Deploying a StatefulSet with disk volumes across multiple availability zones requires coordination between two layers: pod scheduling (where pods land) and volume provisioning (where disks are created). If these layers are not aligned, pods fail to start with zone conflicts or unsupported disk category errors.
This topic covers the recommended node pool, StorageClass, and application configurations that prevent these failures.
Architecture overview
The following diagram shows the recommended architecture: single-zone node pools with auto scaling, a multi-category StorageClass with delayed binding, and topology spread constraints on the application.

Prerequisites
Kubernetes version 1.20 or later
Container Storage Interface (CSI) plug-in version 1.22 or later. For more information, see Manage the CSI plug-in.
A cluster deployed across at least three zones to provide sufficient node and storage resources
Disk volumes (not File Storage NAS) for data persistence. Disks are more stable and provide higher bandwidth than NAS file systems.
Configure node pools
Deploy each node pool in a single zone
Restrict each node pool to one zone. To add capacity in a new zone, create a separate node pool for that zone instead of adding the zone to an existing pool. Include the zone ID in the node pool name (for example, pool-cn-beijing-a) so operators can identify the zone at a glance. For more information, see Create and manage a node pool.
Enable auto scaling
Enable auto scaling on each node pool so the cluster can add nodes automatically when existing nodes become unavailable for pod scheduling. For more information, see Enable node auto scaling.

Use consistent ECS instance types across zones
Use the same Elastic Compute Service (ECS) instance type in every node pool, or at minimum use instance types that support the same disk categories. The disk categories that an ECS instance supports depend on the instance type. If a pod's disk category is not supported by the ECS instance hosting the pod, the mount fails -- even when the disk and instance are in the same zone.
Add taints to isolate node pools
Add taints to the nodes in each node pool to prevent unrelated workloads from consuming capacity that your stateful applications need.
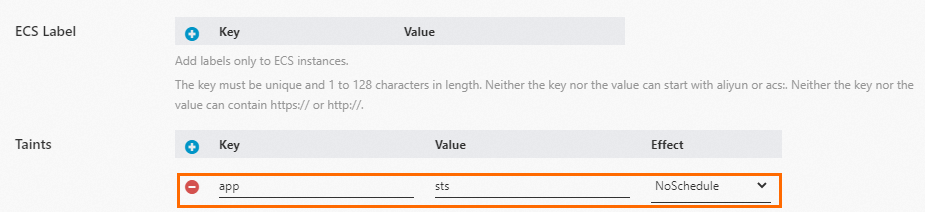
Create the StorageClass
Create a StorageClass that specifies multiple disk categories and delays volume binding until pod scheduling.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: alicloud-disk-topology-alltype
parameters:
type: cloud_essd,cloud_ssd,cloud_efficiency # Fallback order: ESSD > standard SSD > ultra disk
provisioner: diskplugin.csi.alibabacloud.com
reclaimPolicy: Delete
volumeBindingMode: WaitForFirstConsumer # Provision disk after pod is scheduled
allowVolumeExpansion: true
allowedTopologies: # Restrict to specific zones
- matchLabelExpressions:
- key: topology.diskplugin.csi.alibabacloud.com/zone
values:
- cn-beijing-a
- cn-beijing-bKey parameters
| Parameter | Description |
|---|---|
type: cloud_essd,cloud_ssd,cloud_efficiency | The CSI driver tries each disk category in order. It first attempts to create an Enterprise SSD (ESSD). If ESSDs are out of stock in the zone, it falls back to a standard SSD, then to an ultra disk. This fallback chain reduces the risk of pod startup failures caused by disk inventory shortages. |
volumeBindingMode: WaitForFirstConsumer | By default, Kubernetes uses Immediate mode, which creates the disk as soon as the persistent volume claim (PVC) is created -- before a pod is scheduled. For topology-constrained storage like cloud disks, this can place the disk in a zone where no pod will run, resulting in volume node affinity conflict errors. WaitForFirstConsumer delays disk creation until the pod is scheduled. The disk is then created in the same zone as the node, which eliminates zone mismatch failures. |
allowedTopologies | Restricts volume provisioning to specific zones. When combined with WaitForFirstConsumer, the scheduler only places pods in zones listed here, ensuring that both the pod and its disk end up in a supported zone. |
Deploy the application
The following StatefulSet template distributes pods evenly across zones and automatically provisions a disk for each replica.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
serviceName: "mysql"
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
topologySpreadConstraints:
- labelSelector:
matchLabels:
app: mysql
maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
containers:
- image: mysql:5.6
name: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: "mysql"
volumeMounts:
- name: disk-csi
mountPath: /var/lib/mysql
tolerations:
- key: "app"
operator: "Exists"
effect: "NoSchedule"
volumeClaimTemplates:
- metadata:
name: disk-csi
spec:
accessModes: [ "ReadWriteMany" ]
storageClassName: alicloud-disk-topology-alltype
resources:
requests:
storage: 40GiKey parameters
| Parameter | Description |
|---|---|
topologySpreadConstraints | Controls how pods are distributed across zones. See the following table for details. |
volumeClaimTemplates | Automatically creates a separate disk for each replica pod. When you scale the StatefulSet, new pods get their own disks without manual PVC creation. |
Topology spread constraint fields
| Field | Value | Description |
|---|---|---|
maxSkew | 1 | The maximum difference in pod count between any two zones. For example, if you run 5 replicas across 3 zones, the distribution could be 2-2-1, but not 3-1-1. |
topologyKey | topology.kubernetes.io/zone | Spreads pods across availability zones. |
whenUnsatisfiable | ScheduleAnyway | If a perfectly even spread is not possible, the scheduler still places the pod (preferring the least-loaded zone) rather than leaving it in Pending state. Use DoNotSchedule if you require a strict even distribution and prefer a pending pod over an imbalanced one. |
For more information, see Topology Spread Constraints.
When a persistent volume (PV) is dynamically provisioned, the PV records the zone of the node where it was created. The PV and its bound PVC can only be used by pods in that same zone. This zone binding ensures disks are mounted successfully, but it also means a rescheduled pod must land in the same zone as its existing PV.
Common errors
Without the configurations described in this topic, you may encounter the following errors when deploying StatefulSets with disk volumes:
| Error | Cause |
|---|---|
InvalidDataDiskCatagory.NotSupported | The specified disk category is not available in the zone. For more information, see FAQ about disk volumes. |
The instanceType of the specified instance does not support this disk category | The ECS instance type hosting the pod does not support the disk category. |
0/x node are available, x nodes had volume node affinity conflict | The disk was provisioned in a different zone than the scheduled pod. |
References
For more information about how to enhance the data security of disk volumes, see Best practices for data security of disk volumes.
For more information about how to view real-time disk usage, see Overview of container storage monitoring.
For more information about how to resize a disk when the disk size does not meet your business requirements or the disk is full, see Expand disk volumes.
For more information about disk mounting issues, see FAQ about disk volumes.