兼容PolarDB PostgreSQL版(兼容Oracle)的Flink CDC连接器(简称PolarDBO Flink CDC)可用于依次读取PolarDB PostgreSQL版(兼容Oracle)数据库全量快照数据和变更数据,具体功能及用法请参考社区Postgres CDC。
由于PolarDB PostgreSQL版(兼容Oracle)与社区PoatgreSQL仅在少量数据类型和内置对象处理存在差异,本文为您介绍如何基于社区Postgres CDC,通过少量代码适配打包出支持PolarDB PostgreSQL版(兼容Oracle)的PolarDBO Flink CDC连接器。
PolarDB PostgreSQL版(兼容Oracle)的DATE类型是64位,而社区PostgreSQL的DATE类型为32位。因此,在PolarDBO Flink CDC中会对DATA类型数据的处理进行适配。
打包PolarDBO Flink CDC连接器
PolarDBO Flink CDC连接器基于社区Postgres CDC适配开发,无论是您自行打包,还是使用本文中提供的JAR包,PolarDBO Flink CDC连接器都不提供SLA保障。
操作前提
确定Flink-CDC版本
如果您使用的是阿里云实时计算 Flink 版,需要确认与对应Ververica Runtime(简称VVR)版本兼容的社区Flink-CDC版本,具体可以参考CDC与VVR版本对应关系。
说明Flink-CDC代码仓库请参考Flink-CDC。
确定Debezium版本
在对应版本的Flink-CDC的
pom.xml中通过查找关键字debezium.version确定Debezium版本。说明Debezium代码仓库请参考Debezium。
确定PgJDBC版本
在对应版本的Postgres-CDC的
pom.xml中通过查找关键字org.postgresql确定PgJDBC版本。说明release-3.0以下版本文件路径为:
flink-connector-postgres-cdc/pom.xml。release-3.0及以上版本文件路径为:
flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/pom.xml。PgJDBC代码仓库请参考PgJDBC。
操作步骤
release-3.5打包
社区Flink-CDC release-3.5版本兼容阿里云实时计算 Flink 版的vvr-11.4-jdk11-flink-1.20。
打包对应版本的PolarDBO Flink CDC连接器步骤如下:
克隆对应版本的Flink-CDC、Debezium和PgJDBC的代码文件。
git clone -b release-3.5 --depth=1 https://github.com/apache/flink-cdc.git git clone -b REL42.7.3 --depth=1 https://github.com/pgjdbc/pgjdbc.git git clone -b v1.9.8.Final --depth=1 https://github.com/debezium/debezium.git复制Debezium和PgJDBC部分文件到Flink-CDC中。
mkdir -p flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 mkdir -p flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/jdbc cp pgjdbc/pgjdbc/src/main/java/org/postgresql/core/v3/ConnectionFactoryImpl.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 cp pgjdbc/pgjdbc/src/main/java/org/postgresql/core/v3/QueryExecutorImpl.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 cp pgjdbc/pgjdbc/src/main/java/org/postgresql/jdbc/PgDatabaseMetaData.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/jdbc cp pgjdbc/pgjdbc/src/main/java/org/postgresql/core/Oid.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/core cp debezium/debezium-connector-postgres/src/main/java/io/debezium/connector/postgresql/TypeRegistry.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/io/debezium/connector/postgresql进入Flink-CDC中,应用timestamp转换缺陷修复与隐式行为(SELECT *)缺陷修复,后续会合入社区3.6版本。
cd flink-cdc # 应用timestamp转换的bugfix,后续会合入社区3.6版本 git fetch origin 2f32836a783f80f295c9dce339c11afec2a32dc2 git cherry-pick 2f32836a783f80f295c9dce339c11afec2a32dc2 git fetch origin 0d86de24494a855c2d83f9b1052c2e888e182cb1 git cherry-pick 0d86de24494a855c2d83f9b1052c2e888e182cb1应用适配PolarDB PostgreSQL版(兼容Oracle)的patch文件。
git apply release-3.5_support_polardbo.patch说明以上使用的PolarDBO Flink CDC兼容patch文件:release-3.5_support_polardbo.patch。
使用Maven打包PolarDBO Flink CDC连接器。
mvn clean install -DskipTests -Dcheckstyle.skip=true -Dspotless.check.skip # 打包完成后可以在flink-cdc-connect/flink-cdc-pipeline-connectors/flink-cdc-pipeline-connector-postgres/target 目录中获取到jar包
按照以上流程基于JDK11打包出PolarDBO Flink CDC连接器的JAR包:flink-cdc-pipeline-connector-polardbo-3.5-SNAPSHOT-20260212.jar。
release-3.1打包
社区Flink-CDC release-3.1版本兼容阿里云实时计算 Flink 版的vvr-8.0.x-flink-1.17。
打包对应版本的PolarDBO Flink CDC连接器步骤如下:
克隆对应版本的Flink-CDC、Debezium和PgJDBC的代码文件。
git clone -b release-3.1 --depth=1 https://github.com/apache/flink-cdc.git git clone -b REL42.5.1 --depth=1 https://github.com/pgjdbc/pgjdbc.git git clone -b v1.9.8.Final --depth=1 https://github.com/debezium/debezium.git复制Debezium和PgJDBC部分文件到Flink-CDC中。
mkdir -p flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 mkdir -p flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/jdbc cp pgjdbc/pgjdbc/src/main/java/org/postgresql/core/v3/ConnectionFactoryImpl.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 cp pgjdbc/pgjdbc/src/main/java/org/postgresql/core/v3/QueryExecutorImpl.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 cp pgjdbc/pgjdbc/src/main/java/org/postgresql/jdbc/PgDatabaseMetaData.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/org/postgresql/jdbc cp debezium/debezium-connector-postgres/src/main/java/io/debezium/connector/postgresql/TypeRegistry.java flink-cdc/flink-cdc-connect/flink-cdc-source-connectors/flink-connector-postgres-cdc/src/main/java/io/debezium/connector/postgresql应用适配PolarDB PostgreSQL版(兼容Oracle)的patch文件。
git apply release-3.1_support_polardbo.patch说明以上使用的PolarDBO Flink CDC兼容patch文件:release-3.1_support_polardbo.patch。
使用Maven打包PolarDBO Flink CDC连接器。
mvn clean install -DskipTests -Dcheckstyle.skip=true -Dspotless.check.skip -Drat.skip=true # 打包完成后可以在flink-sql-connector-postgres-cdc的target目录中获取到jar包
按照以上流程基于JDK8打包出PolarDBO Flink CDC连接器的JAR包:flink-sql-connector-postgres-cdc-3.1-SNAPSHOT.jar。
release-2.3打包
社区Flink-CDC release-2.3版本兼容阿里云实时计算 Flink 版的vvr-4.0.15-flink-1.13 ~ vvr-6.0.2-flink-1.15。
打包对应版本的PolarDBO Flink CDC连接器步骤如下:
克隆对应版本的Flink-CDC、Debezium和PgJDBC的代码文件。
git clone -b release-2.3 --depth=1 https://github.com/apache/flink-cdc.git git clone -b REL42.2.26 --depth=1 https://github.com/pgjdbc/pgjdbc.git git clone -b v1.6.4.Final --depth=1 https://github.com/debezium/debezium.git复制Debezium和PgJDBC部分文件到Flink-CDC中。
mkdir -p flink-cdc/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 mkdir -p flink-cdc/flink-connector-postgres-cdc/src/main/java/org/postgresql/jdbc mkdir -p flink-cdc/flink-connector-postgres-cdc/src/main/java/io/debezium/connector/postgresql cp pgjdbc/pgjdbc/src/main/java/org/postgresql/core/v3/ConnectionFactoryImpl.java flink-cdc/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 cp pgjdbc/pgjdbc/src/main/java/org/postgresql/core/v3/QueryExecutorImpl.java flink-cdc/flink-connector-postgres-cdc/src/main/java/org/postgresql/core/v3 cp pgjdbc/pgjdbc/src/main/java/org/postgresql/jdbc/PgDatabaseMetaData.java flink-cdc/flink-connector-postgres-cdc/src/main/java/org/postgresql/jdbc cp debezium/debezium-connector-postgres/src/main/java/io/debezium/connector/postgresql/TypeRegistry.java flink-cdc/flink-connector-postgres-cdc/src/main/java/io/debezium/connector/postgresql应用适配PolarDB PostgreSQL版(兼容Oracle)的patch文件。
git apply release-2.3_support_polardbo.patch说明以上使用的PolarDBO Flink CDC兼容patch文件:release-2.3_support_polardbo.patch。
使用Maven打包PolarDBO Flink CDC连接器。
mvn clean install -DskipTests -Dcheckstyle.skip=true -Dspotless.check.skip -Drat.skip=true # 打包完成后可以在flink-sql-connector-postgres-cdc的target目录中获取到jar包
按照以上流程基于JDK8打包出PolarDBO Flink CDC连接器的JAR包:flink-sql-connector-postgres-cdc-2.3-SNAPSHOT.jar。
使用说明
PolarDBO Flink CDC连接器通过PolarDB PostgreSQL版(兼容Oracle)数据库的逻辑复制读取CDC变更流数据,需要满足以下条件:
wal_level参数的值需设置为logical,即在预写式日志WAL(Write-ahead logging)中增加支持逻辑复制所需的信息。说明您可以通过控制台设置wal_level参数,详细操作请参考设置集群参数。修改该参数后集群将会重启,请在修改参数前做好业务安排,谨慎操作。
执行
ALTER TABLE schema.table REPLICA IDENTITY FULL;命令设置订阅表的REPLICA IDENTITY为FULL(发出的插入和更新操作事件包含表中所有列的旧值),以保障该表数据同步的一致性。说明REPLICA IDENTITY是PostgreSQL特有的表级设置,决定了逻辑解码插件在发生(INSERT)和更新(UPDATE)事件时,是否包含涉及的表列的旧值。REPLICA IDENTITY取值含义详情,请参见REPLICA IDENTITY。
设置订阅表的
REPLICA IDENTITY为FULL时可能需要锁表,可能影响业务,请在修改参数前做好业务安排。您可以通过以下命令查看当前配置是否为FULL:SELECT relreplident = 'f' FROM pg_class WHERE relname = 'tablename';
需要确保max_wal_senders和max_replication_slots的参数值均大于当前数据库复制槽已使用数与Flink作业所需要的slot数量。
确保使用的是高权限账号或者同时拥有LOGIN和REPLICATION权限,并且具有订阅表的SELECT权限用于全量数据查询。
只能连接PolarDB集群的主地址,集群地址不支持逻辑复制。
release-3.5及后续版本支持直接同步分区表的父表,需进行以下配置。具体操作,可参考postgres-cdc社区文档。
将
scan.include-partitioned-tables.enabled配置为true,在数据库中手动创建带有
publish_via_partition_root=true选项的PUBLICATION。同时,通过debezium.publication.name参数指定table-name。table-name仅能指定父表,正则表达式不得匹配子表,否则将导致全量数据的重复。
此外,release-3.5及后续版本支持Pipeline连接器,允许读取快照数据和增量数据,并提供端到端的整库数据同步能力。然而,需注意的是,Pipeline连接器目前不支持同步表结构的变更。具体信息,可参考Postgres CDC Pipeline 连接器社区文档。
PolarDBO Flink CDC连接器与Postgres CDC区别
PolarDBO Flink CDC连接器基于Postgres CDC打包,具体语法和参数可以参考Postgres CDC。但存在以下主要区别:
WITH的connector参数需要设置为固定值:
polardbo-cdc。PolarDBO Flink CDC同时兼容PolarDB PostgreSQL版各版本、PolarDB PostgreSQL版(兼容Oracle) 1.0和PolarDB PostgreSQL版(兼容Oracle) 2.0版本。
说明如果您使用的是PolarDB PostgreSQL版,推荐您直接使用社区Postgres CDC。
PolarDB PostgreSQL版(兼容Oracle) 1.0、PolarDB PostgreSQL版(兼容Oracle) 2.0中的
DATE类型的列,Flink SQL中的source和sink表对应类型必须指定为timestamp。建议将
decoding.plugin.name参数设置为pgoutput,否则非UTF-8编码的数据库可能会发生增量解析乱码,详细介绍请参考社区文档。
类型映射
PolarDB PostgreSQL和Flink字段类型映射,除DATE类型外,其他字段类型和社区PostgreSQL完全相同,具体映射关系如下:
PolarDB PostgreSQL字段类型 | Flink字段类型 |
SMALLINT | SMALLINT |
INT2 | |
SMALLSERIAL | |
SERIAL2 | |
INTEGER | INT |
SERIAL | |
BIGINT | BIGINT |
BIGSERIAL | |
REAL | FLOAT |
FLOAT4 | |
FLOAT8 | DOUBLE |
DOUBLE PRECISION | |
NUMERIC(p, s) | DECIMAL(p, s) |
DECIMAL(p, s) | |
BOOLEAN | BOOLEAN |
DATE |
|
TIME [(p)] [WITHOUT TIMEZONE] | TIME [(p)] [WITHOUT TIMEZONE] |
TIMESTAMP [(p)] [WITHOUT TIMEZONE] | TIMESTAMP [(p)] [WITHOUT TIMEZONE] |
CHAR(n) | STRING |
CHARACTER(n) | |
VARCHAR(n) | |
CHARACTER VARYING(n) | |
TEXT | |
BYTEA | BYTES |
使用示例
Source连接器
以下示例用于说明,如何通过PolarDBO Flink CDC,将PolarDB PostgreSQL版(兼容Oracle) 2.0集群中flink_source库的shipments表,同步到flink_sink库的shipments_sink表中。
以下示例仅用于简单验证打包的PolarDBO Flink CDC能够在PolarDB PostgreSQL版(兼容Oracle)上运行。正式使用时,为满足您的业务需求,请参考社区Postgres CDC配置参数。
前提准备
PolarDB PostgreSQL版(兼容Oracle)准备
在PolarDB集群购买页面,购买PolarDB PostgreSQL版(兼容Oracle) 2.0集群。
查看集群主地址,如果PolarDB集群和实时计算 Flink 版在同一专有网络内,可直接使用私网地址,否则需要申请公网地址。
设置集群白名单:将Flink实例地址添加到PolarDB集群白名单中。
在控制台创建源数据库flink_source和目标数据库flink_sink,详细步骤请参考创建数据库。
执行如下语句,在源数据库flink_source中创建shipments表,并写入数据。
CREATE TABLE public.shipments ( shipment_id INT, order_id INT, origin TEXT, destination TEXT, is_arrived BOOLEAN, order_time DATE, PRIMARY KEY (shipment_id) ); ALTER TABLE public.shipments REPLICA IDENTITY FULL; INSERT INTO public.shipments SELECT 1, 1, 'test1', 'test1', false, now();执行如下语句,在目标数据库flink_sink中创建shipments_sink表。
CREATE TABLE public.shipments_sink ( shipment_id INT, order_id INT, origin TEXT, destination TEXT, is_arrived BOOLEAN, order_time TIMESTAMP, PRIMARY KEY (shipment_id) );
实时计算 Flink 版准备
登录实时计算控制台,购买实时计算 Flink 版实例,详细操作请参考开通实时计算Flink版。
说明建议实时计算 Flink 版的地域和专有网络和PolarDB集群保持一致,连接地址可以直接使用PolarDB集群主地址的私网地址。
创建自定义连接器,上传打包好的PolarDBO Flink CDC,Formats选择debezium-json,详细步骤请参考创建自定义连接器。

创建Flink作业
登录实时计算控制台,新建一个SQL作业草稿,请参考作业开发地图。使用以下Flink SQL语句,修改PolarDB集群主地址,端口,账号和密码。
说明PolarDB PostgreSQL版(兼容Oracle)的DATE类型是64位,而Flink SQL以及大部分数据库的DATE类型为32位。因此,源表中DATE类型的列,在Flink SQL的source和sink表中都必须要指定为TIMESTAMP类型。否则,作业会因为类型不匹配而报错中断,例如:
“java.time.DateTimeException: Invalid value for EpochDay (valid values -365243219162 - 365241780471):1720891573000”。CREATE TEMPORARY TABLE shipments ( shipment_id INT, order_id INT, origin STRING, destination STRING, is_arrived BOOLEAN, order_time TIMESTAMP, PRIMARY KEY (shipment_id) NOT ENFORCED ) WITH ( 'connector' = 'polardbo-cdc', 'hostname' = '<yourHostname>', 'port' = '<yourPort>', 'username' = '<yourUserName>', 'password' = '<yourPassWord>', 'database-name' = 'flink_source', 'schema-name' = 'public', 'table-name' = 'shipments', 'decoding.plugin.name' = 'pgoutput', 'slot.name' = 'flink' ); CREATE TEMPORARY TABLE shipments_sink ( shipment_id INT, order_id INT, origin STRING, destination STRING, is_arrived BOOLEAN, order_time TIMESTAMP, PRIMARY KEY (shipment_id) NOT ENFORCED ) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:postgresql://<yourHostname>:<yourPort>/flink_sink', 'table-name' = 'shipments_sink', 'username' = '<yourUserName>', 'password' = '<yourPassWord>' ); INSERT INTO shipments_sink SELECT * FROM shipments;部署并启动作业。


测试与验证。
部署作业运行成功后,即状态为运行中,shipments表中的数据已经同步到目标数据库flink_sink的shipments_sink表。
SELECT * FROM public.shipments_sink;返回结果如下:
shipment_id | order_id | origin | destination | is_arrived | order_time -------------+----------+--------+-------------+------------+--------------------- 1 | 1 | test1 | test1 | f | 2024-09-18 05:45:08 (1 row)在源数据库flink_source的shipments表上执行DML,新增修改也将实时同步。
INSERT INTO public.shipments SELECT 2, 2, 'test2', 'test2', false, now(); UPDATE public.shipments SET is_arrived = true WHERE shipment_id = 1; DELETE FROM public.shipments WHERE shipment_id = 2; INSERT INTO public.shipments SELECT 3, 3, 'test3', 'test3', false, now(); UPDATE public.shipments SET is_arrived = true WHERE shipment_id = 3;shipments表中的数据已经同步更新到目标数据库flink_sink的shipments_sink表。
SELECT * FROM public.shipments_sink;返回结果如下:
shipment_id | order_id | origin | destination | is_arrived | order_time -------------+----------+--------+-------------+------------+--------------------- 1 | 1 | test1 | test1 | t | 2024-09-18 05:45:08 3 | 3 | test3 | test3 | t | 2024-09-18 07:33:23 (2 rows)
Pipeline连接器
以下示例用于说明,如何通过PolarDBO Flink CDC Pipeline连接器,同步PolarDB PostgreSQL版(兼容Oracle) 2.0集群中flink_source库的shipments1表和shipments2表。在调试过程中,Sink使用Print连接器,在生产环境中,请根据业务需求选择合适的连接器。
以下示例仅用于简单验证打包的PolarDBO Flink CDC能够在PolarDB PostgreSQL版(兼容Oracle)上运行。正式使用时,为满足您的业务需求,请参考社区Postgres CDC Pipeline 连接器配置相关参数以满足实际业务需求。
前提准备
PolarDB PostgreSQL版(兼容Oracle)准备
在PolarDB集群购买页面,购买PolarDB PostgreSQL版(兼容Oracle) 2.0集群。
查看集群主地址,如果PolarDB集群和实时计算 Flink 版在同一专有网络内,可直接使用私网地址,否则需要申请公网地址。
设置集群白名单:将Flink实例地址添加到PolarDB集群白名单中。
在控制台创建源数据库flink_source,详细步骤请参考创建数据库。
执行如下语句,在源数据库flink_source中创建shipments1表和shipments2表,并写入数据。
CREATE TABLE public.shipments1 ( shipment_id INT, order_id INT, origin TEXT, destination TEXT, is_arrived BOOLEAN, order_time DATE, PRIMARY KEY (shipment_id) ); ALTER TABLE public.shipments1 REPLICA IDENTITY FULL; INSERT INTO public.shipments1 SELECT 1, 1, 'test1', 'test1', false, now(); CREATE TABLE public.shipments2 ( shipment_id INT, order_id INT, origin TEXT, destination TEXT, is_arrived BOOLEAN, order_time DATE, PRIMARY KEY (shipment_id) ); ALTER TABLE public.shipments2 REPLICA IDENTITY FULL; INSERT INTO public.shipments2 SELECT 1, 1, 'test1', 'test1', false, now();
实时计算 Flink 版准备
登录实时计算控制台,购买实时计算 Flink 版实例,详细操作请参考开通实时计算Flink版。
说明建议实时计算 Flink 版的地域和专有网络和PolarDB集群保持一致,连接地址可以直接使用PolarDB集群主地址的私网地址。
创建Flink作业
登录实时计算控制台,新建一个数据摄入草稿,请参考Flink CDC数据摄入作业快速入门。使用以下数据摄入配置,修改PolarDB集群主地址,端口,账号和密码。
source: type: polardbo name: PolarDB Oracle Source hostname: '<yourHostname>' port: '<yourPort>' username: '<yourUserName>' password: '<yourPassWord>' tables: flink_source.public.shipments[12] decoding.plugin.name: pgoutput slot.name: pgtest sink: type: values name: values Sink print.enabled: true在左侧更多配置中添加上述打包成功的Pipeline连接器。

部署并启动作业。
单击右上角的部署。

进入作业运维页面,单击启动。

测试与验证。
部署作业运行成功后,即状态为运行中。您可以从日志中看到全量阶段的CreateTableEvent和DataChangeEvent。
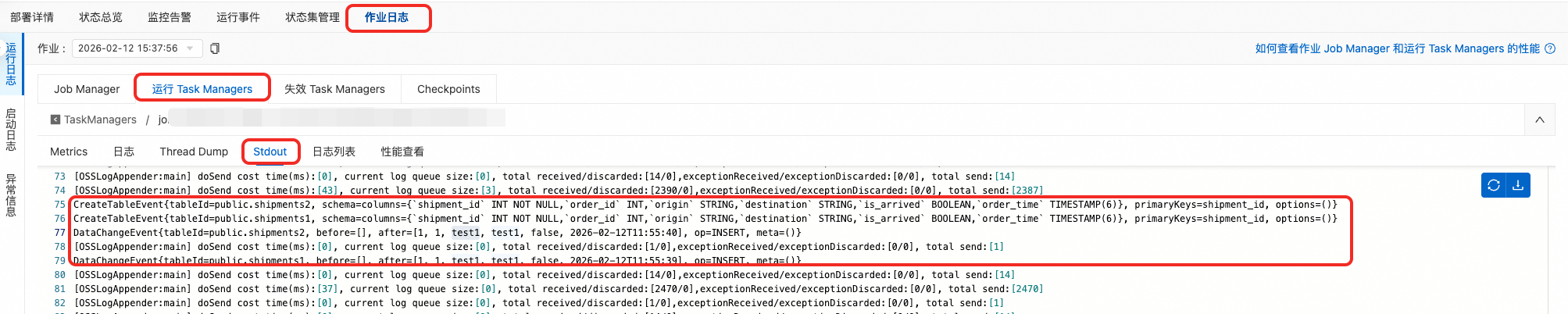
CreateTableEvent{tableId=public.shipments2, schema=columns={`shipment_id` INT NOT NULL,`order_id` INT,`origin` STRING,`destination` STRING,`is_arrived` BOOLEAN,`order_time` TIMESTAMP(6)}, primaryKeys=shipment_id, options=()} CreateTableEvent{tableId=public.shipments1, schema=columns={`shipment_id` INT NOT NULL,`order_id` INT,`origin` STRING,`destination` STRING,`is_arrived` BOOLEAN,`order_time` TIMESTAMP(6)}, primaryKeys=shipment_id, options=()} DataChangeEvent{tableId=public.shipments2, before=[], after=[1, 1, test1, test1, false, 2026-01-07T16:30:44], op=INSERT, meta=()} DataChangeEvent{tableId=public.shipments1, before=[], after=[1, 1, test1, test1, false, 2026-01-07T16:30:44], op=INSERT, meta=()}在源数据库flink_source的shipments1表和shipments2表上执行DML,新增与修改操作也将实时同步。
INSERT INTO public.shipments1 SELECT 2, 2, 'test2', 'test2', false, now(); UPDATE public.shipments1 SET is_arrived = true WHERE shipment_id = 1; DELETE FROM public.shipments1 WHERE shipment_id = 2; INSERT INTO public.shipments1 SELECT 3, 3, 'test3', 'test3', false, now(); UPDATE public.shipments1 SET is_arrived = true WHERE shipment_id = 3; INSERT INTO public.shipments2 SELECT 2, 2, 'test2', 'test2', false, now(); UPDATE public.shipments2 SET is_arrived = true WHERE shipment_id = 1; DELETE FROM public.shipments2 WHERE shipment_id = 2; INSERT INTO public.shipments2 SELECT 3, 3, 'test3', 'test3', false, now(); UPDATE public.shipments2 SET is_arrived = true WHERE shipment_id = 3;您可以从日志中看到增量阶段的DataChangeEvent:
DataChangeEvent{tableId=public.shipments1, before=[], after=[2, 2, test2, test2, false, 2026-01-07T16:44:50], op=INSERT, meta=()} DataChangeEvent{tableId=public.shipments1, before=[1, 1, test1, test1, false, 2026-01-07T16:30:44], after=[1, 1, test1, test1, true, 2026-01-07T16:30:44], op=UPDATE, meta=()} DataChangeEvent{tableId=public.shipments1, before=[2, 2, test2, test2, false, 2026-01-07T16:44:50], after=[], op=DELETE, meta=()} DataChangeEvent{tableId=public.shipments1, before=[], after=[3, 3, test3, test3, false, 2026-01-07T16:44:50], op=INSERT, meta=()} DataChangeEvent{tableId=public.shipments1, before=[3, 3, test3, test3, false, 2026-01-07T16:44:50], after=[3, 3, test3, test3, true, 2026-01-07T16:44:50], op=UPDATE, meta=()} DataChangeEvent{tableId=public.shipments2, before=[], after=[2, 2, test2, test2, false, 2026-01-07T16:44:50], op=INSERT, meta=()} DataChangeEvent{tableId=public.shipments2, before=[1, 1, test1, test1, false, 2026-01-07T16:30:44], after=[1, 1, test1, test1, true, 2026-01-07T16:30:44], op=UPDATE, meta=()} DataChangeEvent{tableId=public.shipments2, before=[2, 2, test2, test2, false, 2026-01-07T16:44:50], after=[], op=DELETE, meta=()} DataChangeEvent{tableId=public.shipments2, before=[], after=[3, 3, test3, test3, false, 2026-01-07T16:44:50], op=INSERT, meta=()} DataChangeEvent{tableId=public.shipments2, before=[3, 3, test3, test3, false, 2026-01-07T16:44:50], after=[3, 3, test3, test3, true, 2026-01-07T16:44:50], op=UPDATE, meta=()}