在海量数据上求TopK是一个很经典的问题,特别是衍生出的深翻页查询,给分析型数据库带来了很大的挑战。本文将介绍PolarDB MySQL版的列存索引(In Memory Column Index,IMCI)特性如何应对这样的挑战。
背景
业务系统中普遍存在这样一种场景:根据给定条件筛选一批记录,这些记录按用户指定的条件排序,以分页的方式展示。例如,筛选出某个商家在售的商品,按商品销量排序,以分页的方式展示。上述场景在数据库中,通常以ORDER BY column LIMIT n, m这样的查询语句实现。
假设业务系统中每页展示100条记录:
通过
ORDER BY column LIMIT 0, 100可以展示第1页的数据;通过
ORDER BY column LIMIT 1000000, 100可以展示第10001页的数据。
在没有索引的情况下,此类查询在数据库中是通过基于堆的经典TopK算法来实现的,逻辑如下:在内存中维护一个大小为K的堆,堆顶元素是最小的元素,将遍历到的数据与堆顶元素比较,如果比堆顶元素大,替换堆顶元素,并重建堆。遍历完数据后,堆中的元素即为前K个最大的元素。当翻页较浅时(如上文中展示第1页),K较小,基于堆的TopK算法非常高效。
然而,业务场景中也存在翻页较深的场景(下文中简称“深翻页”),例如上文中展示第10001页。该场景下的K非常大,内存中可能无法缓存大小为K的堆,也就无法使用上述方式获得查询结果。即便内存充足,由于维护堆的操作访问内存是乱序的,当堆非常大时,TopK算法的访存效率较差,最终的性能表现也差强人意。
PolarDB MySQL版IMCI最初也采用了上述方式来实现分页查询,并在内存不足以缓存大小为K的堆时,采用了全表排序后取相应的位置记录的方式,所以在深翻页时的性能表现也不是非常理想。为此,在分析了深翻页场景的特点和传统方案存在的问题,并调研了相关研究和工业界现有方案后,PolarDB MySQL版重新设计了IMCI的Sort/TopK算子。在测试场景中,重新设计的Sort/TopK算子显著提升了IMCI在深翻页场景的性能表现。
业界方案调研
TopK是一个非常经典的问题,存在多种方案来高效地实现TopK查询,这些方案的核心都在于减少对非结果集数据的操作。已经在工业界中应用的方案主要有如下三种:
基于Priority Queue的TopK算法
请参见背景部分内容描述。
归并排序时基于offset和limit做truncate
当内存不足以缓存大小为K的Priority Queue时,一些数据库会使用归并排序来处理TopK问题(例如PolarDB IMCI、ClickHouse、SQL Server、DuckDB)。因为TopK算法只需要获取排在第[offset, offset+limit)位的记录,所以在每一次归并排序时,不需要对所有数据做排序,而是仅输出长度为offset+limit的新的sorted run即可。上述merge时的truncation可以在保证结果正确性的同时减少对非结果集数据的操作。

Self-sharpening Input Filter
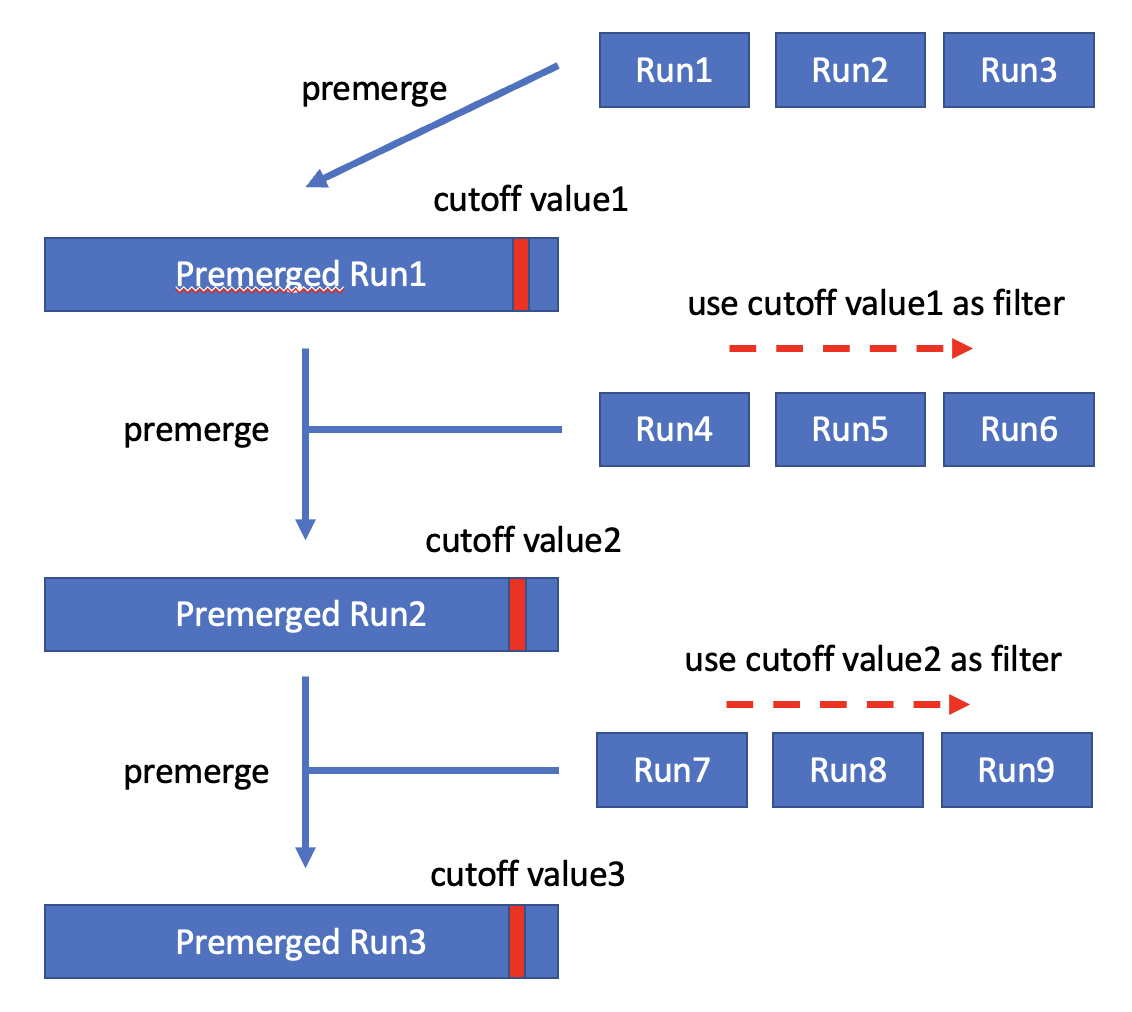
该方案最初是在Goetz Graefe的论文中提出的,云数据库ClickHouse目前采用了这种方案。该方案在执行过程中会维护一个cutoff value,并且保证大于cutoff value的记录一定不会出现在TopK的结果集中。在生成new sorted run时,方案会使用当前的cutoff value对数据进行过滤。在生成new sorted run之后,如果K小于new sorted run的长度,则会使用new sorted run中第K条记录替换当前cutoff value。由于new sorted run中的数据都是经过old cutoff value过滤的,因此必定有new cutoff value <= old cutoff value,即cutoff value是一个不断sharpening的值。最后只需要合并这些过滤后的sorted run即可得到结果集。
通过一个简单的例子来说明上述算法:假设当前TopK查询中K=3,读取第一批数据后生成的sorted run为(1, 2, 10, 15, 21),则cutoff value更新为10。接下来使用cutoff value=10过滤第二批数据,生成的第二个sorted run为(2, 3, 5, 6, 8),则cutoff value更新为5。然后读取并过滤第三批数据,生成的第三个sorted run为(1, 2, 3, 3, 3),则cutoff value更新为3。依此类推,不断sharpen cutoff value从而在接下来过滤更多的数据。
如果TopK查询中K大于单个sorted run的长度,该方案会积累足够的sorted run(包含的记录数量大于K),然后对这些sorted run提前进行merge,从而获得cutoff value。接下来会使用cutoff value进行过滤并继续积累足够的sorted run,从而获得更小的cutoff value,依此类推。整个执行过程和K小于单个sorted run的情况是类似的,区别在于需要merge足够的sorted run才能获得cutoff value。
问题分析
深翻页是TopK问题中一个较为特殊的场景,特殊之处在于所求的K特别大,但实际结果集很小。例如上文中展示第10001页的例子,对于ORDER BY column LIMIT 1000000, 100,K=1,000,100,但最终结果集只包含100条记录。该特点会给上一节中所述方案带来如下挑战:
当内存充足时,如果采用基于Priority Queue的TopK算法,则需要维护一个非常大的Priority Queue,队列操作对内存的访问操作是乱序的,访存效率较差,影响算法实际运行的性能。
当内存不足时,如果使用归并排序并基于offset和limit做truncate,则在归并排序的前期阶段,sorted run的长度可能小于offset+limit,无法进行truncate,所有数据都将参与排序,truncate的实际效果受到影响。
本文中的内存充足是指,算法中用于管理至少K条记录的数据结构可以在执行内存中缓存,而不是TopK查询的输入数据可以在执行内存中缓存。实际上本文讨论的场景,TopK查询的输入数据都是远大于执行内存的。
另外,从系统设计的角度上看,设计深翻页的解决方案时还应考虑如下两点:
是否采用不同方案来实现深翻页和浅翻页?如果需要使用不同的方案来处理两种场景,如何判断深浅翻页的界线?
如何根据可用执行内存的大小自适应地选择内存算法或磁盘算法?
方案设计
总体设计
综合上述调研和分析,基于现有的成熟方案,针对深翻页问题,PolarDB MySQL版重新设计了IMCI的Sort/TopK算子:
内存充足时,采用如下的内存算法:
采用Self-sharpening Input Filter的设计,避免访存效率的问题。
并在此基础上利用SIMD指令提升过滤效率。
深浅翻页均采用该内存算法,不需要判断深浅翻页的界线。
内存不足时,采用如下的磁盘算法:
采用归并排序时基于offset和limit做truncate的方案。
并在此基础上利用ZoneMap在归并排序的前期阶段做pruning,尽可能地减少对非结果集数据的操作。
动态选择内存磁盘算法:不依赖固定的阈值来选择使用内存算法或磁盘算法,而是在执行过程中根据可用执行内存的大小,动态调整所用算法。
由于Self-sharpening Input Filter和归并排序时基于offset和limit做truncate的方案在前文中已经介绍,因此接下来仅介绍选择这两种方案的原因,并介绍利用SIMD指令提升过滤效率、利用ZoneMap做pruning以及动态选择内存磁盘算法的部分。
SIMD Accelerated Self-sharpening Input Filter
在内存充足时,直接采用Self-sharpening Input Filter的设计,主要基于两个原因:
Self-sharpening Input Filter不管是使用cutoff value进行过滤,还是pre-merge,访问内存的模式都是顺序的,可以避免Priority Queue访存效率的问题。
该设计无论翻页深浅都具有优异的性能,在应用时不需要考虑深浅翻页的界线。
实际上,Self-sharpening Input Filter在某种程度上和基于Priority Queue的算法是类似的,cutoff value类似堆顶,都用于过滤后续读取的数据,两者的不同之处在于,基于Priority Queue的算法会实时更新堆顶,而Self-sharpening Input Filter则将数据积累在sorted run中,以batch的方式更新cutoff value。
使用cutoff value进行过滤是Self-sharpening Input Filter中很重要的过程,涉及数据比较,操作简单重复但非常频繁,因此使用SIMD指令来加速这一过程。由于cutoff value过滤和TableScan中使用Predicate过滤是类似的,因此在具体实现中直接复用处理Predicate的表达式,提升过滤的效率,减少计算TopK的时间。
Zonemap-based Pruning
在内存不足时,采用归并排序,并基于offset和limit做truncate,主要原因如下:
如果在内存不足时继续使用Self-sharpening Input Filter的设计,就需要将积累的sorted run落盘,并且在pre-merge时同样使用外排序算法,产生大量的读写磁盘的操作,相对于内存充足场景下的Self-sharpening Input Filter有额外的开销。当K非常大时,pre-merge时的外排序可能还会涉及大量非结果集数据,因为最终只需要获取排在第[offset, offset + limit)位的记录,而不关心排在第[0, offset)位的记录。
在这种场景下,可以使用归并排序,在生成sorted run的阶段仅将sorted run落盘,然后使用统计信息进行pruning,避免不必要的读写磁盘的操作,也可以尽可能地避免对非结果集数据的操作。
以下图为例来说明使用统计信息进行pruning的原理。下图中,箭头表示数轴,代表sorted run的矩形的左右两端在数轴上对应的位置表示sorted run的min/max值,Barrier表示pruning所依赖的一个阈值。 ARRIER
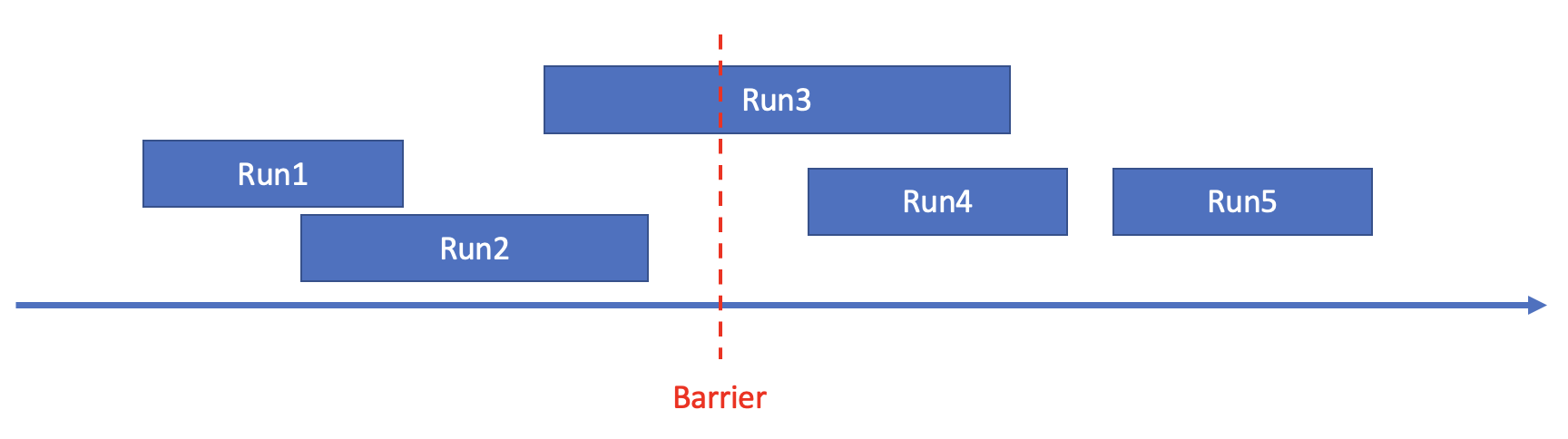
任意一个Barrier可以将所有sorted run分为三类:
类型A:min value of sorted run<Barrier&&max value of sorted run<Barrier,如上图中Run1,Run2。
类型B:min value of sorted run<Barrier&&max value of sorted run>Barrier,如上图中Run3。
类型C:min value of sorted run>Barrier&&max value of sorted run>Barrier,如上图中Run4,Run5。
对于任意一个Barrier,如果类型A和类型B中的数据量<TopK查询中的offset,那么类型A中的数据必然排在第[0, offset)位,类型A中的sorted run可以不参与后续的merge。
对于任意一个Barrier,如果类型A中的数据量>TopK查询中的offset+limit,那么类型C中的数据必然排在第[offset+limit, N)位,类型C中的sorted run可以不参与后续的merge。
根据上述原理,使用统计信息进行pruning的具体流程如下:
构建包含sorted run的min/max信息的Zonemap。
基于Zonemap寻找一个尽可能大的Barrier1满足类型A和类型B中的数据量<TopK查询中的offset。
基于Zonemap寻找一个尽可能小的Barrier2满足类型A中的数据量>TopK查询中的offset+limit。
使用Barrier1和Barrier2对相关sorted run进行pruning。
动态选择内存磁盘算法
内存算法和磁盘算法不同,如果使用一个固定的阈值来作为选择内存算法或磁盘算法的依据(比如K小于阈值时使用内存算法,否则使用磁盘算法),那么针对不同的可用执行内存就需要设置不同的阈值,带来了人工干预的开销。
因此PolarDB MySQL版设计了一个简单的回退机制,可以在执行过程中根据可用执行内存的大小,动态调整所用算法:
无论可用执行内存有多大,首先尝试以内存算法计算TopK。
在内存算法的执行过程中,如果内存始终都是充足的,直接使用内存算法完成整个计算过程。
在内存算法的执行过程中,如果出现内存不足的情况(例如,K比较大时,可用执行内存不足以缓存足够的sorted run使其包含的记录数量大于K,或者可用执行内存不足以完成pre-merge的过程),那么执行回退机制。
回退机制:采集内存中已积累的sorted run的min/max信息,以便于后续使用Zonemap进行pruning,然后将sorted run落盘,这些sorted run将会参与磁盘算法的计算过程。
执行完回退机制后,使用磁盘算法完成整个计算过程。
由于内存算法和磁盘算法采用相同的数据组织格式,因此回退机制并不需要对数据进行重新组织,开销较小。另外,内存算法只会过滤非结果集的数据,因此直接使用内存算法已积累的sorted run参与磁盘算法的计算过程不会有正确性的问题。
其他
延迟物化
延迟物化是一个工程实现方面的优化,指的是在生成sorted run时仅物化RowID和ORDER BY相关的表达式(列),在计算出TopK的结果集后,再根据结果集中的RowID从存储上获取查询需要输出的列。延迟物化相比于在生成sorted run时就物化查询需要输出的所有列有两个优势:
物化RowID的空间占用更小,在可用执行内存一定的情况下,可以使用内存算法处理更大的数据量。
计算TopK的过程需要调整数据顺序,涉及对数据的Copy/Swap。如果在生成sorted run时就物化查询需要输出的所有列,则计算过程中对一条记录的Copy/Swap需要对每一列都进行相应操作,带来很大的overhead。而如果仅物化RowID,则可以降低Copy/Swap的代价。
延迟物化的不足之处在于根据结果集中的RowID从存储上获取查询需要输出的列时,可能会产生一些随机IO。分析后发现深翻页场景虽然K特别大,但实际结果集很小,因此使用延迟物化时随机IO产生的overhead较小。
计算下推
应用Self-sharpening Input Filter时,会将不断更新的cutoff value下推至table scan算子,作为SQL中一个新的predicate,在table scan算子获取数据时根据这个新的predicate,复用pruner对pack(或称为row group)进行过滤。
计算下推可以从两个方面提升TopK查询的性能:
减少IO:table scan时避免读取仅包含非结果集数据的pack/row group。
减少计算:被过滤的pack/row group中的数据将不再参与table scan上层算子的后续计算。
测试结果
在TPCH 100 GB的数据集上对方案进行简单的验证:
select
l_orderkey,
sum(l_quantity)
from
lineitem
group by
l_orderkey
order by
sum(l_quantity) desc
limit
1000000, 100;测试结果如下:
PolarDB IMCI | ClickHouse | MySQL |
7.72 sec | 23.07 sec | 353.15 sec |