在任务调度过程中,您可以通过两种策略来实现应用级别的限流:开启限流并设置适当的队列大小、配置支持抢占的优先级队列,以确保调度系统的稳定性以及核心任务的及时性。本文将介绍如何有效地管理应用级别的资源和任务优先级调度。
应用场景
在面对突发峰值任务调度的场景下,系统可能面临巨大的压力。例如,当许多天级别的任务被设置在同一时间启动时,若无有效的调控措施,会导致后端业务无法承受这些并发负载,从而引发系统崩溃的风险。为了解决这一问题,引入任务调度中的队列机制,控制整个应用在同一时间内的最大运行任务数。通过逐步分配和调度任务,确保系统资源的合理使用和业务的稳定运行。
配置方式
应用开启限流并设置队列大小
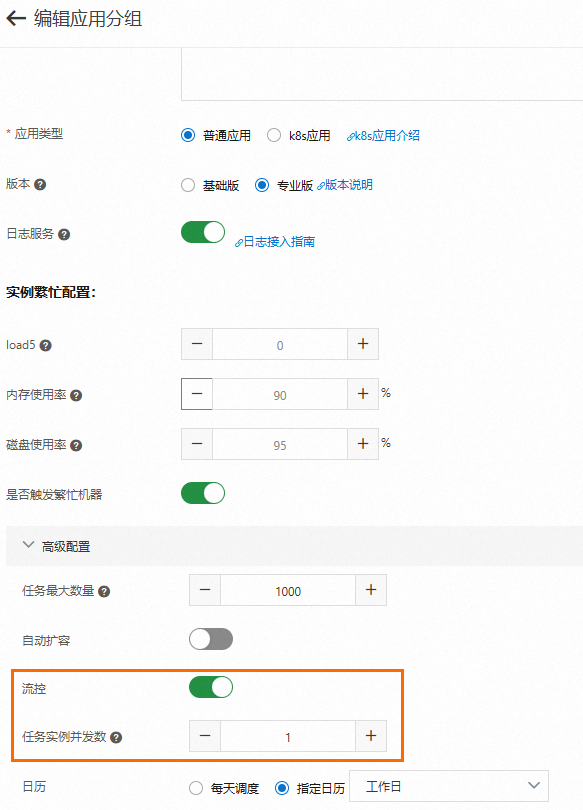
新建和编辑应用分组时,在高级配置中可以打开流控开关(默认关闭)。新建应用分组具体内容,请参见创建应用分组。
开启开关后,可以配置任务实例并发数(即应用级别的任务队列)。该队列表示一个应用最多同时运行的任务实例个数,超过并发数的任务实例不会丢弃,会在队列中等待执行。
在该分组下新建3个任务,分别单击操作列下的运行一次。

在左侧导航栏的执行列表页面中,选择任务实例列表后,可观察到第一个触发的任务hello_jobA在运行中,hello_jobB和hello_jobC在池子中排队等待。
等待hello_jobA运行成功后,hello_jobB会进入执行队列。
配置可抢占的优先级队列
下图是yarn的优先级队列,对不同优先级的任务做资源隔离。

下面将介绍SchedulerX如何通过应用限流与任务优先级结合的方式,实现可抢占的任务优先级队列。
任务支持优先级,同一个应用下,调度时间一样,优先级高的任务会优先调度。
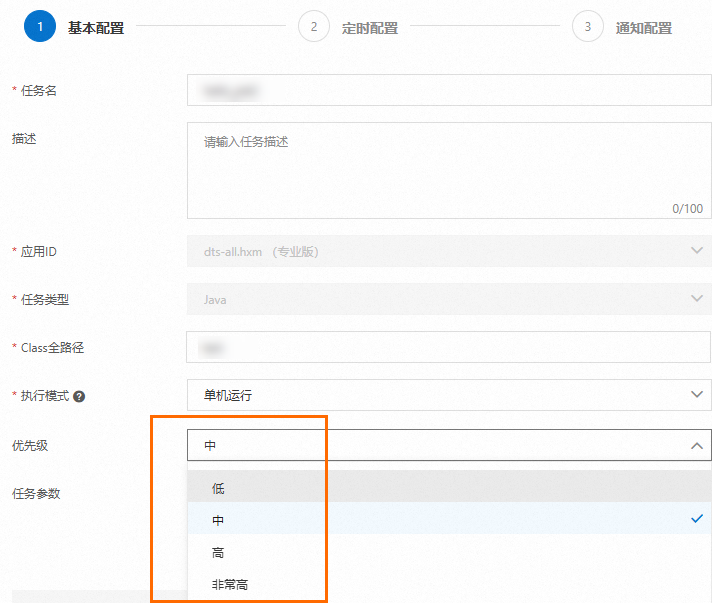
将dts-all.hxm示例应用开启限流,并设置任务实例并发数为1方便观察,新建3个高中低优先级任务。按先后顺序先触发1次中优先级任务,再触发1次低优先级任务,最后触发1次高优先级任务。

在左侧导航栏的执行列表页面中,选择任务实例列表后,可观察到当中优先级任务被触发时,由于队列中为空,暂无其他任务,所以中优先级任务先执行。
在中优先级任务完成后,当队列出现空闲槽位时,高优先级任务将优先于低优先级任务进行抢占式执行。
F&Q
将任务优先级全部设置为非常高,是不是能保证自己的任务比其他用户的任务优先调度?
任务优先级是应用级别的,只会在该应用下生效,不会影响其他应用。
分钟级别的任务,可以用队列限流吗?
该功能适合是有突发峰值的场景,如果每分钟调度量很大,则不适合用该功能,不然会导致队列越堆越多。可以在客户端做业务限流或者扩容客户端来解决。