日志服务提供可托管、可扩展、高可用的数据加工(新版)服务。数据加工(新版)服务可应用于数据规整与信息提取、数据清洗与过滤、数据分发至多目标LogStore等数据处理场景。
加工原理
日志服务提供的数据加工(新版)功能,通过托管实时数据消费的任务,结合日志服务SPL规则消费功能,实现对日志数据的实时加工处理。关于SPL规则细节请参考SPL语法,对应SPL的实时消费应用场景,SPL规则消费请参考普通消费概述。
数据加工功能基于日志服务实时消费接口,不依赖源LogStore的索引配置。
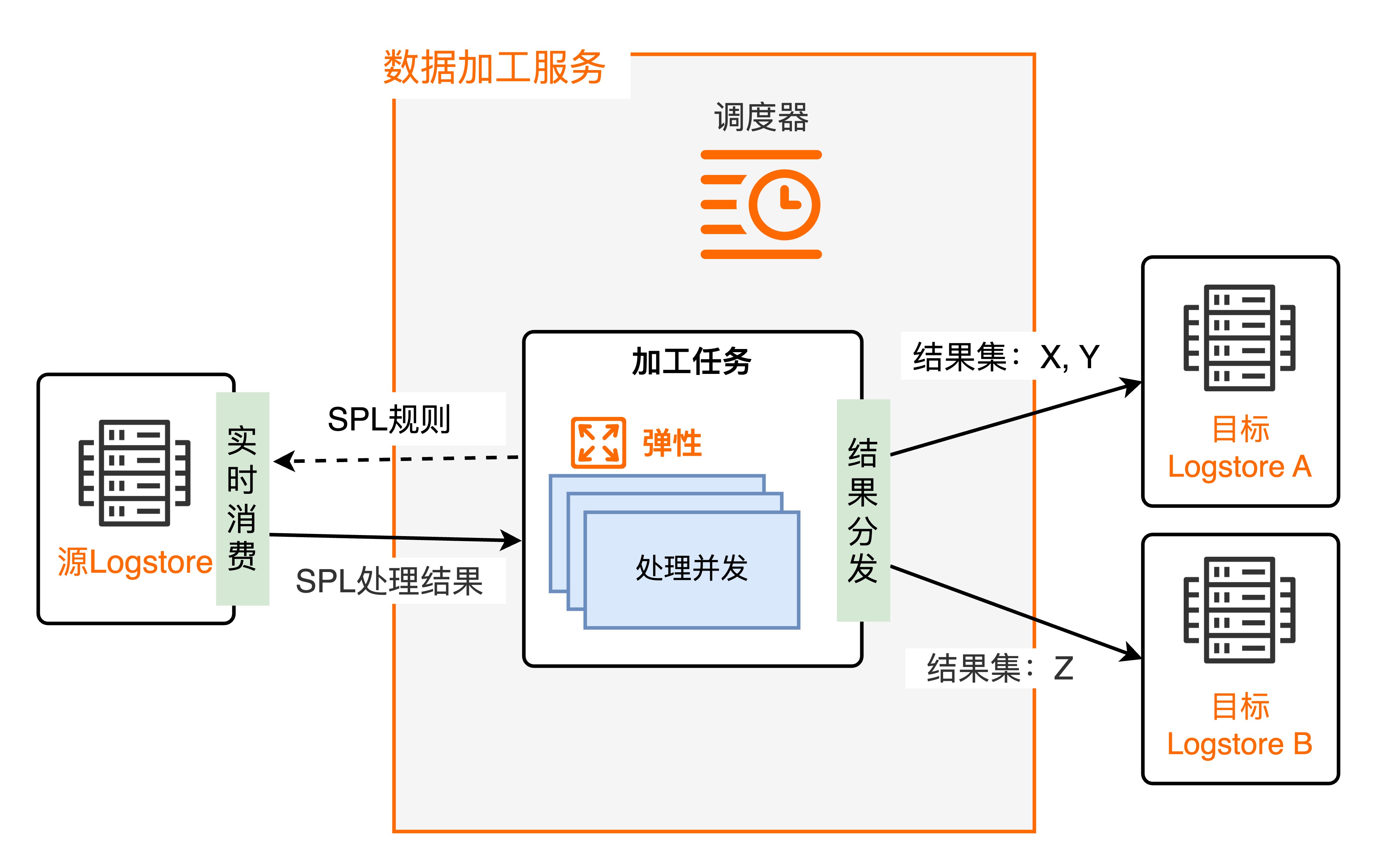
调度机制
对每一个加工任务,加工服务的调度器会启动一个或多个运行实例,并发执行数据处理,每个运行实例扮演一个消费者角色消费1个或者多个源LogStore的Shard。调度器根据运行实例资源消耗以及处理进度决定运行实例数目,实现弹性并发。单个任务的并发上限为源LogStore的Shard数量。
运行实例
根据任务的SPL规则和目标LogStore等配置信息,从数据加工服务分配的Shard中,使用SPL规则消费源日志数据,将基于SPL规则处理后的结果分发写入对应的目标LogStore。在运行实例运行过程中,自动保存Shard的消费点位,确保任务停止重启时,从断点处继续消费。
任务停止与恢复
自动停止条件:若配置了终点时间,任务在处理完该时间前的日志后自动停止;未配置时任务持续运行,详情请参考ETL。
断点续传:任务意外停止后重启时,默认从上次保存的Shard消费点位继续处理,确保数据一致性。
查看任务运行状态
日志服务支持对当前数据加工任务监控,详情请参见观测与监控数据加工(新版)任务。
适用场景
数据加工功能用于数据的规整、流转、脱敏和过滤等处理场景,具体说明如下。
数据规整与信息提取:针对混乱格式的日志进行字段提取、格式转换,获取结构化数据以支持下游的流处理、数据仓库分析。
数据流转与分发:
不同类型的日志统一采集至一个LogStore,根据日志特征将来自不同服务模块或者业务组件的日志分发给对应的下游LogStore,以实现数据隔离、分场景计算等需求。
服务在多地域部署,日志按地域采集,将不同地域的日志跨地域(加速)汇集到中心地域,实现全球日志集中化管理需求。
数据清洗与过滤:清理无效的日志条目、或者用不到的日志字段,过滤出关键的信息写入下游LogStore,用于重点分析。
数据脱敏:对数据中包含的密码、手机号、地址等敏感信息进行脱敏。
功能优势
日志服务SPL语法,统一采集、查询、消费处理的语法,无需额外学习成本。
数据加工(新版)SPL编写过程支持按行调试和代码提示,接近IDE编码体验。
实时处理、数据秒级可见、计算能力扩展、按量弹性伸缩、高吞吐能力。
面向日志分析场景,提供开箱即用的数据处理指令和SQL函数。
提供实时观测指标和仪表盘,支持基于运行指标做自定义监控。
全托管、免运维,与阿里云大数据产品、开源生态集成。
费用说明
若LogStore的计费模式为按写入数据量计费时,数据加工(新版)服务不产生费用,仅从日志服务公网域名所在接口拉取或者写入数据时,会产生外网读取流量(按照压缩后的数据量计算)。具体内容,可参见按写入数据量计费模式计费项。
若LogStore的计费模式为按使用功能计费时,数据加工(新版)服务会消耗机器与网络资源产生相应费用。更多信息,请参见按使用功能计费模式计费项。