The cloud-controller-manager component enables core Kubernetes components to interact with cloud service providers through the Kubernetes API. This topic describes the metrics for the cloud-controller-manager component, explains how to use its dashboard, and provides solutions to common metric anomalies.
Before you begin
Entry point
For more information, see View the monitoring dashboards for control plane components.
Metric list
Metrics expose the status and parameters of a component. The following table lists the metrics for the cloud-controller-manager component.
Metric | Type | Description |
ccm_slb_latency_ms | Histogram | The synchronization delay of a Classical Load Balancer (CLB). Unit: ms. The bucket thresholds are |
ccm_node_latency_ms | Histogram | The node synchronization delay. Unit: ms. The bucket thresholds are |
ccm_route_latency_ms | Histogram | The route synchronization delay. Unit: ms. The bucket thresholds are |
workqueue_adds_total | Counter | The number of Adds events processed by the workqueue. |
workqueue_depth | Gauge | The length of the workqueue. If the workqueue length remains at a high level for an extended period of time, the controller cannot process tasks in the workqueue in a timely manner, which results in task accumulation. |
workqueue_queue_duration_seconds_bucket | Histogram | The duration for which a task remains in the workqueue. The bucket thresholds are defined as the set {10-8, 10-7, 10-6, 10-5, 10-4, 10-3, 10-2, 10-1, 1, 10}. Unit: seconds. |
memory_utilization_byte | Gauge | The memory usage. Unit: bytes. |
cpu_utilization_core | Gauge | The used CPU capacity. Unit: core. |
rest_client_requests_total | Counter | The number of HTTP requests calculated based on status codes, methods, and hosts. |
rest_client_request_duration_seconds_bucket | Histogram | The HTTP response delay calculated based on Verbs and URLs. |
The following resource utilization metrics are deprecated. Remove any alerts and monitoring that depend on these metrics.
cpu_utilization_ratio: The CPU utilization.
memory_utilization_ratio: The memory usage.
Dashboard usage guide
The dashboards are created using component metrics and related Prometheus Query Language (PromQL) queries. The following sections describe the observability displays and features of the dashboards.
CCM
Observability display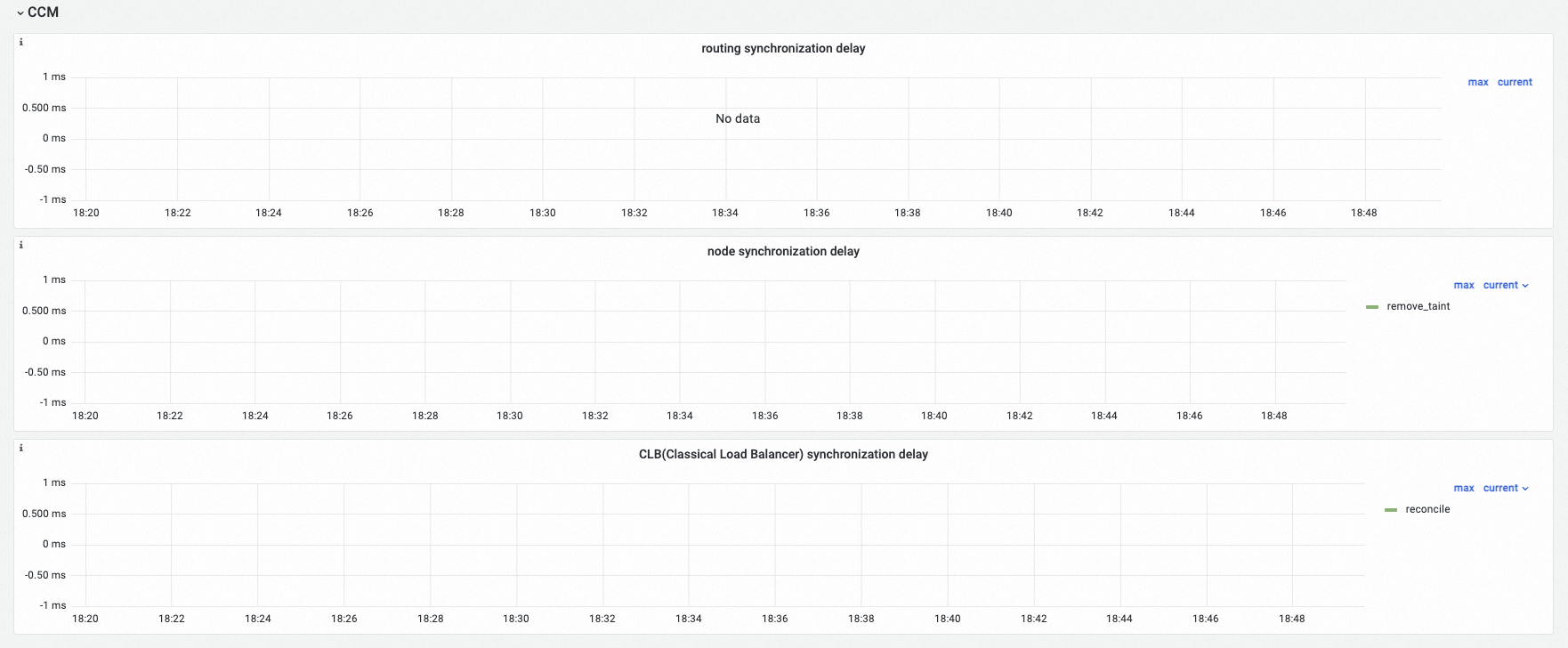
Feature description
Dashboard name | PromQL | Description |
Route Synchronization Delay | histogram_quantile($quantile, sum(rate(ccm_route_latencies_duration_milliseconds_bucket[$interval])) by (verb, le)) | The route synchronization delay. Unit: ms. |
Node Synchronization Delay | histogram_quantile($quantile, sum(rate(ccm_node_latencies_duration_milliseconds_bucket[$interval])) by (verb, le)) | The node synchronization delay. Unit: ms. |
CLB (Classical Load Balancer) Synchronization Delay | histogram_quantile($quantile, sum(rate(ccm_slb_latencies_duration_milliseconds_bucket[$interval])) by (verb, le)) | The CLB synchronization delay. Unit: ms. |
Queue
Observability display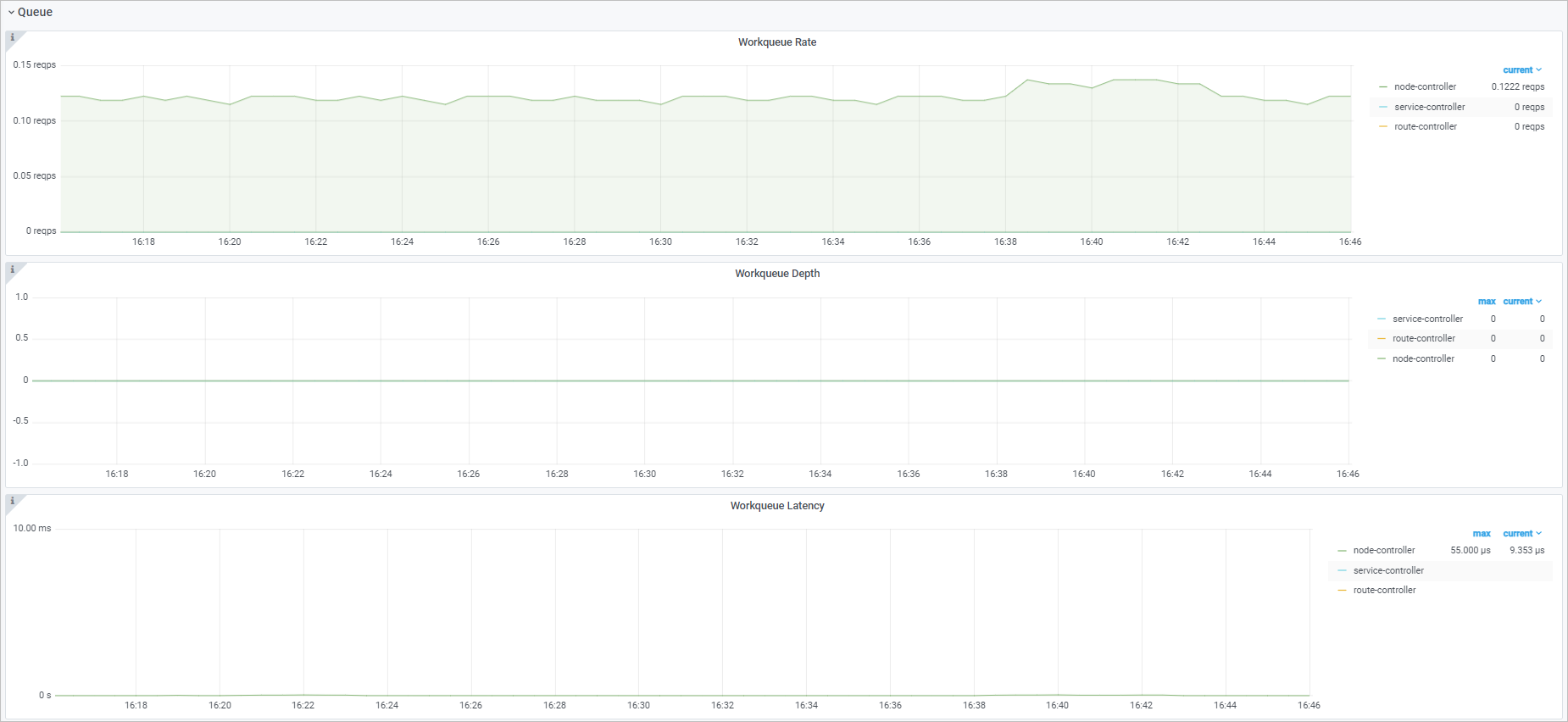
Feature description
Dashboard name | PromQL | Description |
Workqueue Enqueue Rate | sum(rate(workqueue_adds_total{job="ack-cloud-controller-manager"}[$interval])) by (name) | The number of Adds events that are added to the workflow in the specified interval. |
Workqueue Depth | workqueue_depth{job="ack-cloud-controller-manager"} | The change of the workqueue length in the specified interval. |
Workqueue Processing Delay | histogram_quantile($quantile, sum(rate(workqueue_queue_duration_seconds_bucket{job="ack-cloud-controller-manager"}[$interval])) by (name, le)) | The duration of the events in the workqueue. |
Resources
Observability display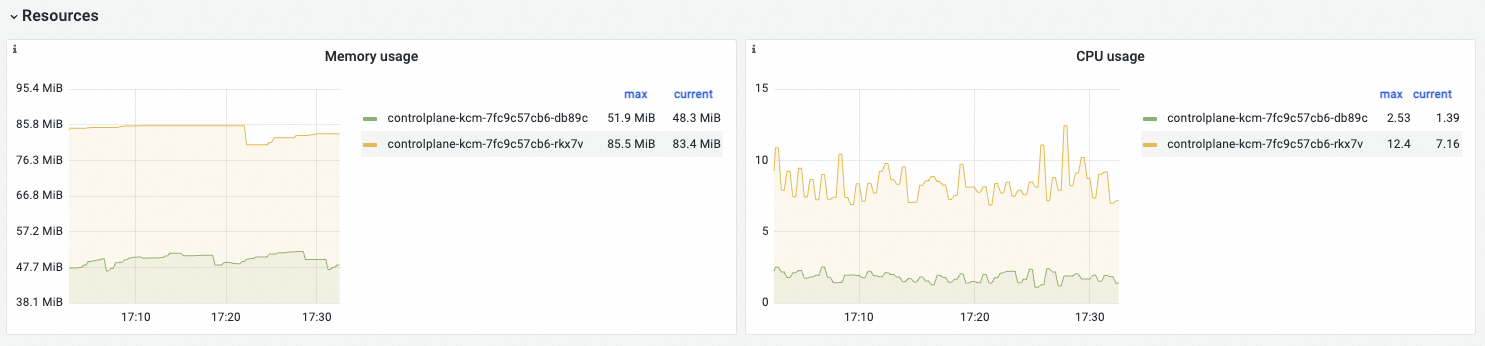
Feature description
Dashboard name | PromQL | Description |
Memory Usage | memory_utilization_byte{container="cloud-controller-manager"} | The memory usage. Unit: bytes. |
CPU Usage | cpu_utilization_core{container="cloud-controller-manager"}*1000 | The used CPU capacity. Unit: millicore. |
Kube API
Observability display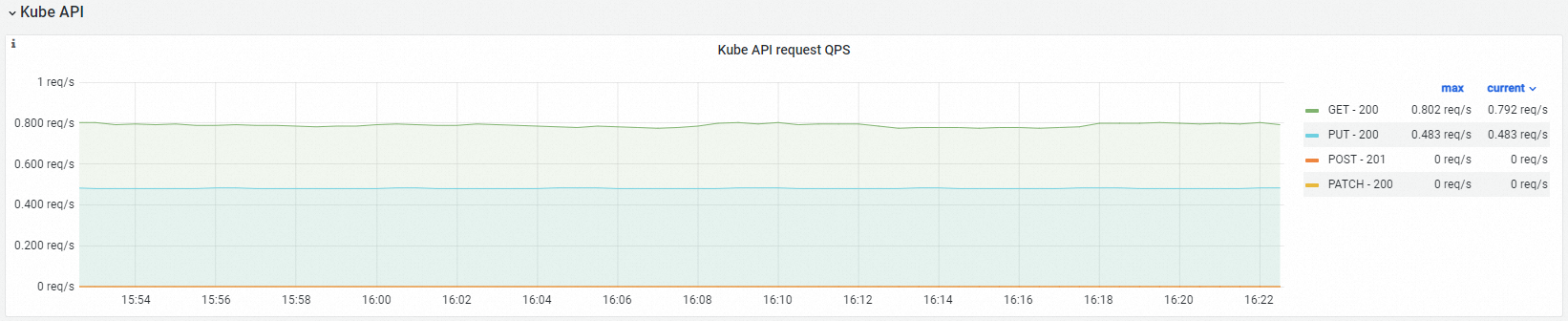
Feature description
Dashboard name | PromQL | Description |
Kube API Request QPS |
| The queries per second (QPS) of HTTP requests that the cloud-controller-manager sends to the kube-apiserver, analyzed by verb and request URL. |
Common metric anomalies
CLB (Classical Load Balancer) Synchronization Delay
Normal condition | Abnormal condition | Description | Suggestion |
The CLB (Classical Load Balancer) Synchronization Delay is within 10s. | The CLB (Classical Load Balancer) Synchronization Delay is greater than 10s. | The CLB synchronization takes too long. | Check for anomalous activity in the service. |
Workqueue Depth
Normal condition | Abnormal condition | Description | Suggestion |
The Workqueue Depth is less than 10. | The Workqueue Depth is greater than 10. | The work queue contains many services to be synchronized. | An excessively long queue slows down service synchronization. Reduce the frequency of changes to nodes, pods, and services in the cluster as needed. |
References
For more information about the metrics, dashboard usage guides, and common metric anomalies for other control plane components, see Metrics for the kube-apiserver component, Metrics for the etcd component, Metrics for the kube-scheduler component, and Metrics for the kube-controller-manager component.