CoreDNS is the default plug-in used to implement Domain Name System (DNS)-based service discovery in Container Service for Kubernetes (ACK) clusters. This topic describes how to view the CoreDNS dashboard and introduces the metrics on the dashboard. This topic also describes how to troubleshoot errors based on abnormal metric values.
Prerequisites
Application Real-Time Monitoring Service (ARMS) is activated.
The ack-arms-prometheus component is installed. For more information, see Manage components.
View the CoreDNS dashboard
Log on to the ACK console. In the navigation pane on the left, click Clusters.
On the Clusters page, find the cluster you want and click its name. In the left-side pane, choose .
On the Prometheus Monitoring page, click the Network Monitoring tab. On the CoreDNS tab, you can view the CoreDNS dashboard.
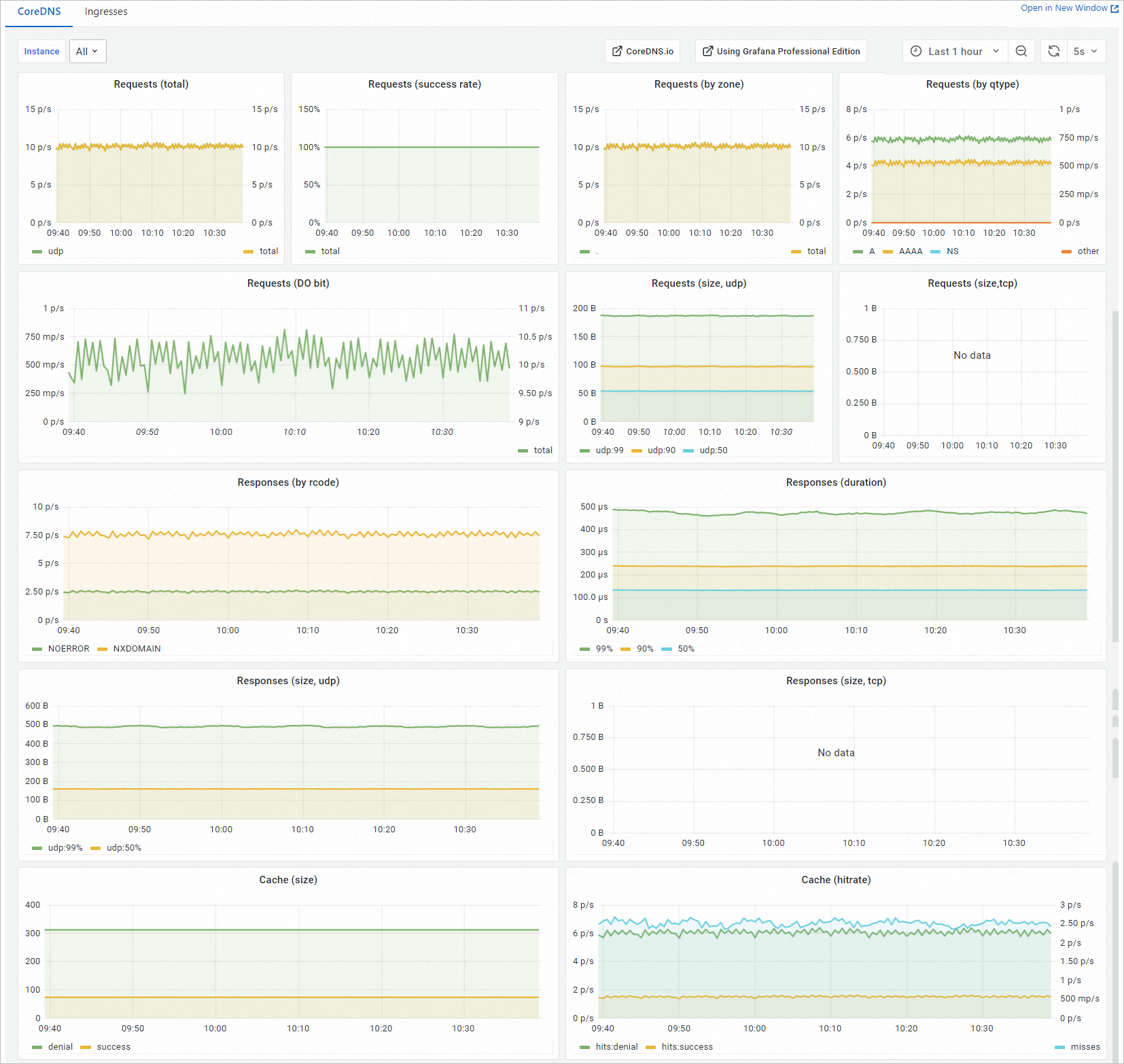
Dashboard description
The CoreDNS dashboard is generated based on metrics and Prometheus Query Language (PromQL) and displays information about requests, responses, and data caching. The following table describes the metrics on the dashboard.
Metric | Unit | Description |
Requests (total) | Requests/s | The number of requests received by CoreDNS per second. |
Requests (success rate) | % | The success rate of requests received by CoreDNS. Note If the response code NXDOMAIN or NOERROR is returned, the request is considered successful. |
Requests (by zone) | Requests/s | The number of requests received by CoreDNS per second for each zone. |
Requests (by qtype) | Requests/s | The number of requests received by CoreDNS per second for each resolution type. |
Requests (DO bit) | Requests/s | The number of requests received by CoreDNS per second. Only requests that contain the DO bit are counted. |
Requests (size, udp) | Bytes | The size of each UDP packet received by CorDNS. |
Requests (size,tcp) | Bytes | The size of each TCP packet received by CorDNS. |
Responses (by rcode) | Requests/s | The number of responses for each response code. |
Responses (duration) | Seconds | The response time at the 99th percentile, 90th percentile, and 50th percentile. |
Responses (size, udp) | Bytes | The response packet size for UDP requests at the 99th percentile and 50th percentile. |
Responses (size, tcp) | Bytes | The response packet size for TCP requests at the 99th percentile and 50th percentile. |
Cache (size) | N/A | The number of caches. |
Cache (hitrate) | % | The buffer hit ratio. |
Common anomalies
Anomaly | Description |
The number of requests received by CoreDNS sharply increases. | You can view the number of requests received by CoreDNS in the Requests (total) chart on the dashboard. If the number of requests received by CoreDNS sharply increases, you can check the most frequently accessed domain names in the log of CoreDNS. Then, you can determine whether the request increase is normal. For more information about how to analyze and monitor the log of CoreDNS, see Collect and analyze CoreDNS logs. If the request increase is normal, we recommend that you create more pods for CoreDNS and use NodeLocal DNSCache to improve DNS performance. For more information, see Ensure the high availability of CoreDNS and Configure NodeLocal DNSCache. |
Errors occurred on the DNS server and the number of responses with the response code ServFail is large. | You can view the number of responses with the response code ServFail in the Responses (by rcode) chart on the dashboard. If the number of responses with the response code ServFail is large, we recommend that you check the log of CoreDNS and troubleshoot the relevant domain names. For more information about how to analyze and monitor the log of CoreDNS, see Collect and analyze CoreDNS logs. |
The response time of CoreDNS is long. | You can view the response time in the Responses (duration) chart on the dashboard. If a large number of applications use external domain names, the response time of CoreDNS may be long. |
Metrics
If you do not enable Application Real-Time Monitoring Service (ARMS) to generate the CoreDNS dashboard, you can monitor CoreDNS in a self-managed Prometheus instance. The following table describes the CoreDNS metrics.
The following table describes the metrics of CoreDNS 1.9.3. For more information, see CoreDNS official documentation.
Metric | Data type | Description |
requests_total | Counter | The number of DNS queries from the following aspects: server, zone, proto, family, and type. |
request_duration_seconds | Histogram | The response time from the following aspects: server and zone. |
request_size_bytes | Histogram | The size of DNS queries from the following aspects: server, zone, and proto. The thresholds of Histogram Bucket include 0, 100, 200, 300, 400, 511, 1023, 2047, 4095, 8291, 16e3, 32e3, 48e3, 64e3. Unit: seconds. |
do_requests_total | Counter | The number of DNS queries that include the DO bit from the following aspects: server and zone. |
response_size_bytes | Histogram | The packet size of DNS responses from the following aspects: server, zone, and proto. The thresholds of Histogram Bucket include 0, 100, 200, 300, 400, 511, 1023, 2047, 4095, 8291, 16e3, 32e3, 48e3, 64e3. Unit: seconds. |
responses_total | Counter | The number of DNS responses from the following aspects: server, zone, rcode, and plugin. |
panics_total | Counter | The number of panics that occur on CoreDNS. |
plugin_enabled | Gauge | Indicates whether a plug-in is enabled from the following aspects: server, zone, and name. |
https_responses_total | Counter | The number of DNS queries over HTTPS (DoH) from the following aspects: server and status. |