本文介绍事件操作函数的语法规则,包括参数解释、函数示例等。
函数列表
类型 | 函数 | 说明 |
事件操作 | 根据条件判断是否丢弃日志。 支持和其他函数组合使用。相关示例,请参见复制和分发数据。 | |
根据条件判断是否保留日志。 e_keep函数和e_drop函数都会丢弃日志。e_keep函数在不满足条件时丢弃,而e_drop函数则是在满足条件时丢弃。 支持和其他函数组合使用。相关示例,请参见复杂JSON数据加工。 | ||
事件分裂 | 基于日志字段的值分裂出多条日志,并且支持通过JMES提取字段后再进行分裂。 支持和其他函数组合使用。相关示例,请参见复杂JSON数据加工。 | |
输出事件 | 输出日志到指定的LogStore中,并可配置输出时的topic、source、tag和shard hash信息。
支持和其他函数组合使用。相关示例,请参见将不同LogStore的日志数据汇总到一个LogStore。 | |
事件转换成时序数据 | 将日志格式转化为时序存储(MetricStore)的格式。 说明 加工为时序数据格式后,保存加工结果时请选择目标库为时序库。 典型的时序数据如下所示: 更多信息,请参见时序数据(Metric)。 支持和其他函数组合使用。相关示例,请参见将LogStore中的日志字段转换MetricStore中的度量指标。 |
e_drop
根据条件判断是否丢弃日志。
函数格式
e_drop(condition=True)支持固定标识DROP,等价于e_drop()。
参数说明
参数名称
参数类型
是否必填
说明
condition
Bool
否
默认为True,一般传递一个条件判断函数的结果。
返回结果
满足条件则丢弃日志并返回None,否则返回原日志。
函数示例
示例1:当__programe__字段的值为access时丢弃日志,否则保留该日志。
原始日志
__programe__: access age: 18 content: 123 name: maki __programe__: error age: 18 content: 123 name: maki加工规则
e_if(e_search("__programe__==access"), DROP)加工结果
丢弃__programe__字段值为access的日志,保留__programe__字段的值为error的日志。
__programe__: error age: 18 content: 123 name: maki
示例2:条件判断结果为True,丢弃日志。
原始日志
k1: v1 k2: v2 k3: k1加工规则
e_drop(e_search("k1==v1"))加工结果
因为k1==v1条件为True,因此丢弃该日志。
示例3:条件判断结果为False,保留日志。
原始日志
k1: v1 k2: v2 k3: k1加工规则
e_drop(e_search("not k1==v1"))加工结果
k1: v1 k2: v2 k3: k1
示例4:不设置判断条件时,使用默认值True,丢弃日志。
原始日志
k1: v1 k2: v2 k3: k1加工规则
e_drop()加工结果
丢弃日志。
更多参考
支持和其他函数组合使用。相关示例,请参见复制和分发数据。
e_keep
根据条件判断是否保留日志。
函数格式
e_keep(condition=True)支持固定标识KEEP,等价于e_keep()。
参数说明
参数名称
参数类型
是否必填
说明
condition
Bool
否
默认为True,一般传递一个条件判断函数的结果。
返回结果
满足条件则返回原日志,不满足时丢弃日志。
函数示例
示例1:当
__programe__字段的值是access的时候保留日志,否则丢弃日志。原始日志
__programe__: access age: 18 content: 123 name: maki __programe__: error age: 18 content: 123 name: maki加工规则
e_keep(e_search("__programe__==access")) #等价于 e_if(e_search("not __programe__==access"), DROP) #等价于 e_if_else(e_search("__programe__==access"), KEEP, DROP)加工结果
保留__programe__字段值为access的日志。
__programe__: access age: 18 content: 123 name: maki
示例2:条件判断结果为True,保留日志。
原始日志
k1: v1 k2: v2 k3: k1加工规则
e_keep(e_search("k1==v1"))加工结果
k1: v1 k2: v2 k3: k1
示例3:条件判断结果为False,丢弃日志。
原始日志
k1: v1 k2: v2 k3: k1加工规则
e_keep(e_search("not k1==v1"))加工结果
丢弃日志。
示例4:判断条件为False。
原始日志
k1: v1 k2: v2 k3: k1加工规则
e_keep(False)加工结果
丢弃日志。
更多参考
支持和其他函数组合使用。相关示例,请参见复杂JSON数据加工。
e_split
基于日志字段的值分裂出多条日志,并且支持通过JMES提取字段后再进行分裂。
函数格式
e_split(字段名, sep=',', quote='"', lstrip=True, jmes=None, output=None)分裂规则:
如果配置了jmes参数,则将日志字段的值转化为JSON列表,并使用JMES提取值作为下一步的值。如果没有配置jmes参数,则将字段的值直接作为下一步的值。
如果上一步的值是一个列表或JSON列表格式的字符串,则按照此列表分裂并结束处理。否则使用sep、quote或lstrip将上一步的值进行CSV解析,根据解析后的多个值进行分裂并结束处理。
参数说明
参数名称
参数类型
是否必填
说明
字段名
String
是
需要分裂的字段名。特殊字段名的设置请参见事件类型。
sep
String
否
用于分隔多个值的分隔符。
quote
String
否
用于引用多个值的配对类字符的引用符。
lstrip
String
否
是否将值左边的空格去掉,默认为True。
jmes
String
否
将字段值转化为JSON对象,并使用JMES提取特定值,再进行分裂操作。
output
String
否
设置一个新的字段名,默认覆盖旧字段名。
返回结果
返回日志列表,列表中字段的值都是源列表中的值。
函数示例
原始日志
__topic__: age: 18 content: 123 name: maki __topic__: age: 18 content: 123 name: maki加工规则
e_set("__topic__", "V_SENT,V_RECV,A_SENT,A_RECV") e_split("__topic__")加工结果
__topic__: A_SENT age: 18 content: 123 name: maki __topic__: V_RECV age: 18 content: 123 name: maki ...
更多参考
支持和其他函数组合使用。相关示例,请参见复杂JSON数据加工。
e_outputLogStoreut
输出日志到指定的Logstore中,并可配置输出时的topic、source、tag等信息。
函数格式
e_output(name=None, project=None, logstore=None, topic=None, source=None, tags=None, hash_key_field=None, hash_key=None) e_coutput(name=None, project=None, logstore=None, topic=None, source=None, tags=None, hash_key_field=None, hash_key=None)预览时不会输出日志到目标LogStore中,而是输出到internal-etl-log LogStore中。 internal-etl-log LogStore是您首次执行数据加工预览时,系统在当前Project下自动创建的专属LogStore,不支持修改配置及写入其他数据,不收取任何费用。
参数说明
说明如果您在e_output函数、e_coutput函数中配置了name、project、logstore参数,在后续创建数据加工任务面板中又配置了目标Project、目标库,则以e_output函数、e_coutput函数配置为准。具体说明如下所示:
如果您在e_output函数、e_coutput函数中只配置name参数,则加工结果分发存储到目标名称对应的目标LogStore中。
如果您在e_output函数中只配置project、logstore参数,则加工结果分发存储到您在e_output函数中配置的目标LogStore中。
如果您采用的是密钥授权方式,则加工过程中使用的AccessKey信息为当前登录账号的AccessKey信息。
如果您在e_output函数中同时配置name、project、logstore参数,则加工结果分发存储到您在e_output函数中配置的目标LogStore中。
如果您采用的是密钥授权方式,则加工过程中使用的AccessKey信息为目标名称中配置的AccessKey信息。
参数名称
参数类型
是否必填
说明
name
String
否
存储目标的目标名称,默认为None。
project
String
否
输出日志到已存在的Project。
logstore
String
否
输出日志到已存在的LogStore。
topic
String
否
为日志设置新的日志主题。
source
String
否
为日志设置新的日志来源信息。
tags
Dict
否
为日志设置新的标签,以字典格式传入。
说明关键字不需要加
__tag__:前缀。hash_key_field
String
否
指定日志的一个字段名。加工任务基于该字段Hash值,将日志输出到存储目标的特定Shard。
说明如果日志中不存在指定字段,则自动切换到负载均衡模式,将日志随机写入存储目标的某个Shard上。
hash_key
String
否
指定一个Hash值。加工任务将日志固定输出到存储目标的特定Shard。
说明hash_key_field参数优先级高于该参数,即加工语法中已经配置hash_key_field参数时,该参数不起作用。
设置默认存储目标
您在使用e_output函数、e_coutput函数时,需要在创建数据加工任务面板中配置一个默认存储目标,日志服务默认以标号1中配置的存储目标为默认存储目标。例如:下图中,符合e_output函数加工规则的数据分别投递到target_01、target_02、target_03下的目标LogStore中,其他在加工过程中没有被丢弃的数据存储到默认存储目标(target_00)下的目标LogStore中。
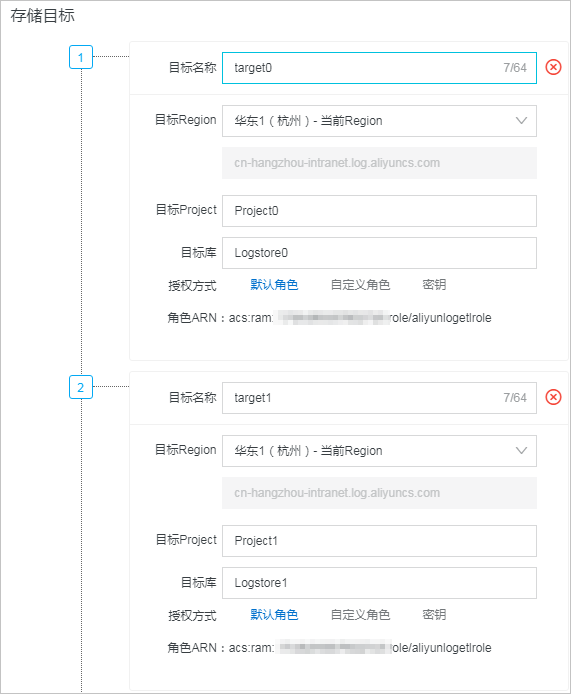
高级参数配置
使用e_output函数、e_coutputLogStore的目标Project、LogStore不存在,您可以在创建数据加工任务面板中,将高级参数配置中的key设置为config.sls_output.failure_strategy,value设置为{"drop_when_not_exists":"true"} 来跳过该日志,被跳过的日志会被丢弃,并且上报为warning级别的日志。如果不设置高级参数配置,数据加工任务将一直等待目标Project、Logstore被创建后再执行加工任务。
警告您在使用高级参数配置解决目标Project、LogStore不存在问题时,会丢弃日志,请谨慎使用。

加工结果
e_output:输出日志到指定的LogStore中,且对应的日志不再执行后面的加工规则。
e_coutput:输出日志到指定的LogStore中,且对应的日志继续执行后面的加工规则。
函数示例
示例1:将k2满足正则表达式,输出到target2中,并topic设置为topic1。
原始日志
__topic__: k1: v1 k2: v2 x1: v3 x5: v4加工规则
此处
e_drop()函数的作用是把e_if()函数过滤掉的数据做删除处理。如果不添加该函数,则被过滤的数据被投递到默认的存储目标中。e_if(e_match("k2", r"\w+"), e_output(name="target2", source="source1", topic="topic1")) e_drop()加工结果
__topic__: topic1 k1: v1 k2: v2 x1: v3 x5: v4
示例2:基于日志中db_version字段的值计算Hash,并根据此Hash值将日志固定输出到存储目标的特定Shard上。
原始日志
__topic__: db_name: db-01 db_version:5.6 __topic__: db_name: db-02 db_version:5.7加工规则
e_output(name="target1", hash_key_field="db_version")加工结果
# 假设存储目标target1一共有2个Shard。 # Shard 0的范围[00000000000000000000000000000000,80000000000000000000000000000000)。 # Shard 1的范围[80000000000000000000000000000000,ffffffffffffffffffffffffffffffff)。 # db_version的取值5.6和5.7,对应的Hash值分别为0ebe1a34e990772a2bad83ce076e0766和f1867131d82f2256b4521fe34aec2405。 # Shard 0: __topic__: db_name: db-01 db_version:5.6 # Shard 1: __topic__: db_name: db-02 db_version:5.7
示例3:直接指定Hash值,将日志固定输出到存储目标的特定Shard上。
原始日志
__topic__: db_name: db-01 db_version:5.6 __topic__: db_name: db-02 db_version:5.7加工规则
e_output(name="target1", hash_key="00000000000000000000000000000000")加工结果
# 假设存储目标一共有2个Shard。 # Shard 0的范围[00000000000000000000000000000000,80000000000000000000000000000000)。 # Shard 1的范围[80000000000000000000000000000000,ffffffffffffffffffffffffffffffff)。 # Shard 0: __topic__: db_name: db-01 db_version:5.6 __topic__: db_name: db-02 db_version:5.7 # Shard 1: 无
更多参考
支持和其他函数组合使用。相关示例,请参见将不同LogStore的日志数据汇总到一个LogStore。
e_to_metric
将日志格式转化为时序存储的格式。
函数格式
e_to_metric(names=None, labels=None, time_field='__time__', time_precision='s', ignore_none_names=True, ignore_none_labels=True)参数说明
参数名称
参数类型
是否必填
说明
names
String、StringList、Tuple List
是
时序数据的Metric名称,可以是单个字符串、多个字符串列表或者元组列表,其值为对应日志字段名称。
String:将一个日志字段转换为时序数据的Metric名称。包含一个字符串,例如取值为rt。返回一条包含
__name__:rt的时序数据。StringList:将日志字段转换为时序数据的Metric名称。包含多个字符串,例如取值为["rt", "qps"]。返回两条时序数据,分别包含
__name__:rt和__name__:qps。Tuple List:将多个日志字段转换为时序数据的Metric名称,并重新命名。包含多个元组,例如取值为 [("rt","max_rt"),("qps", "total_qps")] 。元组的第一个元素是原日志字段,第二个为加工后的时序数据Metric名称字段。返回两条时序数据,分别包含
__name__:max_rt和__name__:total_qps。
labels
String、StringList、Tuple List
否
时序数据的labels信息字段,可以是单个字符串、多个字符串列表或者元组列表,其值为对应日志字段名称。
说明如下描述中host和app为日志字段名称,hostvalue和appvalue为日志字段的值。
String:将一个日志字段转换为时序数据的labels信息。包含一个字符串,例如取值为host。返回一条包含
__label__:host#$#hostvalue的时序数据。StringList:将日志字段转换为时序数据的labels信息。包含多个字符串,例如取值为["host", "app"]。返回两条时序数据,分别包含
__label__:host#$#hostvalue和__label__:app#$#appvalue。Tuple List:将多个日志字段转换为时序数据的labels信息,并重新命名。包含多个元组,例如取值[("host","hostname"),("app", "appname")] 。元组的第一个元素是原日志字段,第二个为加工后的时序数据labels信息字段。返回两条时序数据,分别包含
__label__:hostname#$#hostvalue和__label__:appname#$#appvalue。
time_field
String
否
时序数据的时间字段。默认使用日志中
__time__字段作为时序数据的时间字段。time_precision
Int
否
原始日志数据时间字段的时间单位,支持秒、毫秒、微秒、纳秒。默认按照秒存储。例如
time_field="ms"表示原日志数据时间单位为毫秒。ignore_none_names
Boolean
否
日志字段不存在时,是否忽略转换为时序数据。
True(默认值):忽略,即不转换为时序数据。
False:不忽略,不存在时上报错误。
ignore_none_labels
Boolean
否
日志字段不存在时,是否忽略转换为时序数据。
True(默认值):忽略,即不转换为时序数据。
False:不忽略,不存在时上报错误。
返回结果
返回时序数据。
函数示例
示例1:将rt字段所在的日志转换为时序数据格式。
原始日志
__time__: 1614739608 rt: 123加工规则
e_to_metric(names="rt")加工结果
__labels__: __name__:rt __time_nano__:1614739608000000000 __value__:123.0
示例2:将rt字段所在的日志转换为时序数据格式,并将host字段作为新增labels信息字段。
原始日志
__time__: 1614739608 rt: 123 host: myhost加工规则
e_to_metric(names="rt", labels="host")加工结果
__labels__:host#$#myhost __name__:rt __time_nano__:1614739608000000000 __value__:123.0
示例3:将rt和qps字段所在的日志转换为时序数据格式,并将host字段作为新增labels信息字段。
原始日志
__time__: 1614739608 rt: 123 qps: 10 host: myhost加工规则
e_to_metric(names=["rt","qps"], labels="host")加工结果
__labels__:host#$#myhost __name__:rt __time_nano__:1614739608000000000 __value__:123.0 __labels__:host#$#myhost __name__:qps __time_nano__:1614739608000000000 __value__:10.0
示例4:将rt和qps字段所在的日志转换为时序数据格式,替换字段名称为max_rt和total_qps,并将host字段作为新增labels信息字段。
原始日志
__time__: 1614739608 rt: 123 qps: 10 host: myhost加工规则
e_to_metric(names=[("rt","max_rt"),("qps","total_qps")], labels="host")加工结果
__labels__:host#$#myhost __name__:max_rt __time_nano__:1614739608000000000 __value__:123.0 __labels__:host#$#myhost __name__:total_qps __time_nano__:1614739608000000000 __value__:10.0
示例5:将rt和qps字段所在的日志转换为时序数据格式,替换字段名称为max_rt和total_qps,并将host字段重命名为hostname后作为新增labels信息字段。
原始日志
__time__: 1614739608 rt: 123 qps: 10 host: myhost加工规则
e_to_metric(names=[("rt","max_rt"),("qps","total_qps")], labels=[("host","hostname")])加工结果
__labels__:hostname#$#myhost __name__:max_rt __time_nano__:1614739608000000000 __value__:123.0 __labels__:hostname#$#myhost __name__:total_qps __time_nano__:1614739608000000000 __value__:10.0
示例6:将remote_user1和request_length字段所在的日志转换为时序数据格式,替换字段名称为remote_user2和request_length1,并将status1字段作为新增labels信息字段。
原始日志
__time__:1652943594 remote_user:89 request_length:4264 request_method:GET status:200加工规则
# remote_user1和status1不存在,忽略,即不做转换。 e_to_metric( names=[("remote_user1", "remote_user2"), ("request_length", "request_length1")], labels="status1", ignore_none_names=True, ignore_none_labels=True, )加工结果
__labels__: __name__:request_length1 __time_nano__:1652943594000000000 __value__:4264.0
示例7:将remote_user字段所在的日志转换为时序数据格式,将status字段作为新增labels信息字段,并指定原始日志数据时间单位为毫秒。
原始日志
__time__:1652943594 remote_user:89 request_length:4264 request_method:GET status:200加工规则
e_to_metric( names="remote_user", labels="status", time_precision="ms", ignore_none_names=True, ignore_none_labels=True, )加工结果
__labels__:status#$#200 __name__:remote_user __time_nano__:1652943594000000 __value__:89.0
示例8:将remote_user字段所在的日志转换为时序数据格式,将status字段作为新增labels信息字段,将time字段作为时序数据的时间字段,并指定原始日志数据时间单位为纳秒。
原始日志
time:1652943594 remote_user:89 request_length:4264 request_method:GET status:200加工规则
e_to_metric( names="remote_user", labels="status", time_field="time", time_precision="ns", ignore_none_names=True, ignore_none_labels=True, )加工结果
__labels__:status#$#200 __name__:remote_user __time_nano__:1652943594 __value__:89.0
更多参考
支持和其他函数组合使用。相关示例,请参见将LogStore中的日志字段转换MetricStore中的度量指标。