本文介绍了分区表扫描算子的使用限制、使用说明以及性能对比等内容。
适用范围
支持的PolarDB PostgreSQL版的版本如下:PostgreSQL 14,内核小版本需为2.0.14.9.15.0及以上。
背景信息
对数据库的分区表进行扫描时,优化器会对每个子分区生成最优的执行计划,然后通过Append算子将子分区的执行计划串联起来,作为分区表扫描的最优执行计划。如果子分区的数量不多,上述过程将会快速完成。然而,PolarDB PostgreSQL版对分区表的分区数量没有限制,当子分区数量过多时,优化器所使用的时间和SQL执行过程中所使用的内存使用将会急剧增大,与扫描相同大小的普通表相比差距尤为明显。
为了解决该问题,PolarDB PostgreSQL版提供了分区表扫描算子(PartitionedTableScan,简称PTS)。与Append算子相比,PTS能够明显减少优化器生成执行计划的时间,且在SQL执行过程中使用更少的内存,能够有效避免OOM。
使用限制
PTS当前仅支持
SELECT,暂不支持DML语句。PTS不支持智能分区连接(Partition Wise Join),如果您打开了
enable_partitionwise_join,将不会生成带有PTS算子的执行计划。
参数说明
参数名称 | 说明 |
polar_num_parts_for_pts | 用于控制开启PTS算子的条件。默认值为64,取值如下:
|
使用说明
通过参数开启PTS算子
SET polar_num_parts_for_pts TO 64;使用HINT
使用HINT语法PTScan(tablealias),示例如下:
EXPLAIN (COSTS OFF, ANALYZE) /*+ PTScan(part_range) */ SELECT * FROM part_range;
QUERY PLAN
--------------------------------------------------------------------------------
PartitionedTableScan on part_range (actual time=86.404..86.405 rows=0 loops=1)
Scan 1000 Partitions: part_range_p0, part_range_p1, part_range_p2,...
-> Seq Scan on part_range
Planning Time: 36.613 ms
Execution Time: 89.246 ms
(5 rows)并行查询
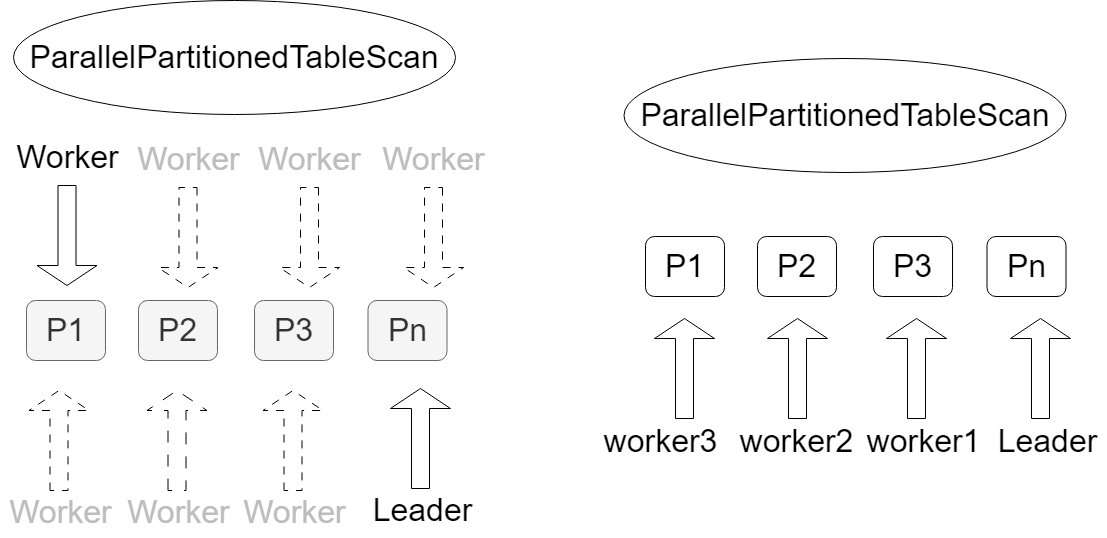
PTS算子支持并行查询,并行的方式包括分区间并行和混合并行两种,均已默认开启,无需调整。
分区间并行:每个工作进程查询一个分区。
混合并行:分区间和分区内都可以并行执行。
示例
创建两张分区表,并分别创建1000个子分区。
CREATE TABLE part_range (a INT, b VARCHAR, c NUMERIC, d INT8) PARTITION BY RANGE (a); SELECT 'CREATE TABLE part_range_p' || i || ' PARTITION OF part_range FOR VALUES FROM (' || 10 * i || ') TO (' || 10 * (i + 1) || ');' FROM generate_series(0,999) i;\gexec CREATE TABLE part_range2 (a INT, b VARCHAR, c NUMERIC, d INT8) PARTITION BY RANGE (a); SELECT 'CREATE TABLE part_range2_p' || i || ' PARTITION OF part_range2 FOR VALUES FROM (' || 10 * i || ') TO (' || 10 * (i + 1) || ');' FROM generate_series(0,999) i;\gexec对分区表进行全表扫描的执行计划如下。
SET polar_num_parts_for_pts TO 0; EXPLAIN (COSTS OFF, ANALYZE) SELECT * FROM part_range; QUERY PLAN --------------------------------------------------------------------------------------------- Append (actual time=8.376..8.751 rows=0 loops=1) -> Seq Scan on part_range_p0 part_range_1 (actual time=0.035..0.036 rows=0 loops=1) -> Seq Scan on part_range_p1 part_range_2 (actual time=0.009..0.009 rows=0 loops=1) -> Seq Scan on part_range_p2 part_range_3 (actual time=0.010..0.011 rows=0 loops=1) ... ... ... -> Seq Scan on part_range_p997 part_range_998 (actual time=0.009..0.009 rows=0 loops=1) -> Seq Scan on part_range_p998 part_range_999 (actual time=0.010..0.010 rows=0 loops=1) -> Seq Scan on part_range_p999 part_range_1000 (actual time=0.009..0.009 rows=0 loops=1) Planning Time: 785.169 ms Execution Time: 163.534 ms (1003 rows)将两张分区表进行连接查询时,执行计划的生成时间长和SQL执行过程中内存使用多的问题将会更加明显。
=> SET polar_num_parts_for_pts TO 0; => EXPLAIN (COSTS OFF, ANALYZE) SELECT COUNT(*) FROM part_range a JOIN part_range2 b ON a.a = b.a WHERE b.c = '0001'; QUERY PLAN ---------------------------------------------------------------------------------------------------------------------------- Finalize Aggregate (actual time=3191.718..3212.437 rows=1 loops=1) -> Gather (actual time=2735.417..3212.288 rows=3 loops=1) Workers Planned: 2 Workers Launched: 2 -> Partial Aggregate (actual time=2667.247..2667.789 rows=1 loops=3) -> Parallel Hash Join (actual time=1.957..2.497 rows=0 loops=3) Hash Cond: (a.a = b.a) -> Parallel Append (never executed) -> Parallel Seq Scan on part_range_p0 a_1 (never executed) -> Parallel Seq Scan on part_range_p1 a_2 (never executed) -> Parallel Seq Scan on part_range_p2 a_3 (never executed) ... ... ... -> Parallel Seq Scan on part_range_p997 a_998 (never executed) -> Parallel Seq Scan on part_range_p998 a_999 (never executed) -> Parallel Seq Scan on part_range_p999 a_1000 (never executed) -> Parallel Hash (actual time=0.337..0.643 rows=0 loops=3) Buckets: 4096 Batches: 1 Memory Usage: 0kB -> Parallel Append (actual time=0.935..1.379 rows=0 loops=1) -> Parallel Seq Scan on part_range2_p0 b_1 (actual time=0.001..0.001 rows=0 loops=1) Filter: (c = '1'::numeric) -> Parallel Seq Scan on part_range2_p1 b_2 (actual time=0.001..0.001 rows=0 loops=1) Filter: (c = '1'::numeric) -> Parallel Seq Scan on part_range2_p2 b_3 (actual time=0.001..0.001 rows=0 loops=1) Filter: (c = '1'::numeric) ... ... ... -> Parallel Seq Scan on part_range2_p997 b_998 (actual time=0.001..0.001 rows=0 loops=1) Filter: (c = '1'::numeric) -> Parallel Seq Scan on part_range2_p998 b_999 (actual time=0.000..0.001 rows=0 loops=1) Filter: (c = '1'::numeric) -> Parallel Seq Scan on part_range2_p999 b_1000 (actual time=0.002..0.002 rows=0 loops=1) Filter: (c = '1'::numeric) Planning Time: 1900.615 ms Execution Time: 3694.320 ms (3013 rows)从上述示例可以看出,分区表的全表查询由于缺少分区键作为过滤条件,无法将查询集中在部分分区,相比于普通表是没有任何优势的。分区表比普通表更加低效。分区表的最佳实践是尽可能使查询发生分区裁剪,使查询可以集中在少部分分区上。但是对于一些OLAP场景,不得不对分区表进行全表扫描。此时,使用PTS算子比Append算子更加高效。
SET polar_num_parts_for_pts TO 10; EXPLAIN (COSTS OFF, ANALYZE) SELECT * FROM part_range; QUERY PLAN -------------------------------------------------------------------------------- PartitionedTableScan on part_range (actual time=86.404..86.405 rows=0 loops=1) Scan 1000 Partitions: part_range_p0, part_range_p1, part_range_p2,... -> Seq Scan on part_range Planning Time: 36.613 ms Execution Time: 89.246 ms (5 rows)SET polar_num_parts_for_pts TO 10; EXPLAIN (COSTS OFF, ANALYZE) SELECT COUNT(*) FROM part_range a JOIN part_range2 b ON a.a = b.a WHERE b.c = '0001'; QUERY PLAN ---------------------------------------------------------------------------------------------------- Aggregate (actual time=61.384..61.388 rows=1 loops=1) -> Merge Join (actual time=61.378..61.381 rows=0 loops=1) Merge Cond: (a.a = b.a) -> Sort (actual time=61.377..61.378 rows=0 loops=1) Sort Key: a.a Sort Method: quicksort Memory: 25kB -> PartitionedTableScan on part_range a (actual time=61.342..61.343 rows=0 loops=1) Scan 1000 Partitions: part_range_p0, part_range_p1, part_range_p2, ... -> Seq Scan on part_range a -> Sort (never executed) Sort Key: b.a -> PartitionedTableScan on part_range2 b (never executed) -> Seq Scan on part_range2 b Filter: (c = '1'::numeric) Planning Time: 96.675 ms Execution Time: 64.913 ms (16 rows)结果显示,使用PTS算子后,执行计划的生成时间得到了明显的缩短。
性能对比
非标准性能数据,仅在测试环境中,根据控制变量原则,在环境配置一致的情况下,对比Append算子和PTS算子的性能差异。
单条SQL的执行计划生成时间
分区数量 | Append | PTS |
16 | 0.266 ms | 0.067 ms |
32 | 1.820 ms | 0.258 ms |
64 | 3.654 ms | 0.402 ms |
128 | 7.010 ms | 0.664 ms |
256 | 14.095 ms | 1.247 ms |
512 | 27.697 ms | 2.328 ms |
1024 | 73.176 ms | 4.165 ms |
单条SQL的内存使用量
分区数量 | Append | PTS |
16 | 1170 KB | 1044 KB |
32 | 1240 KB | 1044 KB |
64 | 2120 KB | 1624 KB |
128 | 2244 KB | 1524 KB |
256 | 2888 KB | 2072 KB |
512 | 4720 KB | 3012 KB |
1024 | 8236 KB | 5280 KB |
PGBench QPS
分区数量 | Append | PTS |
16 | 25318 | 93950 |
32 | 10906 | 61879 |
64 | 5281 | 30839 |
128 | 2195 | 16684 |
256 | 920 | 8372 |
512 | 92 | 3708 |
1024 | 21 | 1190 |