在数据库维护或故障处理时查看性能指标是必不可少的步骤。RDS MySQL的标准监控提供了丰富的性能监控指标和强大的诊断能力,能够及时发现异常并提供治理方案。
功能简介
RDS MySQL升级了标准监控,融合了性能趋势,提供了更丰富的功能。
自定义视图:标准监控提供更加丰富的性能监控指标,支持自定义视图,自主选择指标进行监控。
说明监控指标对应的性能参数请参见性能参数表。
常见问题的诊断视图:提供了内存OOM诊断、只读实例延迟诊断、空间满问题诊断、CPU抖动诊断和大事务识别诊断等视图,您可以选择对应的诊断视图,快速定位问题。
自动诊断:标准监控能及时发现数据库实例的事件,进行自动诊断,输出根因分析和建议。
手动诊断:支持自主选择时段进行手动诊断。
查看标准监控
访问RDS实例列表,在上方选择地域,然后单击目标实例ID。
在左侧导航栏单击监控与报警。
在标准监控页面,选择标准视图或自定义视图。
标准视图
在标准视图页签,选择查询时间,查看选定时间范围内的性能事件和性能指标。
说明在选择时间范围时,开始时间与结束时间之间的间隔不得超过7天,最多可查看30天内的数据。
查看性能事件
在事件统计区域,查看选定时间范围内各类事件的统计信息。单击查看详情,可以跳转到查看性能事件页面,查看实例异常事件和优化事件的详细信息,包括计划执行、正在执行和已执行完成的事件。
查看性能指标
查看监控指标
在默认的经典视图中,您可以查看选定时间段的监控指标。
单击更多指标,选择需要查看性能趋势的指标。
单击每个监控项后的
 查看各个监控项包含的指标。
查看各个监控项包含的指标。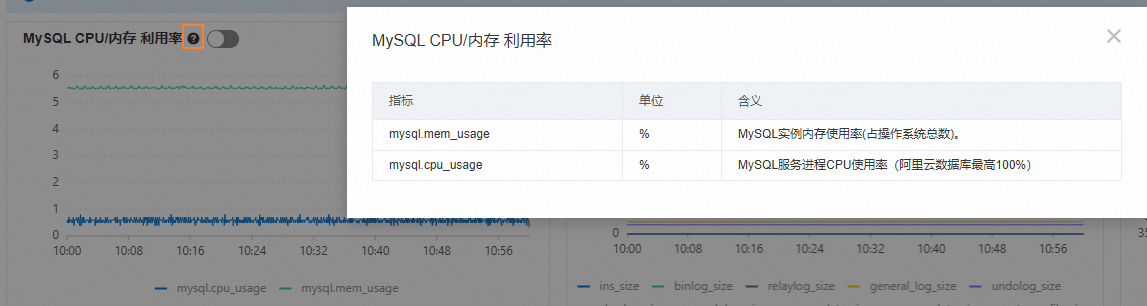
单击某个监控指标趋势图中的详情,放大并修改时间查看趋势。
单击添加趋势对比,查看不同时间段内相同指标的性能趋势对比。

查看事件分析
在默认经典视图中,选择需要展示的事件级别,系统会在MySQL CPU/内存利用率和会话连接的趋势图中展示这些事件。
单击趋势图中的事件,在事件详情中查看诊断结果。
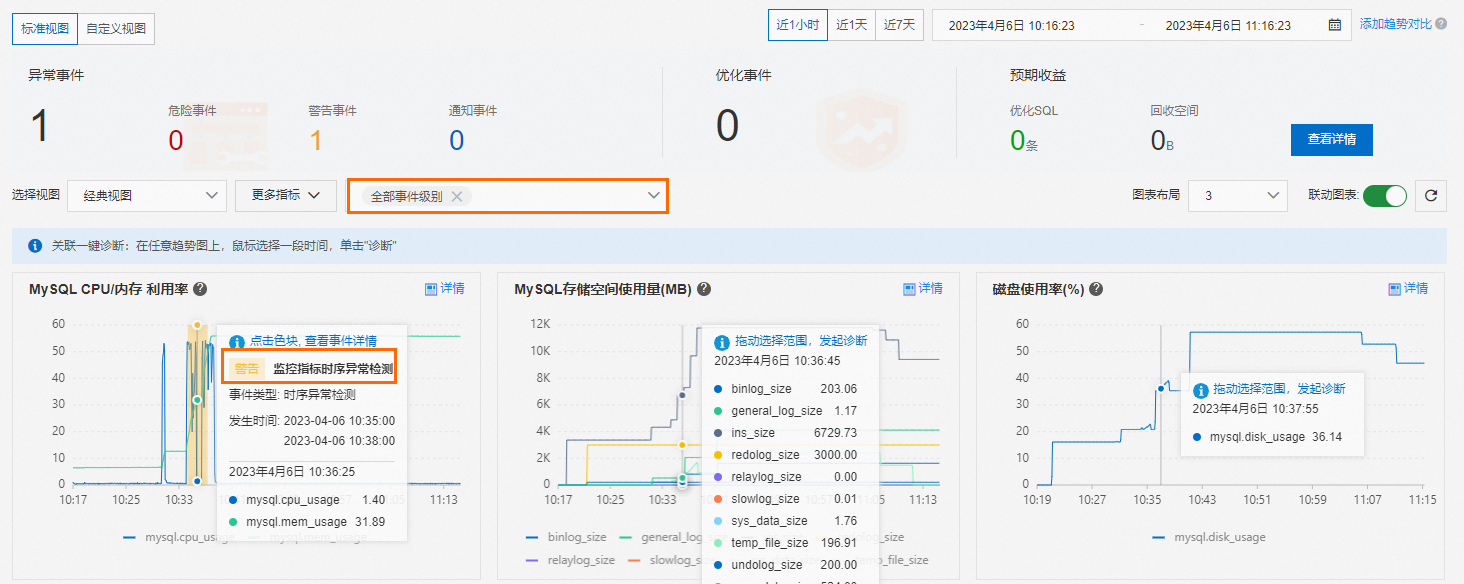
诊断分析指标
在任意指标趋势图中,使用鼠标拖拽的方式选定一段时间,可以对选择时段进行诊断。
查看常见问题诊断视图
您可以通过这些视图快速定位问题原因,当前提供的诊断视图包括:内存OOM诊断、只读实例延迟诊断、空间满问题诊断、CPU抖动诊断和大事务识别诊断。详情请参见诊断视图使用指南。
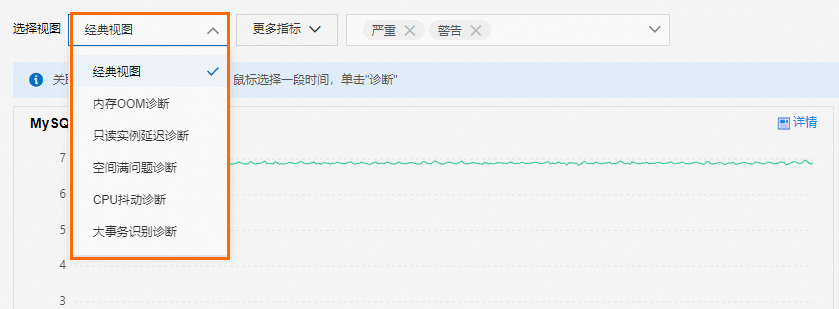
自定义视图
在自定义视图页签,单击新增监控大盘,通过自定义监控大盘,查看需要进行监控的指标趋势。监控指标对应的性能参数请参见性能参数表。
单击添加节点和指标监控,为监控大盘选择需要监控的节点和指标。
您可以选择不同的指标展示方式,合并展示和分开展示。
合并展示:多个指标在同一个趋势图表展示。
分开展示:单独展示每个指标的趋势图。
通过图表布局,设置每行显示监控指标趋势图的数量。
单击某个监控指标趋势图中的详情,放大并修改时间查看趋势。
单击标准监控页面右上角的返回旧版按钮,可以返回旧版监控。
诊断视图使用指南
内存OOM诊断
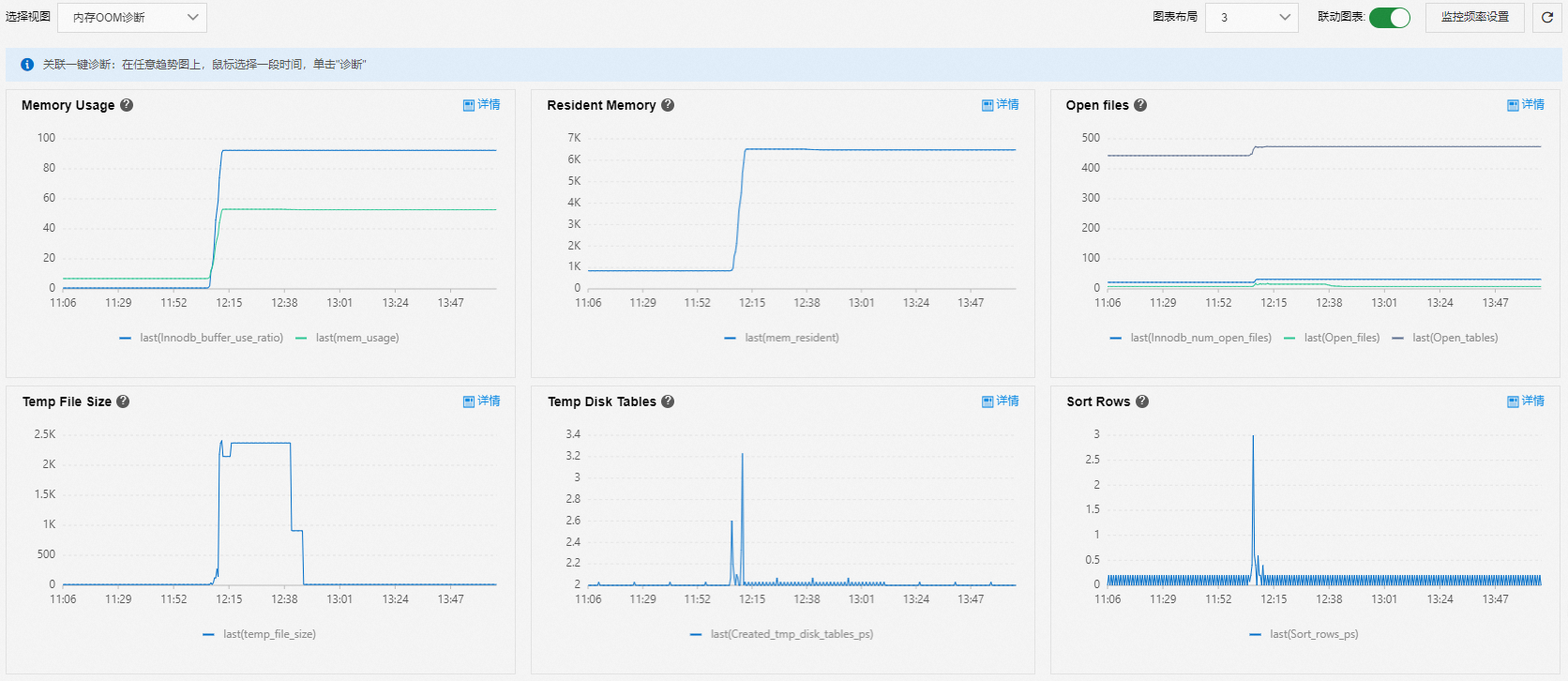
使用内存OOM诊断视图分析内存OOM(Out of Memory)问题。
Memory Usage:
InnoDB Buffer Pool使用率不变,内存使用率长时间(例如超过7天)缓慢持续上涨时,可能是内存泄漏导致。
内存突然上涨,InnoDB Buffer Pool使用率不变时,可能是突增业务导致。
内存和InnoDB Buffer Pool同步增长时,InnoDB Buffer Pool被逐步填充,属于正常情况。
Resident Memory:查看内存大小。
Open files、Temp File Size、Temp Disk Tables和Sort Rows:查看消耗内存的常见指标。
内存增长与业务指标相关,内存突增的SQL通常因OOM无法追溯,因此建议:
检查业务日志,判断内存突增的原因。
升级内存规格,并且开启SQL洞察和审计,在内存突增时查看SQL的执行时间来判断内存突增的原因。
只读实例延迟诊断
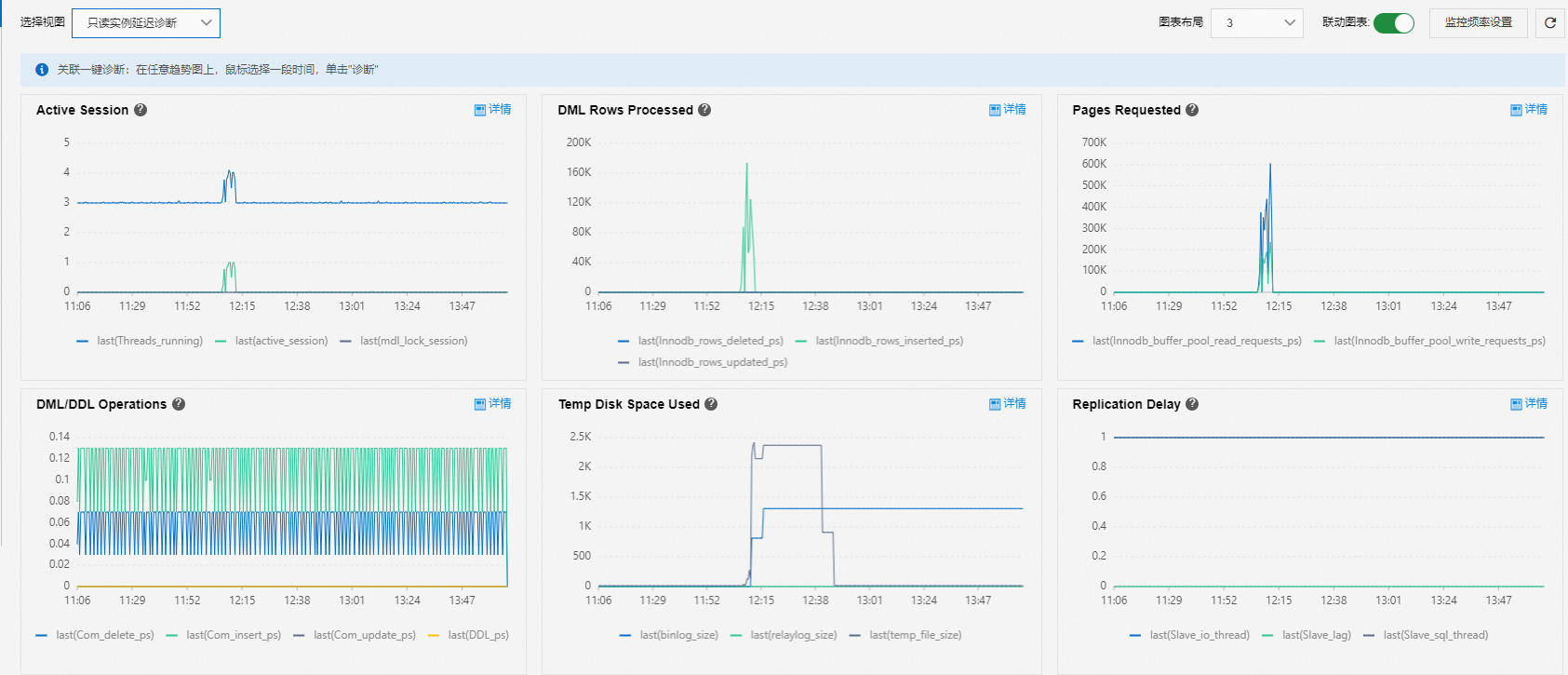
使用只读实例延迟诊断视图分析只读实例延迟问题。
Active Session:查看是否有MDL锁阻塞的情况。
通常大量数据的查询会让DDL无法获取MDL锁,此时DDL会阻塞其他会话,导致连接数堆积。
DML Rows Processed、Pages Requested、DML/DDL Operations和Temp Disk Space Used:查看常见的业务指标。
Replication Delay:查看延迟指标。
空间满问题诊断
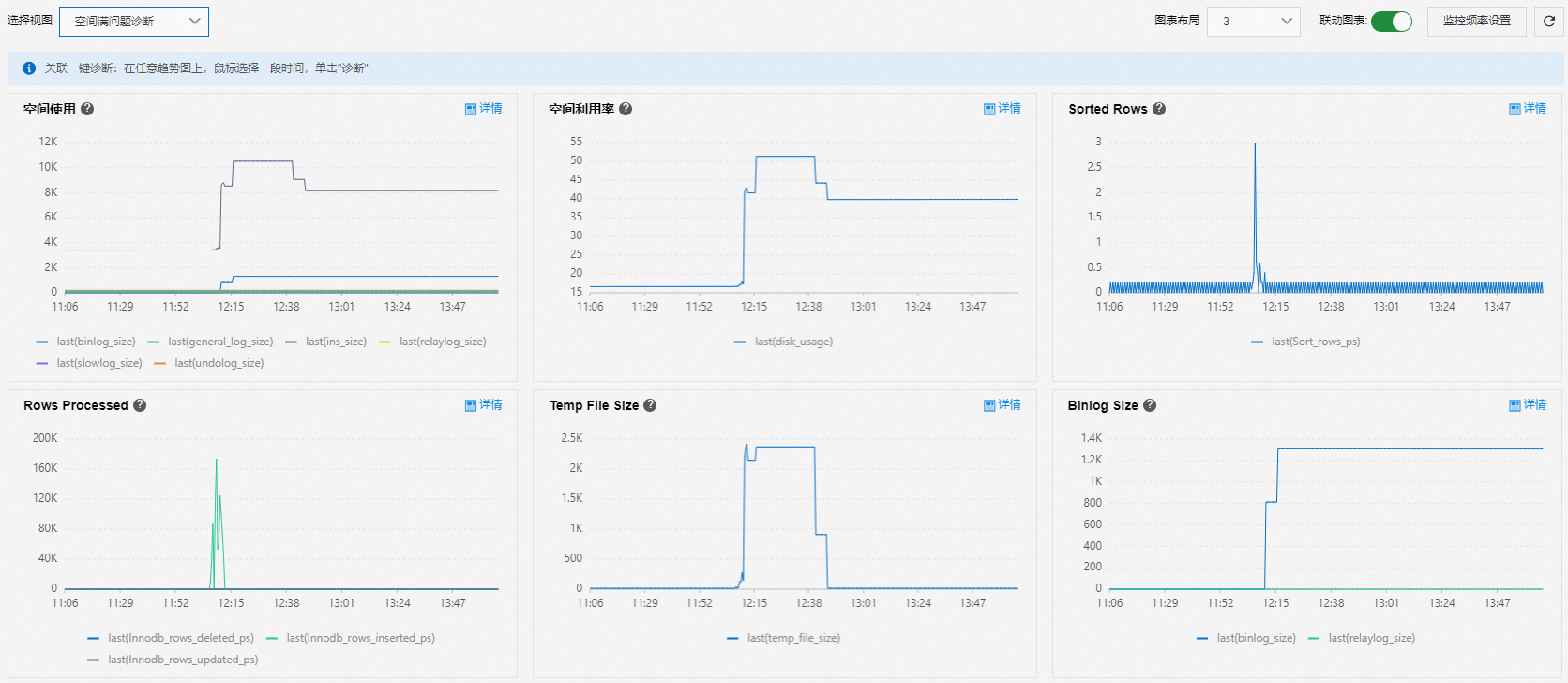
使用空间满问题诊断视图分析空间占满问题。
查看实例占用存储空间的文件类型和变化趋势,常见占用存储的指标如下:
数据文件(user_data_size):可以通过空间分析查看各数据库、表的空间占用情况,根据实际情况扩容或者删除不需要的数据。请参见数据文件导致实例空间满的解决办法处理数据文件。
临时文件(temp_file_size):MySQL实例可能会由于查询语句的排序、分组、关联表产生的临时表文件,或者大事务提交前产生的binlog cache文件占用空间。请参见临时文件导致实例空间满的解决办法处理临时文件。
Binlog日志(binlog_size):MySQL实例可能会由于大事务快速生成Binlog文件占用空间。请参见MySQL Binlog文件导致实例空间满的解决办法处理Binlog日志。
说明如果业务侧订阅了数据库的Binlog,也可能导致Binlog未及时清理而占用空间。
Undo日志(undo_log_size):一般情况下,长时间执行的查询导致Undo日志无法被清理。请检查是否有长时间执行且未结束的查询语句。
说明MySQL 5.6及以前的版本,Undo日志没有独立的表空间。
慢日志(slowlog_size):慢日志占用空间过高时,建议在业务低峰期使用
truncate命令进行清理。说明MySQL 5.7的20210630版本和MySQL 8.0的20210930版本开始支持
truncate命令。常规日志(general_log_size):实例的错误日志、Performance Agent日志、recover日志大小之和 。这部分日志总量一般都会在1 GB以内,基本保持稳定,如果大小明显超过这个范围,请提交工单联系产品解决。该指标是MySQL内核定时输出的内核指标数据,并非是MySQL的general_log的日志大小。
CPU抖动诊断
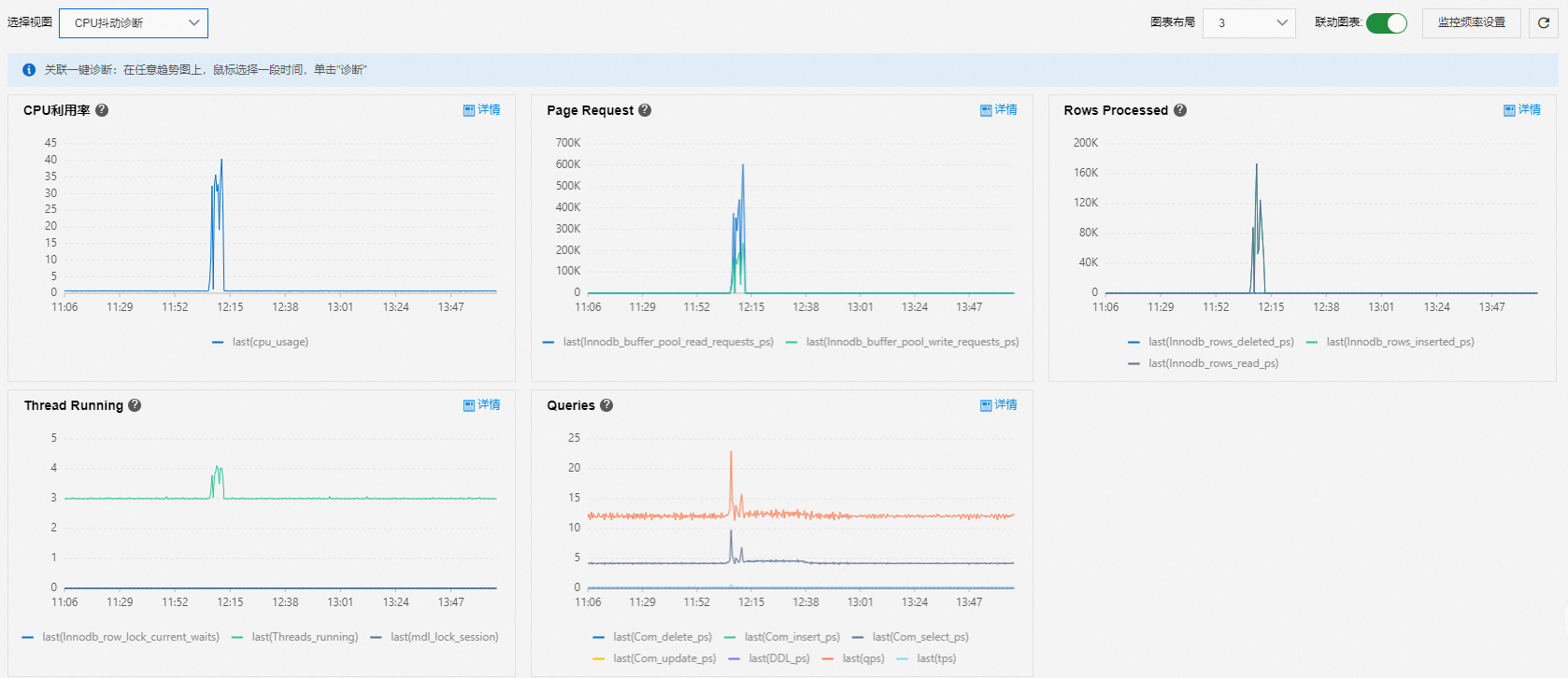
使用CPU抖动诊断视图分析CPU抖动问题,相关指标有:
业务指标:
Page Request:通常情况下,Buffer Pool请求数的趋势和CPU使用率同频波动。
Rows Processed:查看CPU使用率和系统处理行数的关系,判断CPU使用率变化时是否存在突增的行数。
Queries:查看CPU使用率变化时,主要执行的SQL语句类型。
连接数:
Thread Running:高并发会导致CPU使用率变高;MDL堆积或者行锁会导致连接数堆积,进而影响CPU使用率。
CPU抖动的常见原因:
业务指标(Page Request/Rows Processed)发生变化,导致CPU使用率同步变化,此时可以选中CPU使用率变化的时间段,执行诊断获取详细的根因分析结果。
活跃连接数增加引起CPU消耗,此时请从业务侧进行排查。
大事务识别诊断
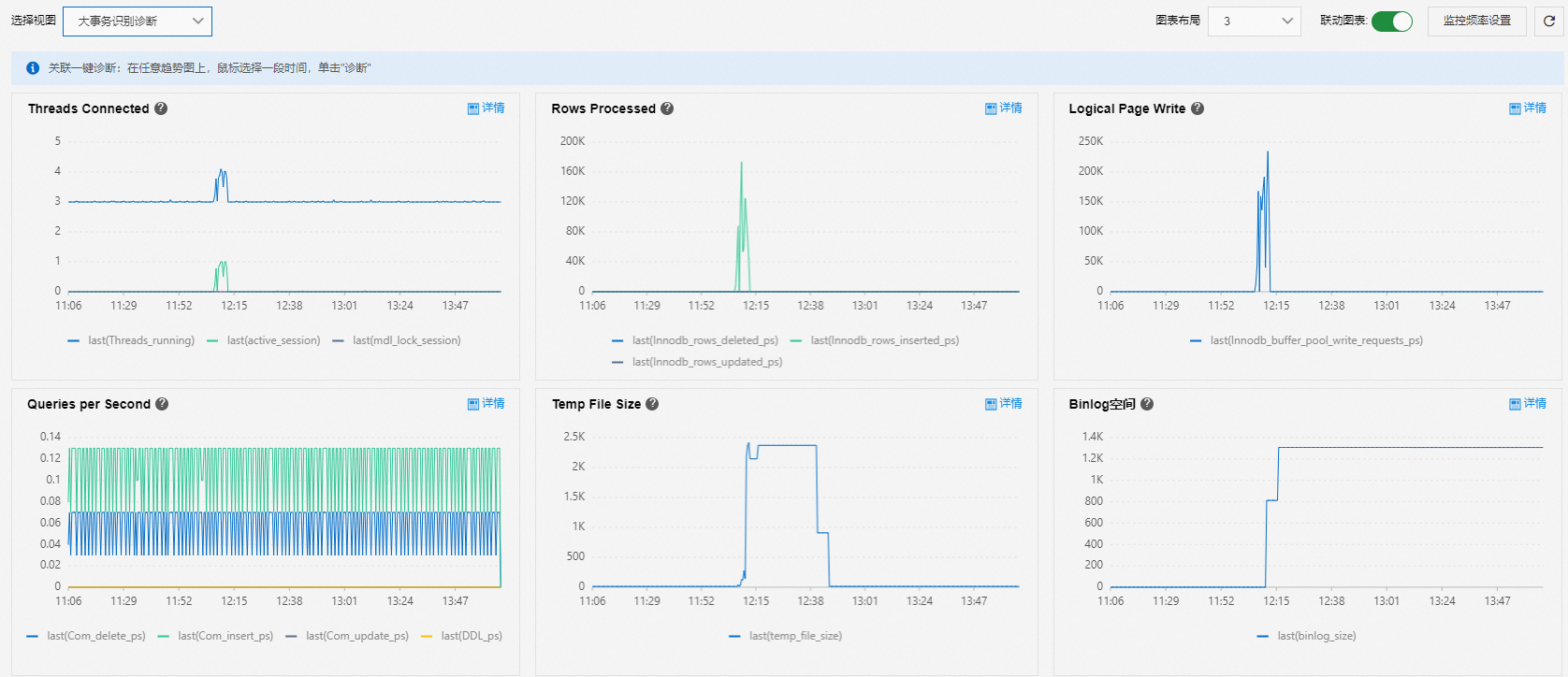
使用大事务识别诊断视图分析大事务问题。
Threads Connected、Temp File Size和Binlog空间:查看判断是否为大事务的三个核心指标。当出现如下情况时,可判断为数据库存在大事务:
活跃会话堆积。
临时空间先增加然后减少。
临时空间减少后Binlog空间同步增加。
Rows Processed、Logical Page Write和Queries per Second:判断大事务是什么类型。
例如查询很少,但删除的行数很多时,表明存在删除数据的大事务。
大事务会引起Binlog写入阻塞:
当实例有大事务时,临时表空间(binlog cache)先逐步增加,然后保持平稳。
当临时表空间平稳时,Binlog空间增加;由于Binlog写入是全局串行,其他事务会被阻塞,导致连接数开始堆积。
当实例为高可用系列时,主实例和备实例的HA组件探测语句也被阻塞,实例会直接发生主备切换。
建议您将大事务拆分为小事务分别执行。例如在delete语句中增加where条件子句,限制每次删除的数据量,将一次删除操作拆分为多次数据量较小的删除操作进行。
相关文档
相关API
API | 描述 |
查询RDS实例性能数据 |
附录:旧版监控
旧版监控指标概述
查看旧版监控
访问RDS实例列表,在上方选择地域,然后单击目标实例ID。
在左侧导航栏单击监控与报警。
选择标准监控页签,单击返回旧版。

在旧版监控页面选择资源监控、引擎监控或部署监控,并选择查询时间(如果是集群系列实例,还可以选择实例或节点ID),即可查看相应的监控数据。仅支持查询过去30天内的监控数据。