Knative Pod Autoscaler (KPA) is an out-of-the-box feature that can scale pods based on the number of requests. This topic describes how to configure auto scaling based on the number of requests.
An ACK managed cluster or ACK Serverless cluster is created and Kubernetes version of the cluster is 1.20 or later. For more information, see Create an ACK managed cluster and Create an ACK Serverless cluster.
Knative is deployed in your cluster. For more information, see Deploy Knative.
How it works
Knative Serving injects a Queue Proxy container named queue-proxy into each pod. The container automatically reports the request concurrency metrics of application pods to KPA. After KPA receives the metrics, KPA automatically adjusts the number of pods provisioned for a Deployment based on the number of concurrent requests and the related algorithm.

Algorithm
KPA scales pods based on the average number of requests (or concurrent requests) received by each pod. By default, KPA scales pods based on the number of concurrent requests. Each pod can handle at most 100 requests concurrently. KPA also introduces the target utilization (target-utilization-percentage) annotation, which specifies a target utilization percentage value for auto scaling.
The following formula is used to calculate the target number of pods based on the number of concurrent requests: Number of pods = Number of concurrent requests/(Pod maximum concurrency × Target utilization).
For example, the pod maximum concurrency of an application is set to 10 and the target utilization is set to 0.7. When 100 concurrent requests are received, KPA creates 15 pods based on the following formula: 100/(0.7 × 10).
KPA also supports the stable and panic modes to perform fine-grained auto scaling.
Stable mode
In stable mode, KPA counts the average number of concurrent requests across pods within the stable window. The default stable window is 60 seconds. Then, KPA adjusts the number of pods based on the average concurrency value to maintain the loads at a stable level.
Panic mode
In panic mode, KPA counts the average number of concurrent requests across pods within the panic window. The default panic window is 6 seconds. The panic window is calculated based on the following formula: Panic window = Stable window × panic-window-percentage. The value of panic-window-percentage is greater than 0 and smaller than 1 and the default is 0.1. When a request burst occurs and the current pod utilization exceeds the panic window, KPA increases the number of pods to handle the burst.
KPA makes scaling decisions by checking whether the number of pods calculated in panic mode exceeds the panic threshold. The panic threshold is calculated based on the following formula: Panic threshold = panic-threshold-percentage/100. The default value of panic-threshold-percentage is 200. Therefore, the default panic threshold is 2.
If the number of pods calculated in panic mode is greater than or equal to twice the current number of ready pods, KPA scales the application to the number of pods calculated in panic mode. Otherwise, KPA scales the application to the number of pods calculated in stable mode.
KPA configurations
config-autoscaler
To configure KPA, you must configure config-autoscaler. By default, config-autoscaler is configured. The following content describes the key parameters.
Run the following command to query config-autoscaler:
kubectl -n knative-serving describe cm config-autoscalerExpected output (the default config-autoscaler ConfigMap):
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
# The default maximum concurrency of pods. The default value is 100.
container-concurrency-target-default: "100"
# The target utilization for concurrency. The default value is 70, which represents 0.7.
container-concurrency-target-percentage: "70"
# The default requests per second (RPS). The default value is 200.
requests-per-second-target-default: "200"
# The target burst capacity parameter is used to handle traffic bursts and prevent pod overloading. The default value is 211.
# The Activator service is used to receive and buffer requests when the target burst capacity is exceeded.
# If the target burst capacity parameter is set to 0, the Activator service is placed in the request path only when the number of pods is scaled to zero.
# If the target burst capacity parameter is set to a value greater than 0 and container-concurrency-target-percentage is set to 100, the Activator service is always used to receive and buffer requests.
# If the target burst capacity parameter is set to -1, the burst capacity is unlimited. All requests are buffered by the Activator service. If you set the target burst capacity parameter to other values, the parameter does not take effect.
# If the value of current number of ready pods × maximum concurrency - target burst capacity - concurrency calculated in panic mode is smaller than 0, the traffic burst exceeds the target burst capacity. In this scenario, the Activator service is placed to buffer requests.
target-burst-capacity: "211"
# The stable window. The default is 60 seconds.
stable-window: "60s"
# The panic window percentage. The default is 10, which indicates that the default panic window is 6 seconds (60 × 0.1).
panic-window-percentage: "10.0"
# The panic threshold percentage. The default is 200.
panic-threshold-percentage: "200.0"
# The maximum scale up rate, which indicates the maximum ratio of desired pods per scale-out activity. The value is calculated based on the following formula: math.Ceil(MaxScaleUpRate*readyPodsCount).
max-scale-up-rate: "1000.0"
# The maximum scale down rate. The default is 2, which indicates that pods are scaled to half of the current number during each scale-in activity.
max-scale-down-rate: "2.0"
# Specifies whether to scale the number of pods to zero. By default, this feature is enabled.
enable-scale-to-zero: "true"
# The graceful period before the number of pods is scaled to zero. The default is 30 seconds.
scale-to-zero-grace-period: "30s"
# The retention period of the last pod before the number of pods is scaled to zero. Specify this parameter if the cost for launching pods is high.
scale-to-zero-pod-retention-period: "0s"
# The type of the autoscaler. The following autoscalers are supported: KPA, HPA, AHA, and MPA. You can use MPA with Microservices Engine (MSE) in ACK Serverless clusters to scale the number of pods to zero.
pod-autoscaler-class: "kpa.autoscaling.knative.dev"
# The request capacity of the Activator service.
activator-capacity: "100.0"
# The number of pods to be initialized when a revision is created. The default is 1.
initial-scale: "1"
# Specifies whether no pod is initialized when a revision is created. The default is false, which indicates that pods are initialized when a revision is created.
allow-zero-initial-scale: "false"
# The minimum number of pods kept for a revision. The default is 0, which means that no pod is kept.
min-scale: "0"
# The maximum number of pods to which a revision can be scaled. The default is 0, which means that the number of pods to which a revision can be scaled is unlimited.
max-scale: "0"
# The scale down delay. The default is 0, which indicates a scale-in activity is performed immediately.
scale-down-delay: "0s"Metrics
You can use the autoscaling.knative.dev/metric annotation to configure metrics for a revision. Different autoscalers support different metrics.
Supported metrics:
"concurrency","rps","cpu","memory", and custom metrics.Default metric:
"concurrency".
Configure the concurrency metric
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/metric: "concurrency"Configure the RPS metric
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/metric: "rps"Configure the CPU metric
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/class: "hpa.autoscaling.knative.dev"
autoscaling.knative.dev/metric: "cpu"Configure the memory metric
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/class: "hpa.autoscaling.knative.dev"
autoscaling.knative.dev/metric: "memory"Configure a target
You can use the autoscaling.knative.dev/target annotation to configure a target for a revision. You can also use the container-concurrency-target-default annotation to configure a global target in a ConfigMap.
Configure a target for a revision
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: "50"Configure a global target
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
container-concurrency-target-default: "200"Configure scale-to-zero
Configure global scale-to-zero
The enable-scale-to-zero parameter specifies whether to scale the number of pods to zero when the specified Knative Service is idle. Valid values are "false" and "true".
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
enable-scale-to-zero: "false" # If the parameter is set to "false", the scale-to-zero feature is disabled. In this case, when the specified Knative Service is idle, pods are not scaled to zero.
Configure the graceful period for scale-to-zero
The scale-to-zero-grace-period parameter specifies the graceful period before the pods of the specified Knative Service are scaled to zero.
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
scale-to-zero-grace-period: "40s"Configure the retention period for scale-to-zero
Configure the retention period for a revision
The
autoscaling.knative.dev/scale-to-zero-pod-retention-periodannotation specifies the retention period of the last pod before the pods of a Knative Service are scaled to zero.apiVersion: serving.knative.dev/v1 kind: Service metadata: name: helloworld-go namespace: default spec: template: metadata: annotations: autoscaling.knative.dev/scale-to-zero-pod-retention-period: "1m5s" spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56Configure the global retention period
The
scale-to-zero-pod-retention-periodannotation specifies the global retention period of the last pod before the pods of a Knative Service are scaled to zero.apiVersion: v1 kind: ConfigMap metadata: name: config-autoscaler namespace: knative-serving data: scale-to-zero-pod-retention-period: "42s"
Configure the concurrency
The concurrency indicates the maximum number of requests that a pod can process concurrently. You can configure the concurrency by setting the soft concurrency limit, hard concurrency limit, target utilization, and RPS.
Configure the soft concurrency limit
The soft concurrency limit is a targeted limit rather than a strictly enforced bound. In some scenarios, particularly if a burst of requests occurs, the value may be exceeded.
Configure the soft concurrency limit for a revision
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: helloworld-go namespace: default spec: template: metadata: annotations: autoscaling.knative.dev/target: "200"Configure the global soft concurrency limit
apiVersion: v1 kind: ConfigMap metadata: name: config-autoscaler namespace: knative-serving data: container-concurrency-target-default: "200" # Specify a concurrency target for a Knative Service.
Configure the hard concurrency limit for a revision
We recommend that you specify the hard concurrency limit only if your application has a specific concurrency upper limit. Setting a low hard concurrency limit adversely affects the throughput and response latency of your application.
The hard concurrency limit is a strictly enforced limit. When the hard concurrency limit is reached, excess requests are buffered until sufficient resources can be used to handle the requests.
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
spec:
containerConcurrency: 50Target utilization
The target utilization specifies the actual percentage of the target of the autoscaler. You can also use the target utilization to adjust the concurrency value. The target utilization is also known as the hotness at which a pod runs. This causes the autoscaler to scale out before the specified hard concurrency limit is reached.
For example, if containerConcurrency is set to 10 and the target utilization is set to 70 (percentage), the autoscaler creates a pod when the average number of concurrent requests across all existing pods reaches 7. It takes a period of time for a pod to enter the Ready state after the pod is created. You can decrease the target utilization value to create new pods before the hard concurrency limit is reached. This helps reduce the response latency caused by cold starts.
Configure the target utilization for a revision
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: helloworld-go namespace: default spec: template: metadata: annotations: autoscaling.knative.dev/target-utilization-percentage: "70" # Configure the target utilization percentage. spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56Configure the global target utilization
apiVersion: v1 kind: ConfigMap metadata: name: config-autoscaler namespace: knative-serving data: container-concurrency-target-percentage: "70" # KPA attempts to ensure that the concurrency of each pod does not exceed 70% of the current resources.
Configure the RPS
The RPS specifies the number of requests that can be processed by a pod per second.
Configure the RPS for a revision
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: helloworld-go namespace: default spec: template: metadata: annotations: autoscaling.knative.dev/target: "150" autoscaling.knative.dev/metric: "rps" # The number of pods is adjusted based on the RPS value. spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56Configure the global RPS
apiVersion: v1 kind: ConfigMap metadata: name: config-autoscaler namespace: knative-serving data: requests-per-second-target-default: "150"
Scenario 1: Enable auto scaling by setting a concurrency target
This example shows how to enable KPA to perform auto scaling by setting a concurrency target.
For more information about how to deploy Knative, see Deploy Knative in an ACK cluster and Deploy Knative in an ACK Serverless cluster.
Create a file named autoscale-go.yaml and add the following content to the file:
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: autoscale-go namespace: default spec: template: metadata: labels: app: autoscale-go annotations: autoscaling.knative.dev/target: "10" # Set the concurrency target to 10. spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/autoscale-go:0.1Run the following command to deploy the autoscale-go.yaml file:
kubectl apply -f autoscale-go.yamlObtain the Ingress gateway.
ALB
Run the following command to obtain the Ingress gateway:
kubectl get albconfig knative-internetExpected output:
NAME ALBID DNSNAME PORT&PROTOCOL CERTID AGE knative-internet alb-hvd8nngl0lsdra15g0 alb-hvd8nng******.cn-beijing.alb.aliyuncs.com 2MSE
Run the following command to obtain the Ingress gateway:
kubectl -n knative-serving get ing stats-ingressExpected output:
NAME CLASS HOSTS ADDRESS PORTS AGE stats-ingress knative-ingressclass * 101.201.XX.XX,192.168.XX.XX 80 15dASM
Run the following command to obtain the Ingress gateway:
kubectl get svc istio-ingressgateway --namespace istio-system --output jsonpath="{.status.loadBalancer.ingress[*]['ip']}"Expected output:
121.XX.XX.XXKourier
Run the following command to obtain the Ingress gateway:
kubectl -n knative-serving get svc kourierExpected output:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kourier LoadBalancer 10.0.XX.XX 39.104.XX.XX 80:31133/TCP,443:32515/TCP 49mUse the load testing tool hey to send 50 concurrent requests to the application within 30 seconds.
NoteFor more information about hey, see hey.
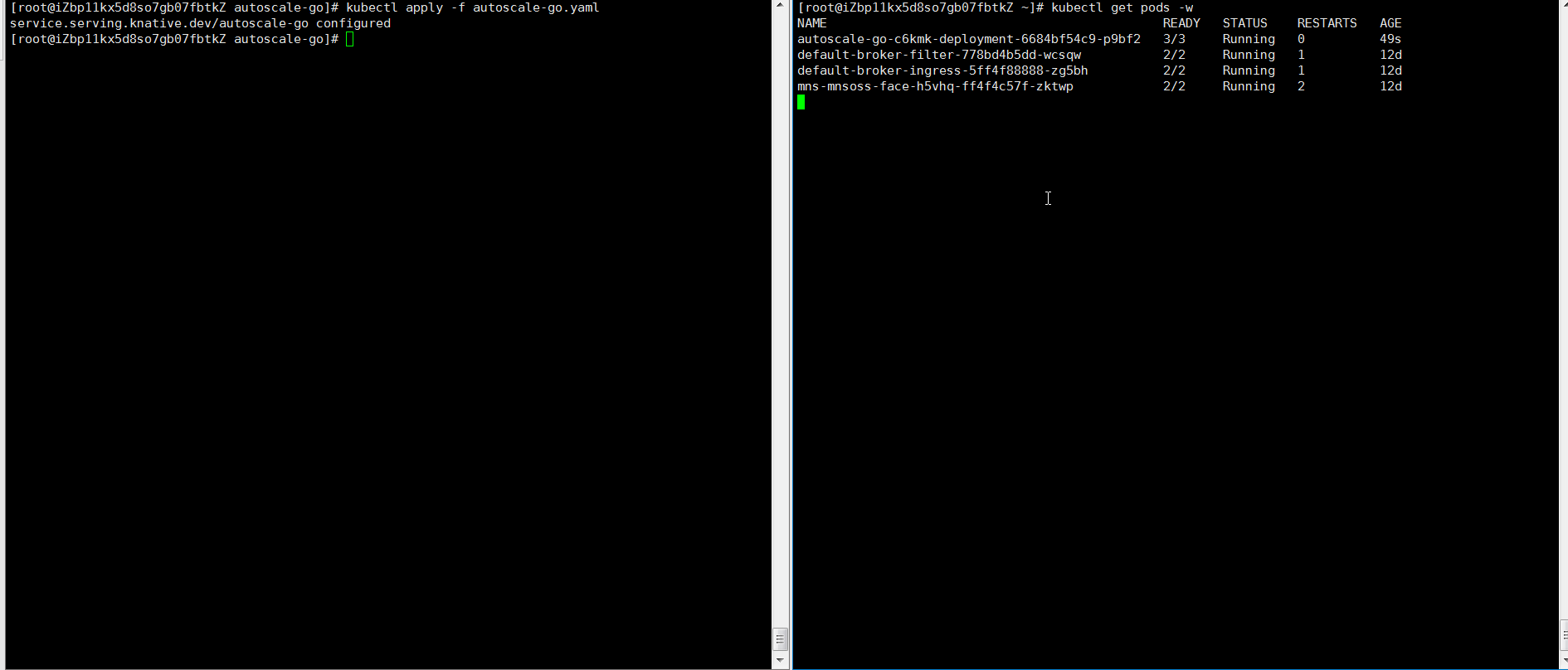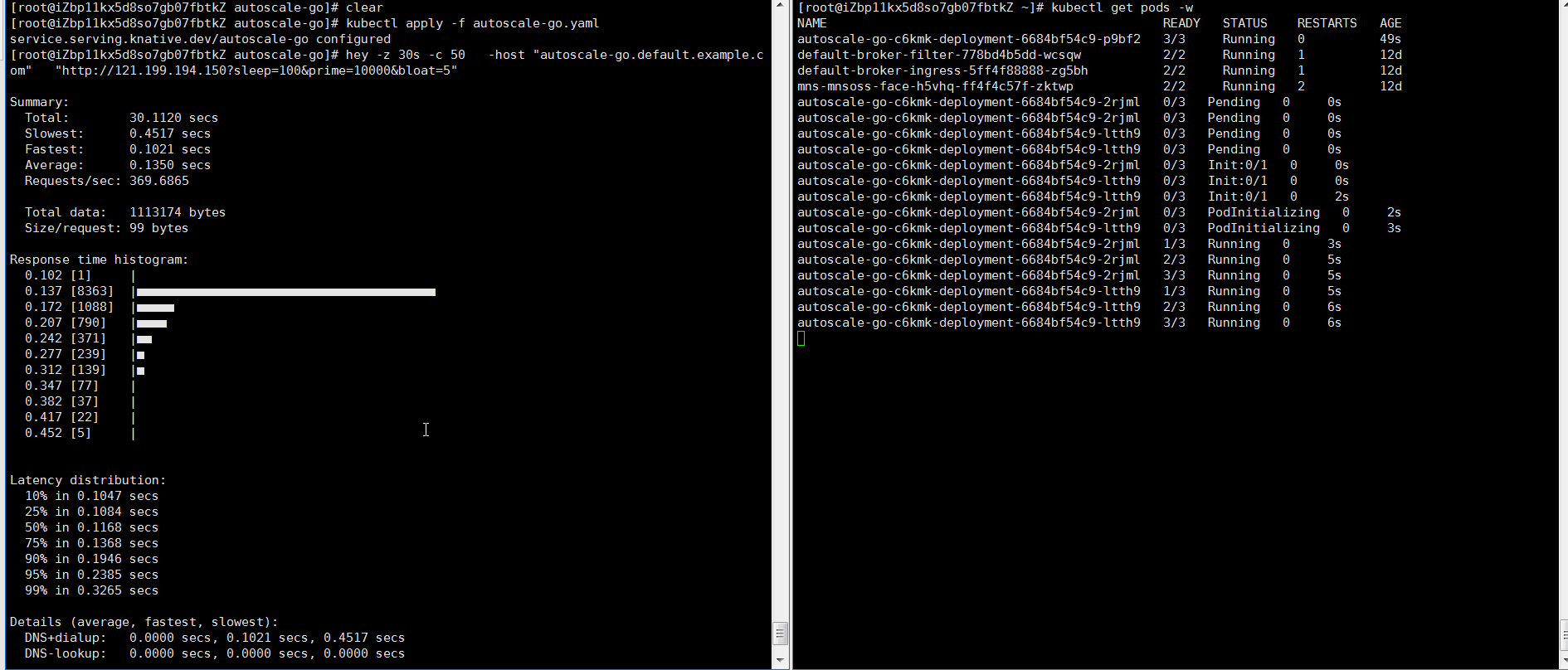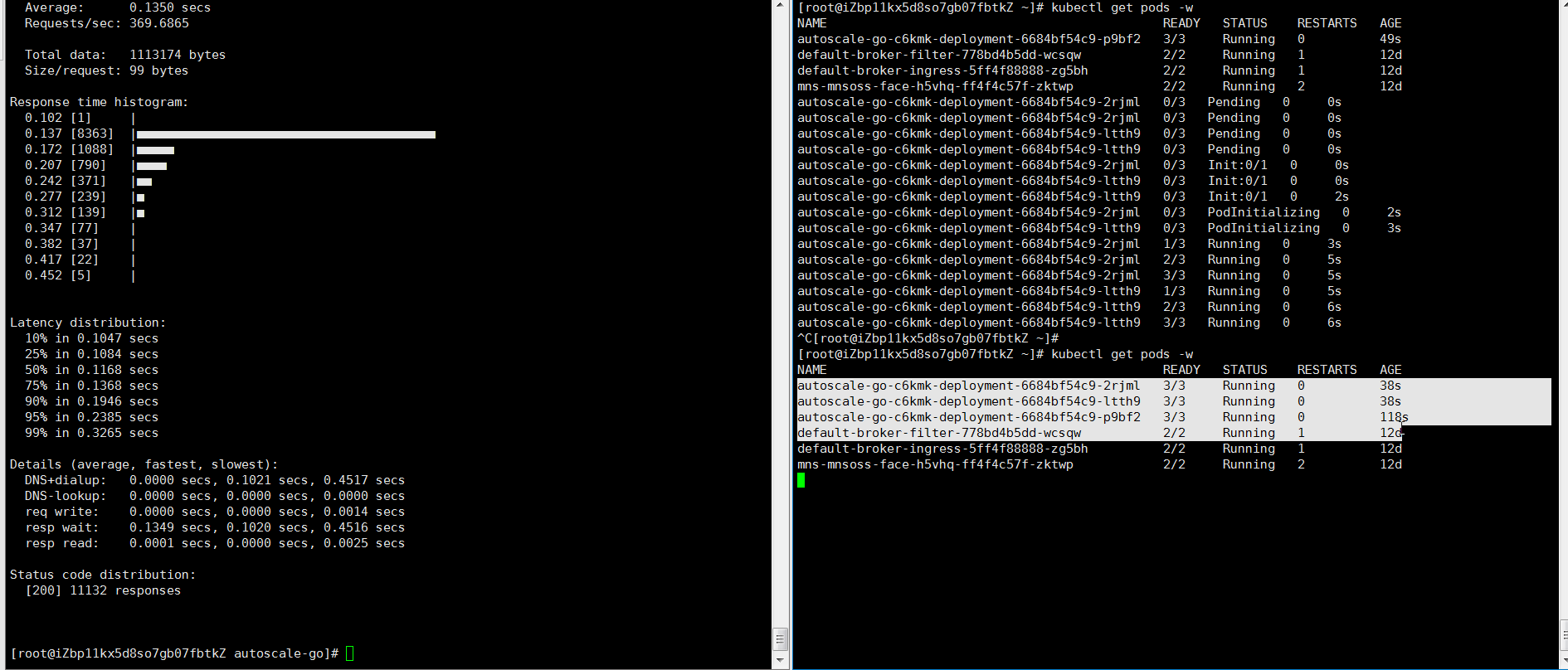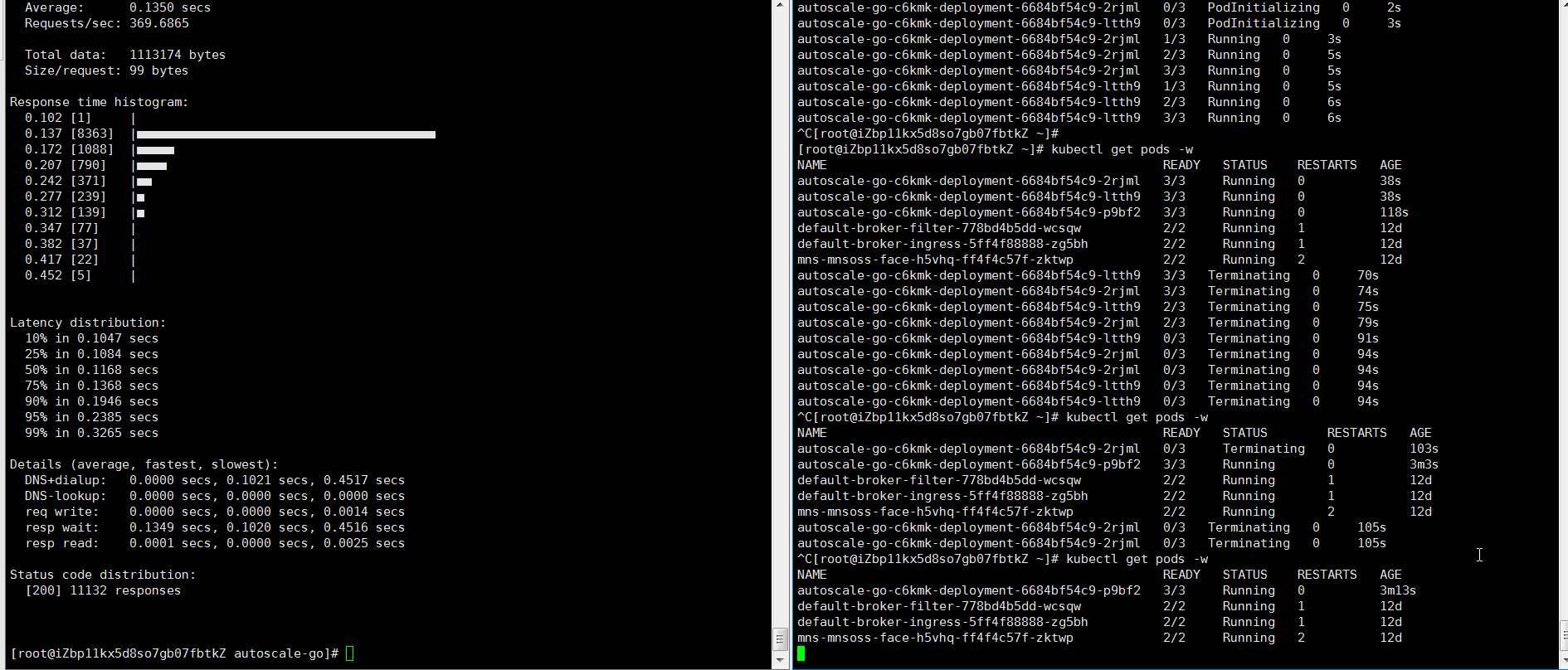
hey -z 30s -c 50 -host "autoscale-go.default.example.com" "http://121.199.XXX.XXX" # 121.199.XXX.XXX is the IP address of the Ingress gateway.Expected output:
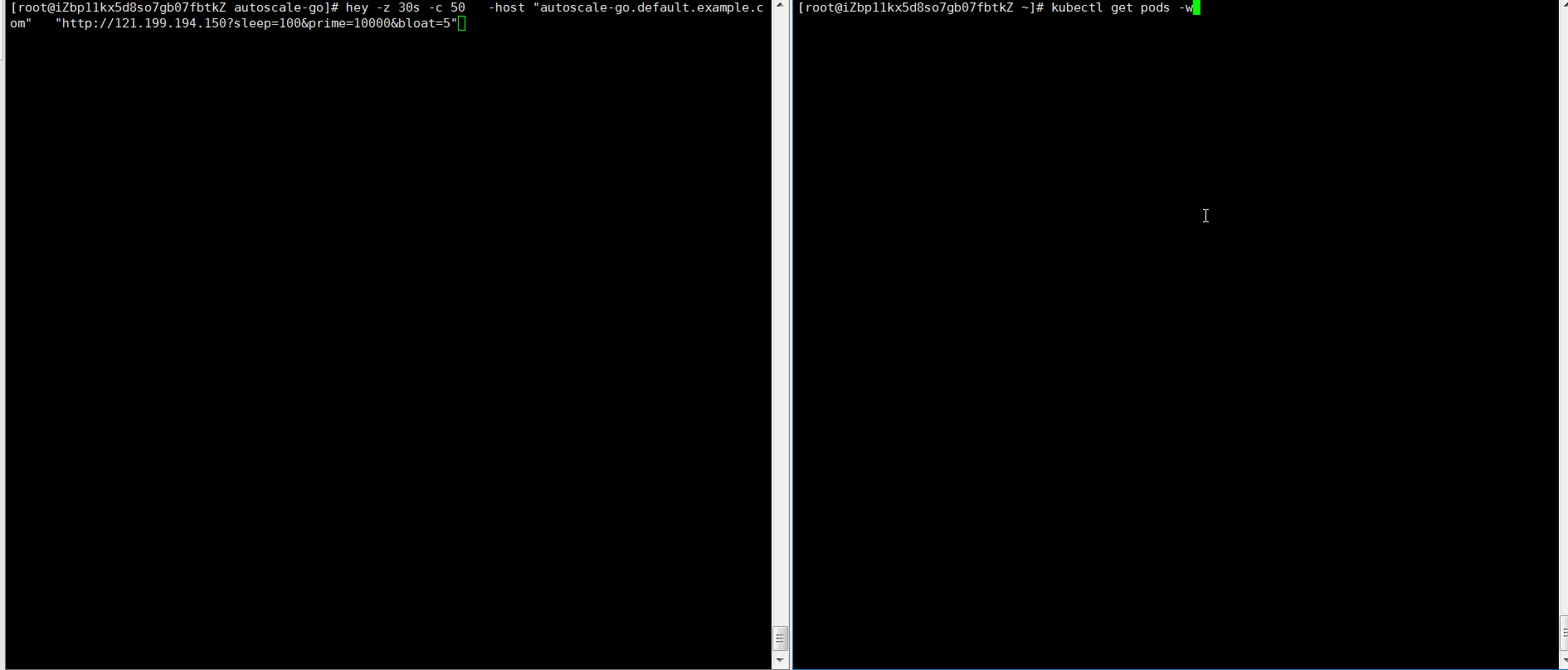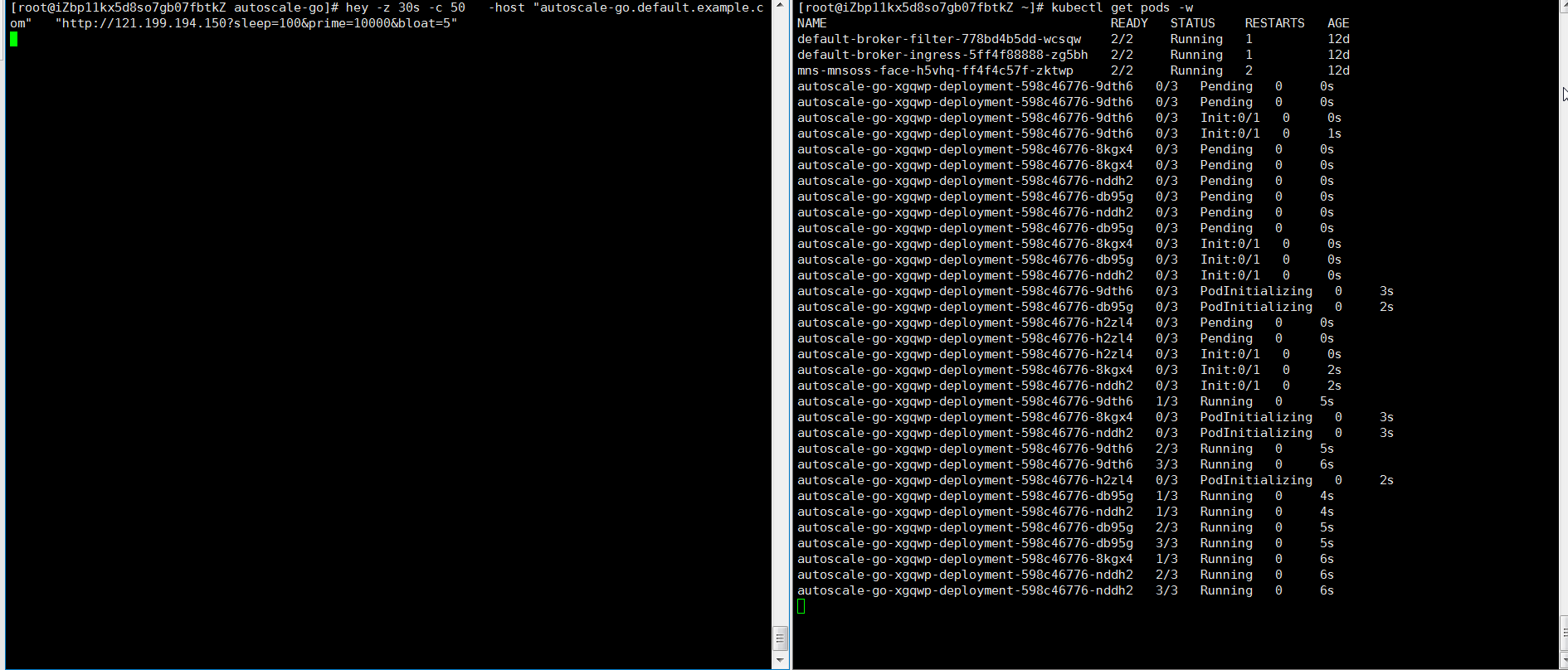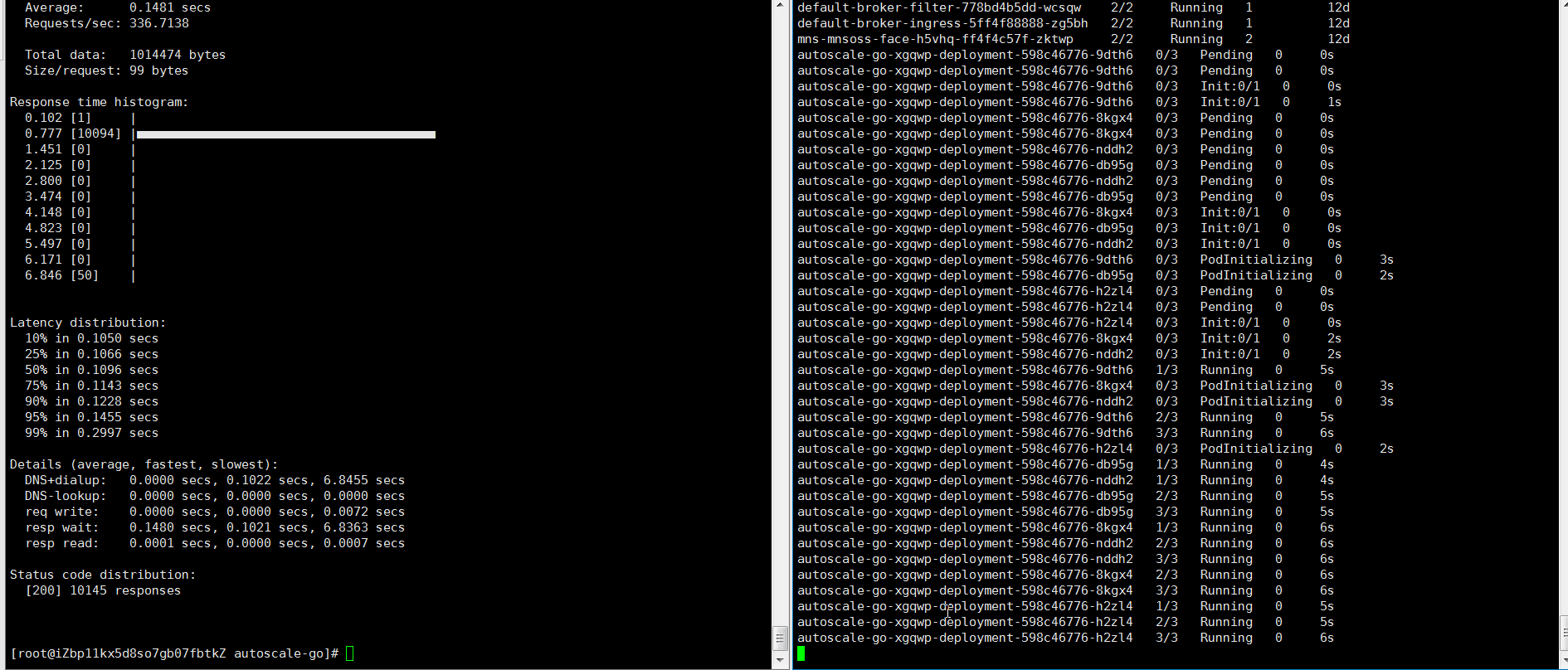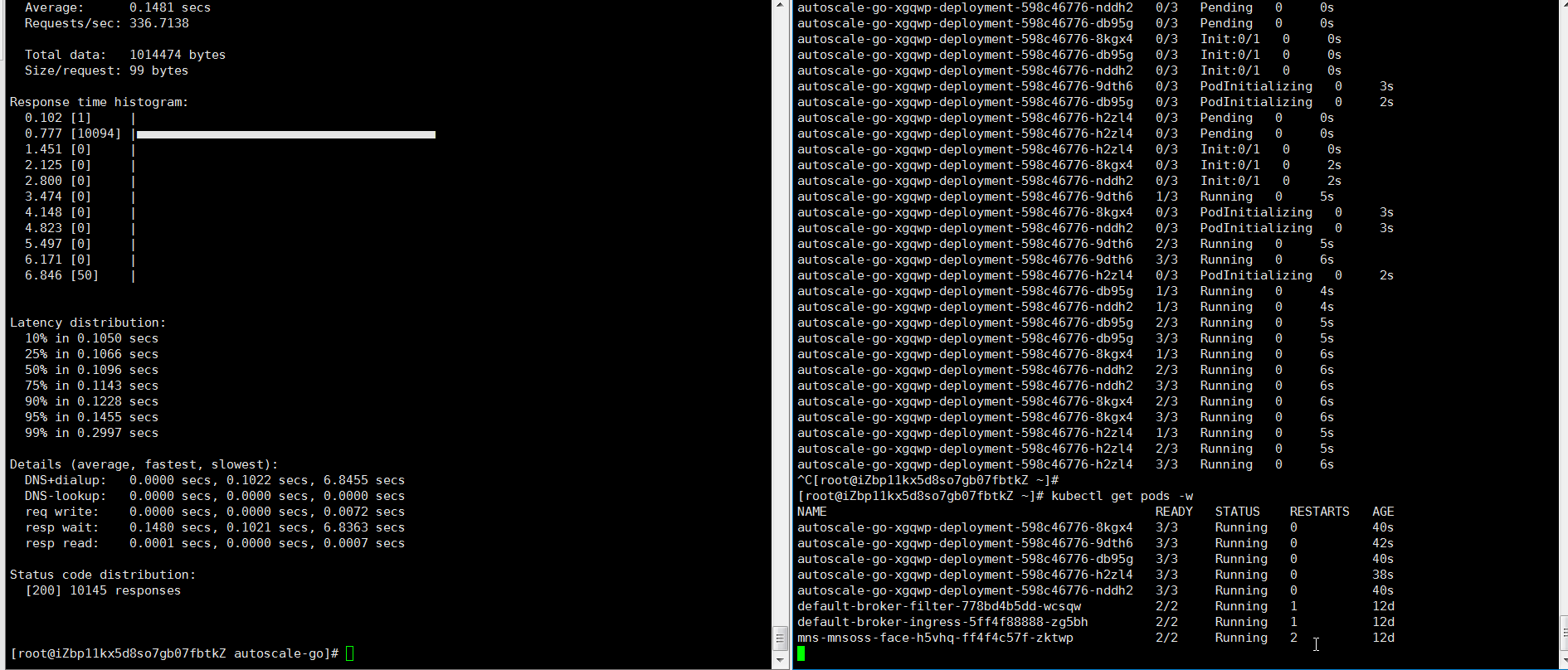
The output indicates that five pods are added.
Scenario 2: Enable auto scaling by setting scale bounds
Scale bounds control the minimum and maximum numbers of pods that can be provisioned for an application. This example shows how to enable auto scaling by setting scale bounds.
For more information about how to deploy Knative, see Deploy Knative in an ACK cluster and Deploy Knative in an ACK Serverless cluster.
Create a file named autoscale-go.yaml and add the following content to the file:
Set the concurrency target to 10,
min-scaleto 1, andmax-scaleto 3.apiVersion: serving.knative.dev/v1 kind: Service metadata: name: autoscale-go namespace: default spec: template: metadata: labels: app: autoscale-go annotations: autoscaling.knative.dev/target: "10" autoscaling.knative.dev/min-scale: "1" autoscaling.knative.dev/max-scale: "3" spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/autoscale-go:0.1Run the following command to deploy the autoscale-go.yaml file:
kubectl apply -f autoscale-go.yamlObtain the Ingress gateway.
ALB
Run the following command to obtain the Ingress gateway:
kubectl get albconfig knative-internetExpected output:
NAME ALBID DNSNAME PORT&PROTOCOL CERTID AGE knative-internet alb-hvd8nngl0lsdra15g0 alb-hvd8nng******.cn-beijing.alb.aliyuncs.com 2MSE
Run the following command to obtain the Ingress gateway:
kubectl -n knative-serving get ing stats-ingressExpected output:
NAME CLASS HOSTS ADDRESS PORTS AGE stats-ingress knative-ingressclass * 101.201.XX.XX,192.168.XX.XX 80 15dASM
Run the following command to obtain the Ingress gateway:
kubectl get svc istio-ingressgateway --namespace istio-system --output jsonpath="{.status.loadBalancer.ingress[*]['ip']}"Expected output:
121.XX.XX.XXKourier
Run the following command to obtain the Ingress gateway:
kubectl -n knative-serving get svc kourierExpected output:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kourier LoadBalancer 10.0.XX.XX 39.104.XX.XX 80:31133/TCP,443:32515/TCP 49mUse the load testing tool hey to send 50 concurrent requests to the application within 30 seconds.
NoteFor more information about hey, see hey.
hey -z 30s -c 50 -host "autoscale-go.default.example.com" "http://121.199.XXX.XXX" # 121.199.XXX.XXX is the IP address of the Ingress gateway.Expected output:
At most three pods are added. One pod is reserved when no traffic flows to the application.