使用EMR的JindoFS缓存模式连接OSS数据湖。
背景信息
您可以使用EMR的JindoFS缓存模式或者JindoFS块模式连接OSS数据湖。
缓存模式(Cache)主要兼容原生OSS存储方式,文件以对象的形式存储在OSS上,每个文件根据实际访问情况会在本地进行缓存,提升EMR集群内访问OSS的效率,同时兼容了OSS原有文件形式,数据访问上能够与其他OSS客户端完全兼容。详情请参见JindoFS缓存模式使用说明。
块存储模式(Block)提供了最为高效的数据读写能力和元数据访问能力。数据以Block形式存储在后端存储OSS上,本地提供缓存加速,元数据则由本地Namespace服务维护,提供高效的元数据访问性能。详情请参见JindoFS块存储模式使用说明。
前提条件
操作步骤
使用EMR的jindoFS缓存模式连接OSS和启用缓存,详情请参见JindoFS缓存模式使用说明。
启用缓存会利用本地磁盘对访问的热数据块进行缓存,默认状态为禁用,即所有OSS读取都直接访问OSS上的数据。缓存启用后,Jindo服务会自动管理本地缓存备份,通过水位清理本地缓存,请根据需求配置一定的比例用于缓存。
启动spark SQL。
通过远程登录工具(例如PuTTY)登录EMR Header服务器。
执行如下命令运行Spark SQL。
spark-sql --master yarn --num-executors 5 --executor-memory 1g --executor-cores 2
使用SQL语句创建指向OSS数据目录的外表。
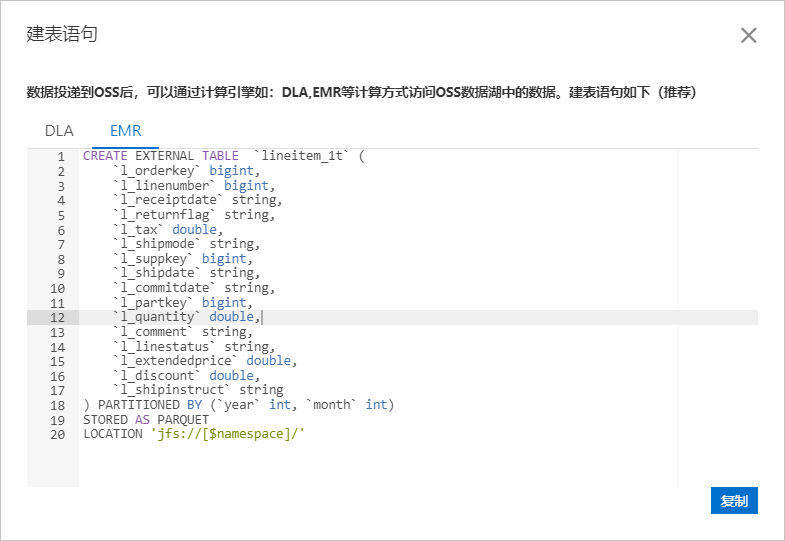
请使用通过表格存储控制台获取的SQL语句,如下SQL语句示例仅供参考。
CREATE EXTERNAL TABLE lineitem (l_orderkey bigint,l_linenumber bigint,l_receiptdate string,l_returnflag string,l_tax double,l_shipmode string,l_suppkey bigint,l_shipdate string,l_commitdate string,l_partkey bigint,l_quantity double,l_comment string,l_linestatus string,l_extendedprice double,l_discount double,l_shipinstruct string) PARTITIONED BY (`year` int, `month` int) STORED AS PARQUET LOCATION 'jfs://test/' ;
通过表格存储控制台获取SQL语句的方法如下:
在实例的数据湖投递页面,单击投递任务操作列的建表语句,可以查看和复制SQL语句,如下图所示。
执行如下SQL语句,加载OSS数据源中实际的数据分区。
其中lineitem为创建的外表名称。
msck repair table lineitem;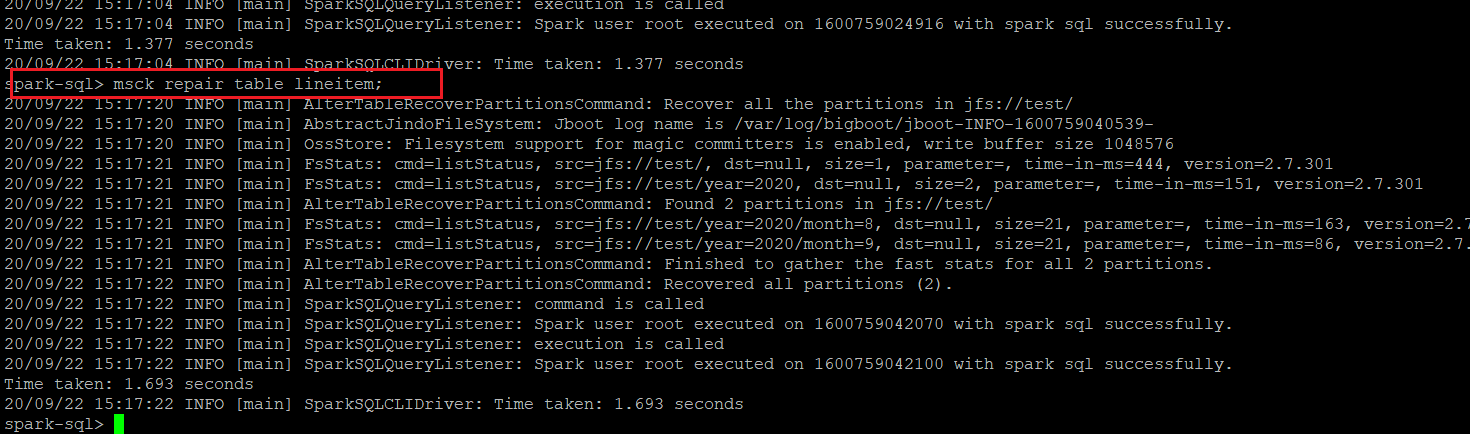
查询数据。
select * from lineitem limit 1;