当云数据库 Tair(兼容 Redis)内存不足时,可能导致Key频繁被逐出、响应时间上升、QPS(每秒访问次数)不稳定等问题,进而影响业务运行。如果发现实例内存占满或收到内存告警,可参考本文判断内存占用是否长期过高、内存占用是否突然上升、是否发生内存倾斜,并通过拆分大Key,设置过期策略,升级规格等方法解决问题。
内存使用率高的现象分类
内存使用率高,通常分为以下三种情况:
内存使用率在较长一段时间内一直处于较高水位。通常,当内存使用率超过95%时需要及时关注。
内存使用率一直较低,但从某个时间点开始突然上升至较高水位,甚至达到100%。
实例整体的内存使用率较低,但某个数据分片节点的内存使用率接近100%。
请根据不同情况,分别采取措施降低内存使用率。
内存使用率长期处于高水位的解决办法
查询现有的Key是否符合业务预期,及时清理无用的Key。
通过缓存分析功能,分析大Key分布和Key的TTL过期策略。具体操作,请参见离线全量Key分析。
分析Key是否有合理的TTL策略。
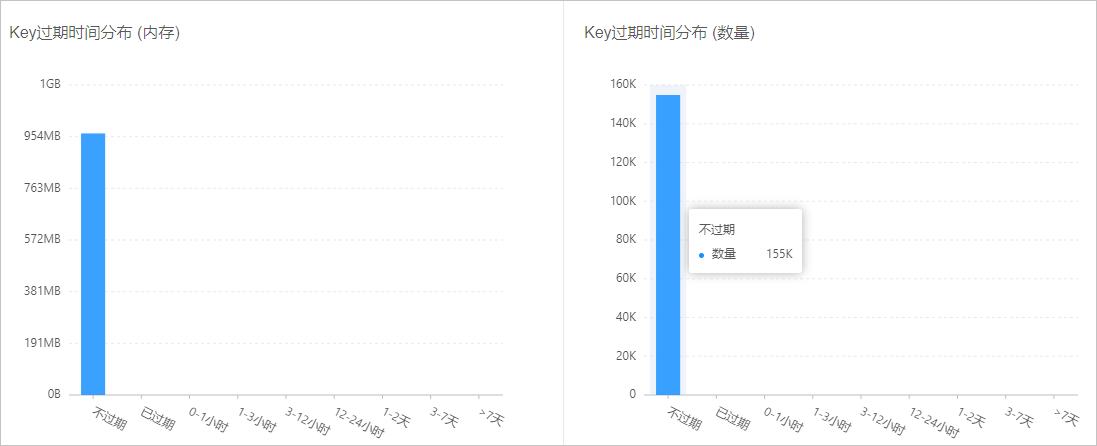
说明以下示例中,所有的Key均未设置过期时间,建议根据业务需求来衡量,并在应用端设置合理的过期时间。
图 4. Key的过期时间分布示例
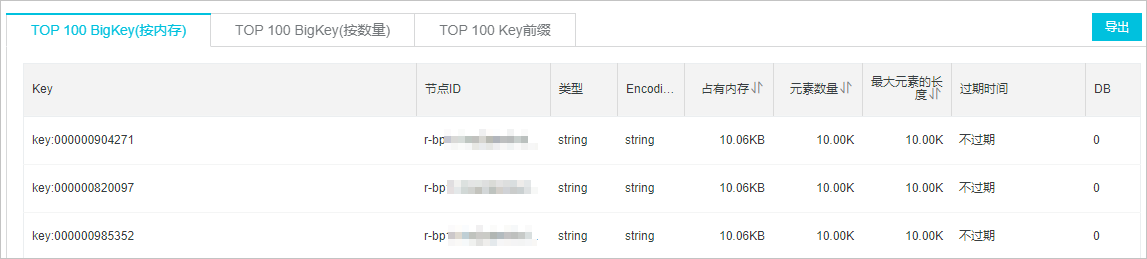
对大Key进行评估,然后在业务侧对大Key进行拆分。
图 5. 大Key分析示例
根据业务需求,设置合理的数据逐出策略(即调整maxmemory-policy参数的值)。具体操作,请参见设置参数。
说明实例默认的数据逐出策略为volatile-lru,更多信息,请参见数据逐出策略介绍。
根据业务需求,设置合理的过期Key主动删除的执行频率(即调整hz参数的值)。具体操作,请参见调整定期任务的执行频率。
说明hz的取值建议在100以内,如果该值过大将对CPU的使用率产生较大影响。您也可以设置为自动调整(要求实例的大版本为兼容Redis 5.0及以上版本),具体操作,请参见自动调整定期任务的执行频率。
经过上述步骤优化后,内存使用率依旧较高,可评估升级至更大内存的规格,以承载更多数据并改善性能。具体操作,请参见变更实例配置。
说明在正式升级实例的规格前,您可以先购买一个按量付费的实例,测试要升级到的目标规格是否能够满足业务的负载需求,测试完成后可将其释放。关于如何释放实例,请参见释放按量付费实例。
内存使用率突然上升的解决办法
问题原因
内存使用率突然升高的主要原因如下:
短时间内大量写入新数据。
短时间内大量创建新连接。
突发访问产生大量流量超过网络带宽,导致输入缓冲区和输出缓冲区积压。
客户端处理速度跟不上实例的处理速度,导致输出缓冲区积压。
解决方案
请依次排查内存使用率突然升高的原因,并参考对应的解决方案解决问题。
排查是否写入大量新数据
排查方法:
查看性能监控的入流量与写QPS。如果入流量与写QPS的趋势与内存使用率的趋势一致,说明大量的数据写入导致内存使用率突然升高。
解决方案:
通过设置Key的过期时间自动清理不再需要的Key,或手动删除不再需要的Key。
升级实例规格,通过增加内存容量缓解内存使用率升高的问题。详情请参见变更实例配置。
如果您的实例为标准版,扩容内存规格后仍无法解决内存使用率高的问题,可以考虑升级为集群版,将数据分布到多个数据分片节点上,减轻单个数据分片节点的内存压力。详情请参见变更实例配置。
排查是否创建大量新连接
排查方法:
查看性能监控的连接数。如果连接数突然增长,且与内存使用率的趋势一致,说明大量新建连接导致内存使用率突然升高。
解决方案:
排查是否存在连接泄漏。
设置连接超时时间,自动关闭空闲连接。详情请参见设置客户端连接的空闲时间。
排查是否突发流量导致输入和输出缓冲区积压
排查方法:
查看性能监控的出入口流量使用率是否达到100%。
执行
MEMORY STATS命令,查看clients.normal占用的内存是否过多。说明clients.normal反映了所有普通客户端连接的输入和输出缓冲区所占用的内存总量。
解决方案:
排查是否因客户端性能问题导致输出缓冲区积压
排查方法:
在实例中,执行MEMORY DOCTOR命令,查看big_client_buf的值。当big_client_buf=1时,代表至少有一个客户端的输出缓冲区占用内存较大。
解决方案:
执行CLIENT LIST命令,查看哪个客户端的输出缓冲区内存占用量(omem)较大。排查该客户端应用是否存在性能问题。
数据分片节点内存使用率高的解决方法
现象
如果实例为集群架构,您可能从以下一种或几种现象发现数据分片节点的内存使用率高:
收到了云监控的内存使用率告警。告警信息中显示某个数据节点的内存使用率高,超过了阈值。
实例诊断报告显示内存使用率发生倾斜。
在性能监控页面查看实例的内存使用率和数据节点的内存使用率,发现实例的内存使用率不高,但某个数据分片节点的内存使用率较高。
问题原因
如果实例的内存使用率不高,但某个数据分片节点的内存使用率较高,说明发生了内存倾斜。
解决方案
检查是否存在大Key,并拆分大Key
查找大Key
通过离线全量Key分析找出大Key。
更多找出大Key的方法,请参见大Key和热Key。
拆分大Key
例如将含有数万成员的一个HASH Key拆分为多个HASH Key,并确保每个Key的成员数量在合理范围。在集群架构实例中,拆分大Key能对数据分片间的内存平衡起到显著作用。
检查是否使用了Hash Tag
如果使用了Hash Tag,请根据业务实际情况,评估将一个Hash Tag拆分为多个Hash Tag,使数据更加均匀地分布在不同的数据分片节点上。
扩容实例规格
扩容实例规格,可以增加实例每个分片的内存,是改善内存倾斜的临时解决方案,具体操作请参见变更实例配置。
变配时实例会进行数据倾斜预检查,若您选择的实例规格无法解决内存倾斜问题,实例会进行拦截与报错,请您调大实例规格后重试。
在成功升级实例规格后,会改善内存倾斜问题,但可能也引起带宽倾斜或CPU倾斜。
附录1:Redis内存占用介绍
Redis的内存占用主要由以下三部分组成:
内存占用 | 说明 |
链路内存(动态) | 主要包括Input Buff、Output Buff、JIT Overhead、Fake Lua Link、Lua执行缓存等,例如可执行INFO命令,通过返回结果的Clients中查看客户端缓存信息。 说明 Input buff与Output buff与每个客户端的连接有关,通常较小。当执行客户端Range类操作或大Key收发较慢时,Input buff与Output buff占用的内存会增大,从而影响数据区,甚至会造成内存溢出OOM(Out Of Memory)。 |
数据内存 | 用户数据区,即实际存储的Value信息,通常作为重点分析的对象。 |
管理内存(静态) | 启动时较小且相对恒定,该区域由管理数据的Hash内存开销、Repl-buff与aof-buff的内存开销(约32 MB~64 MB)等构成。 说明 当Key数量特别多时(例如几亿个),会占用较大的内存。 |
大部分OOM场景是由于动态内存管理失效引起,例如限流时请求堆积导致动态内存快速上升、过于复杂或不合理的Lua脚本也可能导致OOM。Tair(企业版)增强了对动态内存的控制,推荐选用。
附录2:查看内存占用情况的其他方法
使用MEMORY STATS命令查看内存占用情况
使用MEMORY DOCTOR命令查看内存诊断建议
在Redis中,执行MEMORY DOCTOR命令获取内存诊断建议。
图 3. 诊断结果示例
MEMORY DOCTOR会从以下维度为Redis实例的提供内存诊断建议,您可以根据诊断建议制定相应的优化策略:
int empty = 0; /* Instance is empty or almost empty. */
int big_peak = 0; /* Memory peak is much larger than used mem. */
int high_frag = 0; /* High fragmentation. */
int high_alloc_frag = 0;/* High allocator fragmentation. */
int high_proc_rss = 0; /* High process rss overhead. */
int high_alloc_rss = 0; /* High rss overhead. */
int big_slave_buf = 0; /* Slave buffers are too big. */
int big_client_buf = 0; /* Client buffers are too big. */
int many_scripts = 0; /* Script cache has too many scripts. */