actual data may vary based on your environment.
Instance type | Alibaba Cloud ecs.g8i.8xlarge 32vCPUs, 128 GiB VM, EMR | Alibaba Cloud ecs.g8i.8xlarge 32vCPUs, 128 GiB VM, EMR |
step | 4 | 30 |
Model | sdxl-turbo | stable-diffusion-2-1-base |
Command | python sd_pipe_sdxl_turbo.py --bf16 --batch 1 --height 512 --width 512 --repeat 5 --step 4 --prompt "A panda listening to music with headphones. highly detailed, 8k" | python sd_pipe_infer.py --model /data/models/stable-diffusion-2-1-base --bf16 --batch 1 --height 512 --width 512 --repeat 5 --step 30 --prompt "A panda listening to music with headphones. highly detailed, 8k" |
Performance |
|
|
GPU acceleration
The benchmarking data used in this example is from Lambda Diffusers. The actual benchmarking data may vary. For more information, see Lambda Diffusers Benchmarking inference.