Container Service for Kubernetes (ACK) supports Kubernetes-based Event Driven Autoscaling (KEDA). You can install KEDA in the ACK console to implement event-driven scaling for clusters. This topic describes what KEDA is, how KEDA works, and how to use KEDA.
Overview
For Kubernetes, Horizontal Pod Autoscaler (HPA) is the most commonly used solution for automatically scaling pods. HPA determines scaling strategies based on the differences between the resource usage and predefined thresholds. HPA is an easy-to-use tool that supports various resource metrics. However, it does not support real-time scaling. For example, HPA cannot scale resources when specific events are detected. To address this issue, you can install KEDA in the ACK console. ACK KEDA supports event-driven scaling that can be used in various event-driven scenarios, such as offline video and audio transcoding, event-driven jobs, and stream processing.
How KEDA works
ACK KEDA is an enhanced version of the open source KEDA. It supports event-driven scaling. The following figure shows how ACK KEDA works.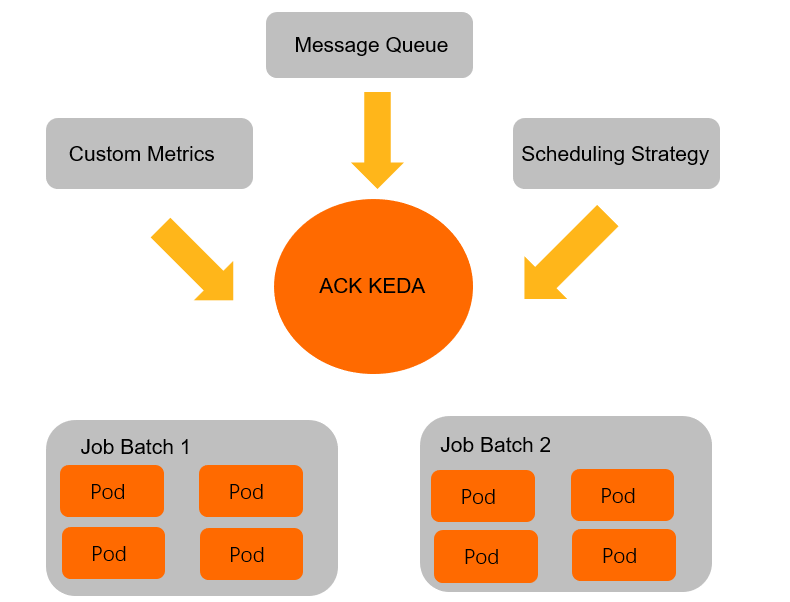
ACK KEDA periodically consumes data from event sources. When pending messages increase, ACK KEDA is triggered to scale a batch of jobs within seconds. After the next period starts, the next batch of jobs is asynchronously scaled. ACK KEDA supports the following features:
Supports various event sources
ACK KEDA supports various data sources, such as Kafka, MySQL, PostgreSQL, RabbitMQ, and MongoDB. For more information, see RabbitMQ Queue.
Controls the concurrency of jobs
When a large number of jobs are submitted, the stability of the underlying control system is adversely affected because the system must holistically control resources, quotas, and API requests. ACK KEDA can control the concurrency of jobs in one or more batches to ensure system stability.
Clears metadata after jobs are completed
A large amount of metadata is retained after a large number of jobs are completed. The increase of metadata degrades the stability of the API server. The performance and stability of the cluster are also degraded and other services may be adversely affected. ACK KEDA can automatically clear metadata after jobs are completed.
Case study
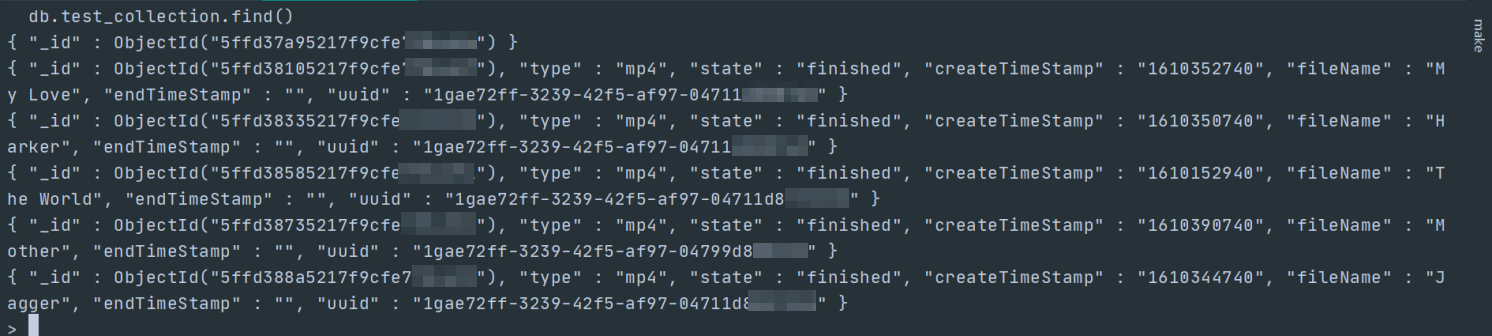
A simple transcoding job is used in the following case. When a new job is received, data similar to the following example is inserted into MongoDB: {"type":"mp4","state":"waiting","createTimeStamp":"1610332940","fileName":"World and peace","endTimeStamp":"","uuid":"1fae72ff-3239-42f5-af97-04711d8007e8"}. ACK KEDA searches the database for data entries that meet the "state":"waiting" condition. Then, ACK KEDA creates pods to process the data entries. One pod is created for each data entry. After the transcoding is completed, the value of the state field changes from waiting to finished. After the job is completed, the metadata is automatically cleared to reduce the load on the API server. This allows you to manage jobs in a convenient manner.
Step 1: Deploy ACK KEDA
Log on to the ACK console.
In the left-side navigation pane of the ACK console, choose .
On the Marketplace page, find and click ack-keda.
Click Deploy in the upper-right corner of the ack-keda page. In the Basic Information step, select a cluster, and click Next.
In the Parameters step, select a chart version and click OK.
In the left-side navigation pane, click Clusters. On the Clusters page, select the cluster where ACK KEDA is deployed and click the cluster name or click Details in the Actions column. In the left-side navigation pane, choose to view ACK KEDA.
Step 2: Add MongoDB as an event source
Deploy MongoDB.
If you already deployed MongoDB, skip this step.
ImportantThe database is used only for testing purposes. Do not use the database in production environments.
Create a YAML file named mongoDB.yaml and add the following code to the file:
apiVersion: apps/v1 kind: Deployment metadata: name: mongodb spec: replicas: 1 selector: matchLabels: name: mongodb template: metadata: labels: name: mongodb spec: containers: - name: mongodb image: mongo:4.2.1 imagePullPolicy: IfNotPresent ports: - containerPort: 27017 name: mongodb protocol: TCP --- kind: Service apiVersion: v1 metadata: name: mongodb-svc spec: type: ClusterIP ports: - name: mongodb port: 27017 targetPort: 27017 protocol: TCP selector: name: mongodbDeploy MongoDB to the mongodb namespace of the cluster.
kubectl apply -f mongoDB.yaml -n mongodb
Log on to MongoDB and create a user account.
Create a user.
# Create a user kubectl exec -n mongodb mongodb-xxxxx -- mongo --eval 'db.createUser({ user:"test_user",pwd:"test_password",roles:[{ role:"readWrite", db: "test"}]})'Log on to MongoDB.
# Complete authentication kubectl exec -n mongodb mongodb-xxxxx -- mongo --eval 'db.auth("test_user","test_password")'Create a collection.
# Create a collection kubectl exec -n mongodb mongodb-xxxxx -- mongo --eval 'db.createCollection("test_collection")'
Deploy TriggerAuthentication and ScaledJob.
ACK KEDA uses TriggerAuthentication to authenticate logon requests to event sources. In this case, MongoDB is added as an event source. ACK KEDA uses the
secretTargetReffield in TriggerAuthentication to retrieve the connection information from the specified Secret and then uses the connection information to authenticate requests to MongDB.Create a YAML file named auth.yaml and add the following code to the file:
apiVersion: keda.sh/v1alpha1 kind: TriggerAuthentication metadata: name: mongodb-trigger spec: secretTargetRef: - parameter: connectionString name: mongodb-secret key: connect --- apiVersion: v1 kind: Secret metadata: name: mongodb-secret type: Opaque data: connect: bW9uZ29kYjovL3Rlc3RfdXNlcjp0ZXN0X3Bhc3N3b3JkQG1vbmdvZGItc3ZjLm1vbmdvZGIuc3ZjLmNsdXN0ZXIubG9jYWw6MjcwMTcvdGVzdA==Deploy TriggerAuthentication to the mongodb-test namespace of the cluster.
kubectl apply -f auth.yaml -n mongodb-test
Deploy ScaledJob.
ScaledJob is used to define the job template and specify the database to be queried and the query expression. In the following example, a job is created to query the test_collection collection in the test database and transcode data entries that meet the
{"type":"mp4","state":"waiting"}condition.Create a YAML file named scaledJob.yaml and add the following code to the file:
apiVersion: keda.sh/v1alpha1 kind: ScaledJob metadata: name: mongodb-job spec: jobTargetRef: # Job template template: spec: containers: - name: mongo-update image: registry.cn-hangzhou.aliyuncs.com/carsnow/mongo-update:v6 args: - --connectStr=mongodb://test_user:test_password@mongodb-svc.mongodb.svc.cluster.local:27017/test - --dataBase=test - --collection=test_collection imagePullPolicy: IfNotPresent restartPolicy: Never backoffLimit: 1 pollingInterval: 15 maxReplicaCount: 5 successfulJobsHistoryLimit: 0 failedJobsHistoryLimit: 10 triggers: - type: mongodb metadata: dbName: test # The database to be queried. collection: test_collection # The collection to be queried. query: '{"type":"mp4","state":"waiting"}' # Create a job to process each data entry whose type is mp4 and state is waiting. queryValue: "1" authenticationRef: name: mongodb-triggerquery: Set a condition. When ACK KEDA detects data entries that meet the specified condition, jobs are started.Deploy ScaledJob to the mongodb-test namespace of the cluster.
kubectl apply -f scaledJob.yaml -n mongodb-test
Insert five data entries to MongoDB.
# Insert five data entries to MongoDB kubectl exec -n mongodb mongodb-xxxxx -- mongo --eval 'db.test_collection.insert([ {"type":"mp4","state":"waiting","createTimeStamp":"1610352740","fileName":"My Love","endTimeStamp":"","uuid":"1gae72ff-3239-42f5-af97-04711d8007e8"}, {"type":"mp4","state":"waiting","createTimeStamp":"1610350740","fileName":"Harker","endTimeStamp":"","uuid":"1gae72ff-3239-42f5-af97-04711d8007e8"}, {"type":"mp4","state":"waiting","createTimeStamp":"1610152940","fileName":"The World","endTimeStamp":"","uuid":"1gae72ff-3239-42f5-af97-04711d87767e8"}, {"type":"mp4","state":"waiting","createTimeStamp":"1610390740","fileName":"Mother","endTimeStamp":"","uuid":"1gae72ff-3239-42f5-af97-04799d8007e8"}, {"type":"mp4","state":"waiting","createTimeStamp":"1610344740","fileName":"Jagger","endTimeStamp":"","uuid":"1gae72ff-3239-42f5-af97-04711d80099e8"}, ])'
Step 3: Check whether ACK KEDA works as expected
Run the following command to query jobs:
# watch job
watch -n 1 kubectl get job -n mongodb-test
Verify that five jobs are created. Log on to MongoDB and check the inserted data. Verify that the status of each data entry that you inserted changes from waiting to finished.