PolarDB PostgreSQL版(兼容Oracle)支持使用跨机并行查询功能进行分析型查询,实现一定的HTAP能力。本文介绍如何使用跨机并行查询,提升分析型查询的性能。
原理介绍
当一条查询请求在查询协调节点上被执行跨机并行查询时,该查询产生的执行计划会被分片路由至各个执行节点,每个执行节点将会执行各自的分片计划,并将分片的查询结果汇总至查询协调节点。可以称查询协调节点为QC(Query Coordinator)节点,称分片计划的执行节点为PX(Parallel Execution)节点。
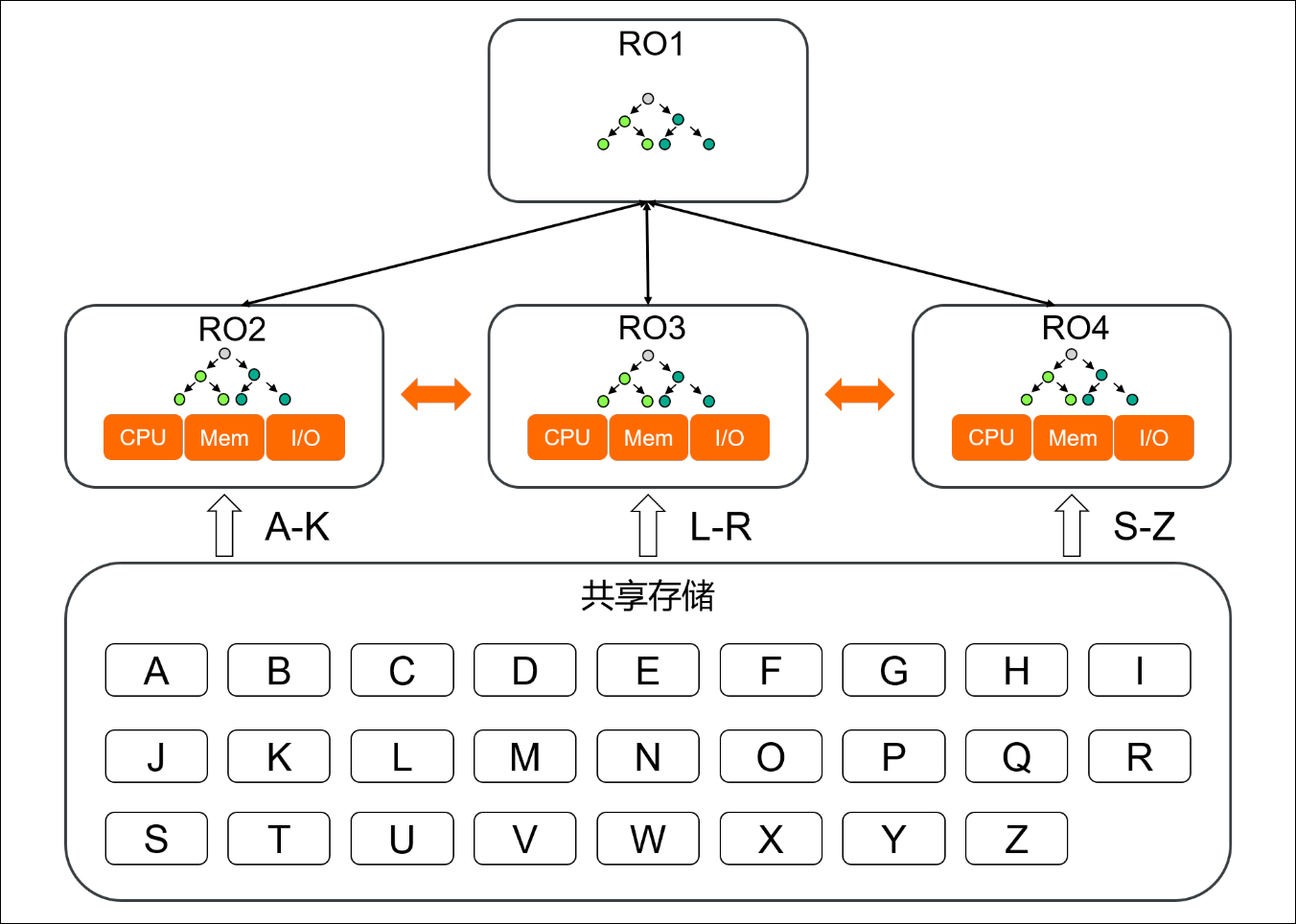
如上图所示,RO1为QC节点,它接收了一条查询输入请求,并将查询计划分片路由至RO2、RO3、RO4三个PX节点。每个PX节点将会针对各自接收到的分片计划,最终从PolarFS共享存储上读取到各自所需的数据块,由执行节点执行完成相应的分片计划,并将执行结果返回为QC节点,QC节点汇总后返回查询结果。
注意事项
由于跨机并行查询功能需使用多个只读节点资源,因此只适用于低频次的分析型查询。
细粒度使用方式
- 系统粒度:通过参数控制所有session所有查询是否开启跨机并行查询。
- 会话粒度:通过alter session或session级别的GUC参数控制当前session是否开启跨机并行查询。
- 查询粒度:通过hint指定具体查询是否开启跨机并行查询。
参数说明
默认情况下,PolarDB PostgreSQL版(兼容Oracle)不开启跨机并行查询功能。若您需要使用此功能,请使用如下参数:
| 参数 | 说明 |
|---|---|
| polar_cluster_map | 用于查询当前PolarDB PostgreSQL版(兼容Oracle)所有只读节点的名称。该参数不可配置。当您新增一个只读节点时,该参数会进行更新。 说明 只有内核小版本(V1.1.20)(发布时间:2022年1月)之前创建的集群才包含该参数。 |
| polar_px_nodes | 指定参与跨机并行查询的只读节点。默认为空,表示所有只读节点都参与。可配置为指定节点参与跨机并行查询,以逗号分隔。例如: |
| polar_px_enable_replay_wait | PolarDB PostgreSQL版(兼容Oracle)的主节点与只读节点存在一定程度的延迟,当主节点执行DDL语句(例如CREATE TABLE),只读节点需要耗时回放该DDL日志后才可见新创建的表。当设置polar_px_enable_replay_wait为on后,跨机并行查询启用强一致性,当前发起的跨机并行查询请求路由到只读节点上执行时,需要只读节点回放到该查询请求前最近的一条日志后,才会执行查询请求。该参数默认为off,即关闭强一致性,在数据库主备日志延迟较高时,不保证只读节点可以读到最近的DDL记录。您可配置 该参数可以指定数据库角色进行开启。 |
| polar_px_max_workers_number | 设置单个节点上的最大跨机并行查询workers进程数,默认为30。该参数限制了单个节点上的最大并发度,节点上所有会话的跨机并行查询workers进程数不能超过该参数大小。 |
| polar_enable_px | 指定是否开启跨机并行查询功能。默认为off,即不开启。 |
| polar_px_dop_per_node | 设置当前会话并行查询的并行度,默认为1,推荐值为当前CPU总核数。若设置该参数为N,则一个会话在每个节点上将会启用N个px workers进程,用于处理当前的跨机并行查询逻辑。 |
| px_workers | 指定跨机并行查询是否对特定表生效。默认不生效。跨机并行查询功能比较消耗计算节点集群资源,因此只有对设置了px_workers的表才使用该功能。例如: |
| synchronous_commit | WAL相关配置参数,指定当数据库提交事务时是否需要等待WAL日志写入硬盘后才向客户端返回成功。取值如下:
说明 PX下参数需要设置为on。 |
示例
本示例以简单的单表查询操作,来描述跨机并行查询的功能是否有效。
示例背景:
执行如下命令,创建test表并插入基础数据。
CREATE TABLE test(id int);
INSERT INTO test SELECT generate_series(1,1000000);
EXPLAIN SELECT * FROM test;默认情况下跨机并行查询功能是不开启的,单表查询执行计划为原生的Seq Scan,结果如下所示。
QUERY PLAN
--------------------------------------------------------
Seq Scan on test (cost=0.00..35.50 rows=2550 width=4)
(1 row)通过以下步骤,开启并使用跨机并行查询功能:
- 对test表启用跨机并行查询功能。
ALTER TABLE test SET (px_workers=1); SET polar_enable_px=on; EXPLAIN SELECT * FROM test;查询结果如下:
QUERY PLAN ------------------------------------------------------------------------------- PX Coordinator 2:1 (slice1; segments: 2) (cost=0.00..431.00 rows=1 width=4) -> Seq Scan on test (scan partial) (cost=0.00..431.00 rows=1 width=4) Optimizer: PolarDB PX Optimizer (3 rows) - 查询当前所有只读节点的名称。
查询命令如下:
SHOW polar_cluster_map;查询结果如下:
polar_cluster_map ------------------- node1,node2,node3 (1 row)可得出当前集群有3个只读节点,名称分别为:node1,node2和node3。
- 指定node1和node2只读节点参与跨机并行查询。
命令如下:
SET polar_px_nodes='node1,node2';查询参与并行查询的节点:
SHOW polar_px_nodes ;查询结果如下:
polar_px_nodes ---------------- node1,node2 (1 row)
性能数据
在5个只读节点的情况下,测试的性能数据如下:
- 在
SELECT COUNT(*)扫表的场景下,跨机并行查询比单机并行查询加速60倍。 - 在TPC-H场景下,跨机并行查询比单机并行查询加速30倍。说明 此处的TPC-H场景是基于TPC-H的基准测试,并不能与已发布的TPC-H基准测试结果相比较,此处提及的测试结果并不符合TPC-H基准测试的所有要求。
细粒度使用跨机并行查询
各个粒度下如何使用跨机并行查询进行分析型查询如下所示:
- 系统粒度控制
系统粒度控制主要通过设置全局guc参数控制开启跨机并行查询,指定并行度。
示例postgres=# alter system set polar_enable_px=1; ALTER SYSTEM postgres=# alter system set polar_px_dop_per_node=1; ALTER SYSTEM postgres=# select pg_reload_conf(); pg_reload_conf ---------------- t (1 row) postgres=# \c postgres You are now connected to database "postgres" as user "postgres". postgres=# drop table if exists t1; DROP TABLE postgres=# select id into t1 from generate_series(1, 1000) as id order by id desc; SELECT 1000 postgres=# alter table t1 set (px_workers=1); ALTER TABLE postgres=# explain (verbose, costs off) select * from t1 where id < 10; QUERY PLAN ------------------------------------------- PX Coordinator 2:1 (slice1; segments: 2) Output: id -> Partial Seq Scan on public.t1 Output: id Filter: (t1.id < 10) Optimizer: PolarDB PX Optimizer (6 rows) - 会话粒度控制会话粒度控制可以通过ALTER SESSION语法,也可以通过session级别的GUC参数控制。
- ALTER SESSION语法
ALTER SESSION ENABLE PARALLEL QUERY ALTER SESSION DISABLE PARALLEL QUERY ALTER SESSION FORCE PARALLEL QUERY [PARALLEL integer]说明ALTER SESSION ENABLE PARALLEL QUERY表示当前session允许通过hint或者并行语法来开启并行查询。ALTER SESSION DISABLE PARALLEL QUERY表示当前session只能串行执行查询,不能并行查询,指定hint或者并行语法也无效。ALTER SESSION FORCE PARALLEL QUERY [PARALLEL integer]表示强制当前session开启并行执行,并行度为PARALLEL integer,如果后者没有指定,则使用数据库默认并行度polar_px_dop_per_node参数值。实际并行度优先级为:hint指定 > FORCE PARALLEL指定 > polar_px_dop_per_node指定。
ALTER SESSION命令会更改跨机并行查询的配置参数,仅影响当前会话,会话重连后会重置,默认值enable。
示例--enable postgres=# set polar_enable_px = false; SET postgres=# set polar_px_enable_hint = true; SET postgres=# alter session enable parallel query; ALTER SESSION postgres=# explain (verbose, costs off) select /*+ PARALLEL(4)*/ * from t1 where id < 10; INFO: [HINTS] PX PARALLEL(4) accepted. QUERY PLAN ------------------------------------------- PX Coordinator 8:1 (slice1; segments: 8) Output: id -> Partial Seq Scan on public.t1 Output: id Filter: (t1.id < 10) Optimizer: PolarDB PX Optimizer (6 rows)--disable postgres=# set polar_enable_px = false; SET postgres=# set polar_px_enable_hint = true; SET postgres=# alter session disable parallel query; ALTER SESSION postgres=# explain (verbose, costs off) select /*+ PARALLEL(4)*/ * from t1 where id < 10; QUERY PLAN ------------------------ Seq Scan on public.t1 Output: id Filter: (t1.id < 10) (3 rows)--force postgres=# set polar_enable_px = false; SET postgres=# set polar_px_enable_hint = false; SET postgres=# alter session force parallel query; ALTER SESSION postgres=# explain (verbose, costs off) select * from t1 where id < 10; QUERY PLAN ------------------------------------------- PX Coordinator 2:1 (slice1; segments: 2) Output: id -> Partial Seq Scan on public.t1 Output: id Filter: (t1.id < 10) Optimizer: PolarDB PX Optimizer (6 rows) postgres=# alter session force parallel query parallel 2; ALTER SESSION postgres=# explain (verbose, costs off) select * from t1 where id < 10; QUERY PLAN ------------------------------------------- PX Coordinator 4:1 (slice1; segments: 4) Output: id -> Partial Seq Scan on public.t1 Output: id Filter: (t1.id < 10) Optimizer: PolarDB PX Optimizer (6 rows) - GUC参数控制
GUC参数本身具有系统粒度属性和会话粒度属性,因此也可以实现会话粒度控制。
示例postgres=# set polar_enable_px = true; SET postgres=# set polar_px_dop_per_node = 1; SET postgres=# explain (verbose, costs off) select * from t1 where id < 10; QUERY PLAN ------------------------------------------- PX Coordinator 2:1 (slice1; segments: 2) Output: id -> Partial Seq Scan on public.t1 Output: id Filter: (t1.id < 10) Optimizer: PolarDB PX Optimizer (6 rows)
- ALTER SESSION语法
- 查询粒度控制查询粒度控制主要是通过sql hint指定当前sql查询是否开启跨机并行,以及并行度设置。具体Hint语法如下所示:
/*+ PARALLEL(DEFAULT) */ /*+ PARALLEL(integer) */ /*+ NO_PARALLEL(tablename) */说明PARALLEL(DEFAULT)表示指定使用跨机并行查询,采用系统默认polar_px_dop_per_node并行度配置。PARALLEL(integer)表示指定使用跨机并行查询,采用指定的integer并行度配置。NO_PARALLEL(tablename)表示指定表不能使用跨机并行查询,整个查询中如果包含这张表,则整个查询也不能使用并行查询。- 与Oracle兼容,当parallel hint混用时,存在以下注意事项:
- 多个hint块时,/*+.A.*/ /*+.B.*/ /*+.C.*/,只有第一个hint块生效。
- 单个hint块中多个parallel hint并用时,/*+ parallel(A) parallel(B)*/,如果AB的dop值不相等,则AB的hint作用冲突,所有parallel hint失效;如果AB值相等,则其中一个生效。
- 单个hint块中parallel/no_parallel hint并用时,/*+ parallel(A) no_parallel(t1)*/,则no_parallel的hint失效。
- 当前并行查询只支持parallel/no_parallel hint,暂不支持其他hint。
- 查询粒度的跨机并行查询是否开启,由GUC参数polar_px_enable_hint控制,默认为false。
示例postgres=# set polar_enable_px = false; SET postgres=# set polar_px_dop_per_node = 1; SET postgres=# set polar_px_enable_hint = true; SET postgres=# explain (verbose, costs off) select * from t1 where id < 10; QUERY PLAN ------------------------ Seq Scan on public.t1 Output: id Filter: (t1.id < 10) (3 rows) postgres=# explain (verbose, costs off) select /*+ PARALLEL(DEFAULT) */ * from t1 where id < 10; QUERY PLAN ------------------------------------------- PX Coordinator 2:1 (slice1; segments: 2) Output: id -> Partial Seq Scan on public.t1 Output: id Filter: (t1.id < 10) Optimizer: PolarDB PX Optimizer (6 rows) postgres=# explain (verbose, costs off) select /*+ PARALLEL(4) */ * from t1 where id < 10; QUERY PLAN ------------------------------------------- PX Coordinator 8:1 (slice1; segments: 8) Output: id -> Partial Seq Scan on public.t1 Output: id Filter: (t1.id < 10) Optimizer: PolarDB PX Optimizer (6 rows) postgres=# explain (verbose, costs off) select /*+ PARALLEL(0) */ * from t1 where id < 10; QUERY PLAN ------------------------ Seq Scan on public.t1 Output: id Filter: (t1.id < 10) (3 rows) postgres=# explain (verbose, costs off) select /*+ NO_PARALLEL(t1) */ * from t1 where id < 10; QUERY PLAN ------------------------ Seq Scan on public.t1 Output: id Filter: (t1.id < 10) (3 rows) - 各粒度组合效果三种粒度相互组合时,实际结果按照以下规则:
系统粒度 会话粒度 查询粒度 实际结果 polar_enable_px=on polar_px_dop_per_node=X enable 不指定hint 并行,并行度X polar_enable_px=on polar_px_dop_per_node=X enable PARALLEL(Y) 并行,并行度Y polar_enable_px=on polar_px_dop_per_node=X enable NO_PARALLEL 不并行 polar_enable_px=on polar_px_dop_per_node=X disable 不指定hint 不并行 polar_enable_px=on polar_px_dop_per_node=X disable PARALLEL(Y) 不并行 polar_enable_px=on polar_px_dop_per_node=X disable NO_PARALLEL 不并行 polar_enable_px=on polar_px_dop_per_node=X FORCE PARALLEL Z 不指定hint 并行,并行度Z polar_enable_px=on polar_px_dop_per_node=X FORCE PARALLEL Z PARALLEL(Y) 并行,并行度Y polar_enable_px=on polar_px_dop_per_node=X FORCE PARALLEL Z NO_PARALLEL 不并行 polar_enable_px=off polar_px_dop_per_node=X enable 不指定hint 不并行 polar_enable_px=off polar_px_dop_per_node=X enable PARALLEL(Y) 并行, 并行度Y polar_enable_px=off polar_px_dop_per_node=X enable NO_PARALLEL 不并行 polar_enable_px=off polar_px_dop_per_node=X disable 不指定hint 不并行 polar_enable_px=off polar_px_dop_per_node=X disable PARALLEL(Y) 不并行 polar_enable_px=off polar_px_dop_per_node=X disable NO_PARALLEL 不并行 polar_enable_px=off polar_px_dop_per_node=X FORCE PARALLEL Z 不指定hint 并行,并行度Z polar_enable_px=off polar_px_dop_per_node=X FORCE PARALLEL Z PARALLEL(Y) 并行,并行度Y polar_enable_px=off polar_px_dop_per_node=X FORCE PARALLEL Z NO_PARALLEL 不并行