PolarDB新增支持并行DDL的功能。当数据库硬件资源空闲时,您可以通过并行DDL功能加速DDL执行,避免阻塞后续相关的DML操作,缩短执行DDL操作的窗口期。
适用范围
创建二级索引时,PolarDB集群版本需满足如下条件之一:
PolarDB MySQL版8.0.2版本且修订版本为8.0.2.1.7及以上。
PolarDB MySQL版8.0.1版本且修订版本为8.0.1.1.10及以上。
PolarDB MySQL版5.7版本且修订版本为5.7.1.0.7及以上
创建主键索引时,PolarDB集群版本需满足如下条件之一:
PolarDB MySQL版8.0.2版本且修订版本为8.0.2.2.9及以上。
PolarDB MySQL版8.0.1版本且修订版本为8.0.1.1.31及以上。
如何确认集群版本,详情请参见查询版本号。
注意事项
开启并行DDL功能后,由于并行线程数的增加,硬件资源(如CPU、内存、IO等)的占用也会随之增加,可能会影响同一时间内执行的其他SQL操作,因此建议在业务低峰或硬件资源充足时使用并行DDL。
使用限制
目前并行DDL加速支持创建主键索引和二级索引(不包括全文索引、空间索引和虚拟列上的二级索引)的DDL操作。
背景信息
传统的DDL操作基于单核和传统硬盘设计,导致针对大表的DDL操作耗时较久,延迟过高。以创建二级索引为例,过高延迟的DDL操作会阻塞后续依赖新索引的DML查询操作。多核处理器的发展为并行DDL使用更多线程数提供了硬件支持,而固态硬盘(Solid State Disk,简称SSD)的普及使得随机访问延迟与顺序访问延迟相近,使用并行DDL加速大表的索引创建显得尤为重要。
使用方法
innodb_polar_parallel_ddl_threads
您可以通过如下innodb_polar_parallel_ddl_threads参数开启并行DDL功能:
参数
级别
说明
innodb_polar_parallel_ddl_threads
Session
控制每一个DDL操作的并行线程数。取值范围:1~16。默认值为1,即执行单线程DDL。
若该参数值不为1,当执行创建二级索引操作时将自动开启并行DDL。
说明该参数取值为1的时候,系统默认开启2个并行线程数。
innodb_parallel_build_primary_index
您可以通过如下innodb_parallel_build_primary_index参数控制允许创建主键索引时使用并行DDL功能:
说明如果需要使用并行创建主键索引功能,请前往配额中心,在配额ID为polardb_mysql_pddl_for_pk的操作列,单击申请,申请试用。
参数
级别
说明
innodb_parallel_build_primary_index
Global
控制是否允许创建主键索引时使用并行DDL功能。取值范围如下:
ON:允许创建主键索引时使用并行DDL功能
OFF:不允许创建主键索引时使用并行DDL功能(默认值)
innodb_polar_use_sample_sort
若仅开启并行DDL功能仍不能满足您的需求,您可以通过innodb_polar_use_sample_sort参数对创建索引过程中的排序进行进一步优化。
参数
级别
说明
innodb_polar_use_sample_sort
Session
sample sort优化功能开关,取值范围如下:
ON:开启sample sort优化功能开关
OFF:关闭sample sort优化功能开关(默认值)
innodb_polar_use_parallel_bulk_load
若上述功能仍不能满足您的需求,您还可以通过innodb_polar_use_parallel_bulk_load参数对创建索引树的过程进行进一步优化。
参数
级别
说明
innodb_polar_use_parallel_bulk_load
Session
并行bulk load优化功能开关,取值范围如下:
ON:开启并行bulk load优化功能开关
OFF:关闭并行bulk load优化功能开关(默认值)
性能测试
测试环境
一个规格为16核128 GB的标准版PolarDB MySQL版8.0版本的集群。
集群存储空间为50 TB。
测试表结构
通过如下语句创建一张名为
t0的表:CREATE TABLE t0( a INT PRIMARY KEY, b INT) ENGINE=InnoDB;测试表数据
通过如下语句生成测试数据:
DELIMITER // CREATE PROCEDURE populate_t0() BEGIN DECLARE i int DEFAULT 1; WHILE (i <= $table_size) DO INSERT INTO t0 VALUES (i, 1000000 * RAND()); SET i = i + 1; END WHILE; END // DELIMITER ; CALL populate_t0() ;说明实际测试时请将
$table_size替换成具体的表内记录数,如1000000。本测试分别使用了包含1000000行、10000000行、100000000行、1000000000行记录数的表,以及一张包含1 TB数据量的表。
1 TB数据量的测试用表通过Sysbench工具生成。如何使用Sysbench工具,请参见测试工具。
测试方法
当使用不同的并行线程数(即设置innodb_polar_parallel_ddl_threads参数为1、2、4、8、16和32)时,测试在不同数据量的表中开启并行DDL后,在数据类型为
INT的字段b上创建二级索引带来的DDL执行效率的提升比例。测试结果
仅开启innodb_polar_parallel_ddl_threads参数后,并行DDL加速比结果如下图所示。
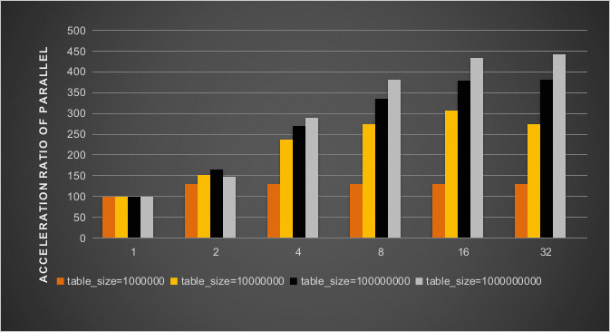
同时开启innodb_polar_parallel_ddl_threads和innodb_polar_use_sample_sort参数后,并行DDL加速比结果如下图所示。
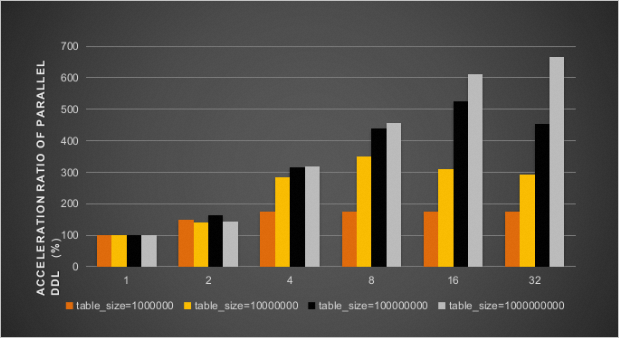
同时开启innodb_polar_parallel_ddl_threads、innodb_polar_use_sample_sort和innodb_polar_use_parallel_bulk_load参数后,并行DDL加速比结果如下图所示。
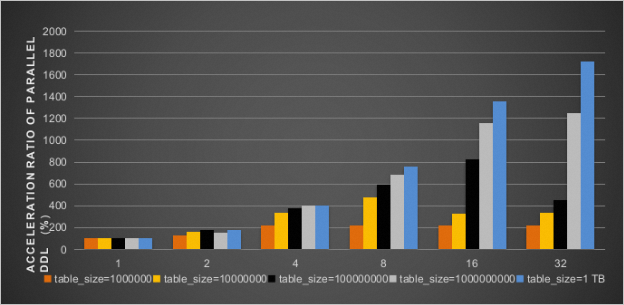
联系我们
若您对DDL操作有任何疑问,请联系我们。