The nearby memory access acceleration feature of ack-koordinator migrates the memory on the remote non-uniform memory access (NUMA) of a CPU-bound application to the local server in a secure manner. This improves the hit ratio of local memory access and improves the performance of memory-intensive applications. This topic describes how to use the nearby memory access acceleration feature and how to verify that the feature improves the performance of memory-intensive applications.
Table of contents
Prerequisites
A Container Service for Kubernetes (ACK) Pro cluster that runs Kubernetes 1.18 or later is created. For more information, see Create an ACK managed cluster.
A kubectl client is connected to the cluster. For more information, see Obtain the kubeconfig file of a cluster and use kubectl to connect to the cluster.
ack-koordinator (FKA ack-slo-manager) 1.2.0-ack1.2 or later is installed. For more information about how to install ack-koordinator, see ack-koordinator (FKA ack-slo-manager).
Noteack-koordinator supports all features provided by resource-controller. If you are currently using resource-controller, you must uninstall it before you install ack-koordinator. For more information about how to uninstall resource-controller, see Uninstall resource-controller.
The fifth-generation, sixth-generation, seventh-generation, or eighth-generation Elastic Compute Service (ECS) instances of the ecs.ebmc, ecs.ebmg, ecs.ebmgn, ecs.ebmr, ecs.ebmhfc, or ecs.scc instance families are used to deploy multi-NUMA instances.
NoteThe nearby memory access acceleration feature functions better on the eighth-generation ECS instances of the ecs.ebmc8i.48xlarge, ecs.c8i.32xlarge, and ecs.g8i.48xlarge instance types. For more information about ECS instance families, see ECS instance families.
Applications are deployed on multi-NUMA instances. CPU cores are bound to the applications by using features such as topology-aware CPU scheduling. For more information, see Enable topology-aware CPU scheduling.
Billing
No fee is charged when you install or use the ack-koordinator component. However, fees may be charged in the following scenarios:
ack-koordinator is a non-managed component that occupies worker node resources after it is installed. You can specify the amount of resources requested by each module when you install the component.
By default, ack-koordinator exposes the monitoring metrics of features such as resource profiling and fine-grained scheduling as Prometheus metrics. If you enable Prometheus metrics for ack-koordinator and use Managed Service for Prometheus, these metrics are considered custom metrics and fees are charged for these metrics. The fee depends on factors such as the size of your cluster and the number of applications. Before you enable Prometheus metrics, we recommend that you read the Billing topic of Managed Service for Prometheus to learn about the free quota and billing rules of custom metrics. For more information about how to monitor and manage resource usage, see Query the amount of observable data and bills.
Benefits of the nearby memory access acceleration feature
In the multi-NUMA architecture, if a process that runs on a vCore of a NUMA node needs to access the memory on a remote NUMA node, the request must pass the QuickPath Interconnect (QPI) bus. The time required for a process to access the memory on a remote NUMA node is longer than the time required for the process to access the memory on the local NUMA node. Cross-node memory access reduces the hit ratio of local memory access and compromises the performance of memory-intensive applications.
Assume that a memory-intensive Redis application is bound with all vCores provided by an ECS instance. Processes of the Redis application may need to access vCores across NUMA nodes. If the Redis application is deployed on an ECS instance of the ecs.ebmc8i.48xlarge type, a portion of the memory required by the application is distributed to the remote NUMA node, as shown in the following figure. Stress test results show that the QPS of redis-server when the memory is fully distributed to the local NUMA node is 10.52% higher than the QPS of redis-server when the memory is randomly distributed between the local NUMA node and the remote NUMA node. The stress test results also show that the QPS of redis-server when the memory is fully distributed to the local NUMA node is 26.12% higher than the QPS of redis-server when the memory is fully distributed to the remote NUMA node. The following figure shows the comparison.
The test statistics provided in this topic are theoretical values. The actual values may vary based on your environment.
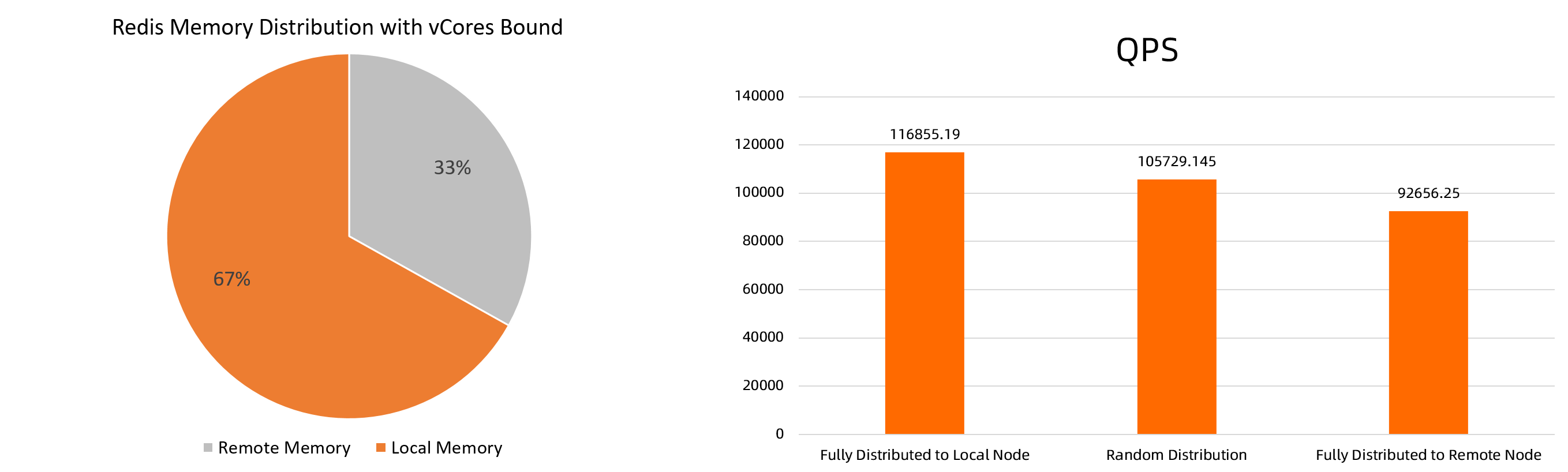
To optimize memory access for applications, ack-koordinator provides the nearby memory access acceleration feature. If you bind vCores to your application by using features such as topology-aware CPU scheduling, we recommend that you migrate memory from the remote NUMA node to the local node in a secure manner. The migration does not cause service interruptions.
Use scenarios
The nearby memory access acceleration feature is ideal for the following scenarios:
Memory-intensive workloads, such as large-scale Redis in-memory databases, are deployed.
ECS instances integrated with Intel Data Streaming Accelerator (DSA) are used. DSA can improve the performance of the nearby memory access acceleration feature and reduce CPU consumption.
Use the nearby memory access acceleration feature
Step 1: Use a policy to enable the nearby memory access acceleration feature
You can use one of the following methods to enable the nearby memory access acceleration feature:
Use the
metadata.annotations/koordinator.sh/memoryLocalityannotation to enable the nearby memory access acceleration feature for individual pods. For more information, see Enable the nearby memory access acceleration feature for individual pods.Configure the
memoryLocalityparameter in theconfigmap/ack-slo-configConfigMap to enable the nearby memory access acceleration feature for all pods of the specified quality of service (QoS) class. For more information, see Enable the nearby memory access acceleration feature for all pods of the specified QoS class.
Enable the nearby memory access acceleration feature for individual pods
Run the following command to enable the nearby memory access acceleration feature for the CPU-bound Redis pod:
kubectl annotate pod <pod-name> koordinator.sh/memoryLocality='{"policy": "bestEffort"}' --overwriteValid values of the policy parameter:
bestEffort: immediately accelerates individual requests to the nearby memory.none: disables the nearby memory access acceleration feature.
Enable the nearby memory access acceleration feature for all pods of the specified QoS class
Create a file named ml-config.yaml and copy the following content to the file:
apiVersion: v1 data: resource-qos-config: |- { "clusterStrategy": { "lsClass": { "memoryLocality": { "policy": "bestEffort" } } } } kind: ConfigMap metadata: name: ack-slo-config namespace: kube-systemRun the following command to check whether the
configmap/ack-slo-configConfigMap exists in the kube-system namespace:To avoid changing the original QoS settings, check whether the
ack-slo-configConfigMap exists.kubectl get cm ack-slo-config -n kube-systemIf the
configmap/ack-slo-configConfigMap does not exist, run the following command to create it:kubectl apply -f ml-config.yamlIf the
configmap/ack-slo-configConfigMap exists, run the following command to enable the nearby memory access acceleration feature:kubectl patch cm -n kube-system ack-slo-config --patch "$(cat ml-config.yaml)"
Step 2: Check the pod events to verify the nearby memory access acceleration feature
Run the following command to verify the nearby memory access acceleration feature:
kubectl describe pod <pod-name>Expected output 1:
Normal MemoryLocalityCompleted 6s koordlet Container <container-name-1> completed: migrated memory from remote numa: 1 to local numa: 0 Container <container-name-2> completed: migrated memory from remote numa: 0 to local numa: 1 Total: 2 container(s) completed, 0 failed, 0 skipped; cur local memory ratio 100, rest remote memory pages 0The
completedfield in the output indicates that memory access is accelerated by the nearby memory access acceleration feature. The event records the memory migration direction of each container and the distribution ratio of memory pages after the memory is migrated to the local NUMA node.Expected output 2:
Normal MemoryLocalityCompleted 6s koordlet Container <container-name-1> completed: migrated memory from remote numa: 1 to local numa: 0 Container <container-name-2> completed: failed to migrate the following processes: failed pid: 111111, error: No such process,from remote numa: 0 to local numa: 1 Total: 2 container(s) completed, 0 failed, 0 skipped; cur local memory ratio 100, rest remote memory pages 0The
completedfield in the output indicates that the nearby memory access acceleration feature fails to accelerate access to the nearby memory. For example, the feature fails to migrate memory because the process is terminated during the migration. The event records the ID of the process that is terminated.Expected output 3:
Normal MemoryLocalitySkipped 1s koordlet no target numaThe output indicates that the nearby memory access acceleration feature skips memory migration when no remote NUMA node exists. This is because the ECS instance uses a non-NUMA architecture or the process runs on all NUMA nodes.
Expected output 4:
Other errors are returned. For example, a MemoryLocalityFailed event is generated together with the error message.
(Optional) Step 3: Accelerate multiple requests to the nearby memory
If you have accelerated individual requests to the nearby memory, make sure that the most recent acceleration is completed before you accelerate multiple requests to the nearby memory.
When you accelerate multiple requests to the nearby memory, the acceleration result is recorded in the event only when the change in the acceleration result of nearby memory access exceeds 10% or the change in the memory page distribution ratio exceeds 10% after the memory is migrated to the local NUMA node.
Run the following command to accelerate multiple requests to the nearby memory:
kubectl annotate pod <pod-name> koordinator.sh/memoryLocality='{"policy": "bestEffort","migrateIntervalMinutes":10}' --overwriteThe migrateIntervalMinutes parameter specifies the minimum interval between two accelerated requests. Unit: minutes. Valid values:
0: immediately accelerates individual requests to the nearby memory.> 0: immediately accelerates requests to the nearby memory.none: disables the nearby memory access acceleration feature.
Verify that the nearby memory access acceleration feature improves the performance of memory-intensive applications
Test environment
A multi-NUMA server or VM is deployed. The server or VM is used to deploy a memory-intensive application and serves as the tested machine. In this example, the ecs.ebmc8i.48xlarge and ecs.ebmg7a.64xlarge instance types are used.
A stress test machine that can connect to the tested machine is deployed.
A multi-thread Redis application that requests 4 vCores and 32 GB of memory is deployed.
NoteIf the tested machine uses relatively low specifications, you can deploy a single-thread Redis application and set the CPU request and memory request to smaller values.
Test procedure  Test procedure
Test procedure
Use the following YAML template to deploy a Redis application:
Modify the
redis-configfield based on the specifications of the tested machine.--- kind: ConfigMap apiVersion: v1 metadata: name: example-redis-config data: redis-config: | maxmemory 32G maxmemory-policy allkeys-lru io-threads-do-reads yes io-threads 4 --- kind: Service apiVersion: v1 metadata: name: redis spec: type: NodePort ports: - port: 6379 targetPort: 6379 nodePort: 32379 selector: app: redis --- apiVersion: v1 kind: Pod metadata: name: redis annotations: cpuset-scheduler: "true" # Bind vCores by using topology-aware CPU scheduling. labels: app: redis spec: containers: - name: redis image: redis:6.0.5 command: ["bash", "-c", "redis-server /redis-master/redis.conf"] ports: - containerPort: 6379 resources: limits: cpu: "4" # Modify the value based on the specifications of the tested machine. volumeMounts: - mountPath: /redis-master-data name: data - mountPath: /redis-master name: config volumes: - name: data emptyDir: {} - name: config configMap: name: example-redis-config items: - key: redis-config path: redis.confIncrease the memory loads.
Write business data into the Redis application.
Execute the following shell script to write data into redis-server in batches by using pipelines.
<max-out-cir>and<max-out-cir>specify the amount of data that is written into redis-server. In this example, data is written into a Redis application that requests 4 vCores and 32 GB of memory. Therefore,max-our-cir=300andmax-in-cir=1000000are specified.NoteA long period of time is required to write a large amount of data. To improve the write speed, we recommend that you perform the write operation on the tested machine.
for((j=1;j<=<max-out-cir>;j++)) do echo "set k$j-0 v$j-0" > data.txt for((i=1;i<=<max-in-cir>;i++)) do echo "set k$j-$i v$j-$i" >> data.txt done echo "$j" unix2dos data.txt # To write data by using pipelines, you must use the DOS format. cat data.txt | redis-cli --pipe -h <redis-server-IP> -p <redis-server-port> doneDuring the write process, increase the memory loads on workloads that are deployed in hybrid deployment mode on the NUMA node to which the Redis application is scheduled. This simulates a situation where the memory used by the Redis application is shifted to the memory on other NUMA nodes due to memory load spikes.
Run the
numactl --membindcommand on the tested machine to specify the NUMA nodes on which the workloads are deployed.Run the following stress testing command to increase the memory loads.
<workers-num>specifies the number of processes and<malloc-size-per-workers>specifies the amount of memory that is allocated to each process.NotevCores are bound to the Redis application. Therefore, memory on the local NUMA node is preferably allocated to the Redis application until the memory utilization of the local NUMA node reaches 100%. Set
workers-numandmalloc-size-per-workersbased on the loads of the node. You can run thenumactl -Hcommand to query the memory utilization of each NUMA node.numactl --membind=<numa-id> stress -m <workers-num> --vm-bytes <malloc-size-per-workers>
Use redis-benchmark to perform stress tests with nearby memory access acceleration enabled and disabled.
Perform stress tests with nearby memory access acceleration disabled
After you write data into the Redis application, use redis-benchmark to send requests from the stress test machine to the tested machine to generate medium-level loads and high-level loads on redis-server.
Run the following command to send 500 concurrent requests to generate medium-level loads on redis-server:
redis-benchmark -t GET -c 500 -d 4096 -n 2000000 -h <redis-server-IP> -p <redis-server-port>Run the following command to send 10,000 concurrent requests to generate high-level loads on redis-server:
redis-benchmark -t GET -c 10000 -d 4096 -n 2000000 -h <redis-server-IP> -p <redis-server-port>
Enable nearby memory access acceleration for the Redis application
Run the following command to enable nearby memory access acceleration for the Redis application:
kubectl annotate pod redis koordinator.sh/memoryLocality='{"policy": "BestEffort"}' --overwriteRun the following command to verify nearby memory access acceleration:
If the amount of memory on the remote NUMA node is large, a long period of time is required to migrate memory from the remote NUMA node to the local NUMA node.
kubectl describe pod redisExpected output:
Normal MemoryLocalitySuccess 0s koordlet-resmanager migrated memory from remote numa: 0 to local numa: 1, cur local memory ratio 98, rest remote memory pages 28586
Perform stress tests with nearby memory access acceleration enabled
Perform stress tests to generate medium-level loads and high-level loads on redis-server.
Analyze the test results
In this topic, instances of the ecs.ebmc8i.48xlarge and ecs.ebmg7a.64xlarge types are tested. The following section describes the test results.
The test results may vary based on the stress testing tool that is used. The following test results are based on the ecs.ebmc8i.48xlarge and ecs.ebmg7a.64xlarge instance types.
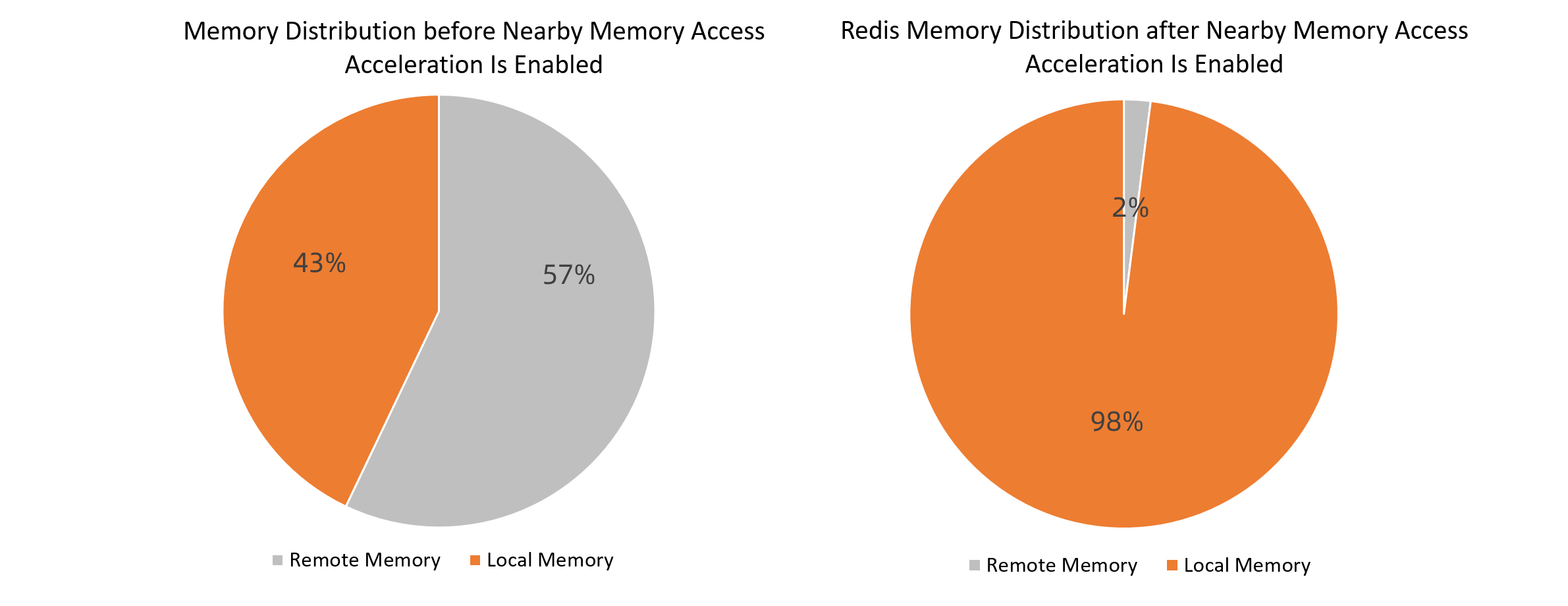
Memory distribution comparison
The following figure shows that the ratio of local memory pages is 43% before nearby memory access acceleration is enabled and the ratio of local memory pages is 98% after nearby memory access acceleration is enabled.
Stress testing results comparison
500 concurrent requests
Test scenario
P99 ms
P99.99 ms
QPS
Before nearby memory access acceleration is enabled
3
9.6
122139.91
After nearby memory access acceleration is enabled
3
8.2
129367.11
10,000 concurrent requests
Test scenario
P99 ms
P99.99 ms
QPS
Before nearby memory access acceleration is enabled
115
152.6
119895.56
After nearby memory access acceleration is enabled
101
145.2
125401.44
Analysis:
Medium concurrency (500 concurrent requests): After nearby memory access acceleration is enabled, the latency of 99% of the requests remains the same, the latency of 99.99% of the requests is reduced by 14.58%, and the QPS of the Redis application is increased by 5.917%.
High concurrency (10,000 concurrent requests): After nearby memory access acceleration is enabled, the latency of 99% of the requests is reduced by 12.17%, the latency of 99.99% of the requests is reduced by 4.85%, and the QPS of the Redis application is increased by 4.59%.
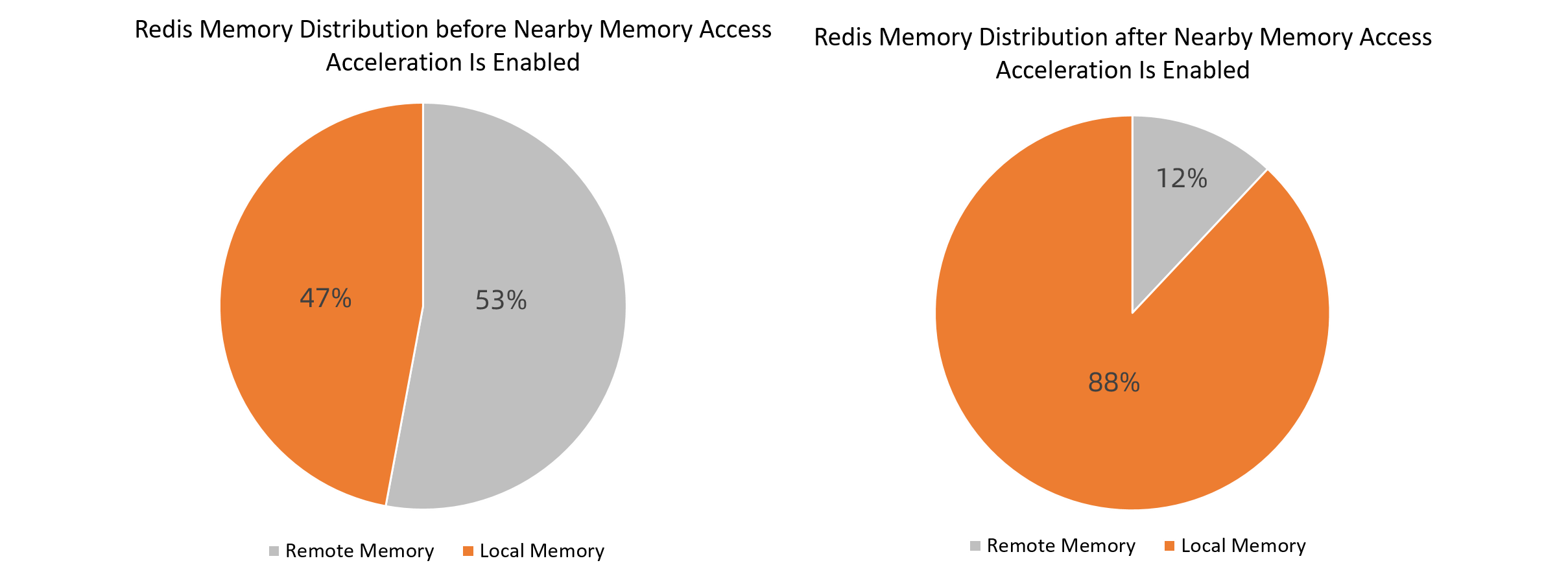
Memory distribution comparison
The following figure shows that the ratio of local memory pages is 47% before nearby memory access acceleration is enabled and the ratio of local memory pages is 88% after nearby memory access acceleration is enabled.
Stress testing results comparison
500 concurrent requests
Test scenario
P99 ms
P99.99 ms
QPS
Before nearby memory access acceleration is enabled
2.4
4.4
135180.99
After nearby memory access acceleration is enabled
2.2
4.4
136296.37
10,000 concurrent requests
Test scenario
P99 ms
P99.99 ms
QPS
Before nearby memory access acceleration is enabled
58.2
80.4
95757.10
After nearby memory access acceleration is enabled
56.6
76.8
97015.50
Analysis:
Medium concurrency (500 concurrent requests): After nearby memory access acceleration is enabled, the latency of 99% of the requests is reduced by 8.33%, the latency of 99.99% of the requests remains the same, and the QPS of the Redis application is increased by 0.83%.
High concurrency (10,000 concurrent requests): After nearby memory access acceleration is enabled, the latency of 99% of the requests is reduced by 2.7%, the latency of 99.99% of the requests is reduced by 4.4%, and the QPS of the Redis application is increased by 1.3%.
Conclusions: When the memory loads are relatively high and application data is stored in the memory of the remote NUMA node, memory access from the application is affected by the ratio of local memory pages. After vCores are bound to the application and nearby memory access acceleration is enabled, the access latency and throughput of the Redis application are optimized under medium concurrency and high concurrency.