Hash Join是社区版MySQL 8.0版本中引入的新Join方式,可以大幅提升分析型查询的执行性能。PolarDB MySQL版8.0版本提供了对Hash Join的并行执行支持,并不断丰富其并行执行策略。本文介绍如何在PolarDB的并行查询中使用Hash Join功能。
简单并行Hash Join
前提条件
集群版本需为PolarDB MySQL版8.0集群版,且Revision version为8.0.2.1.0或以上,您可以参见查询版本号确认集群版本。
并行策略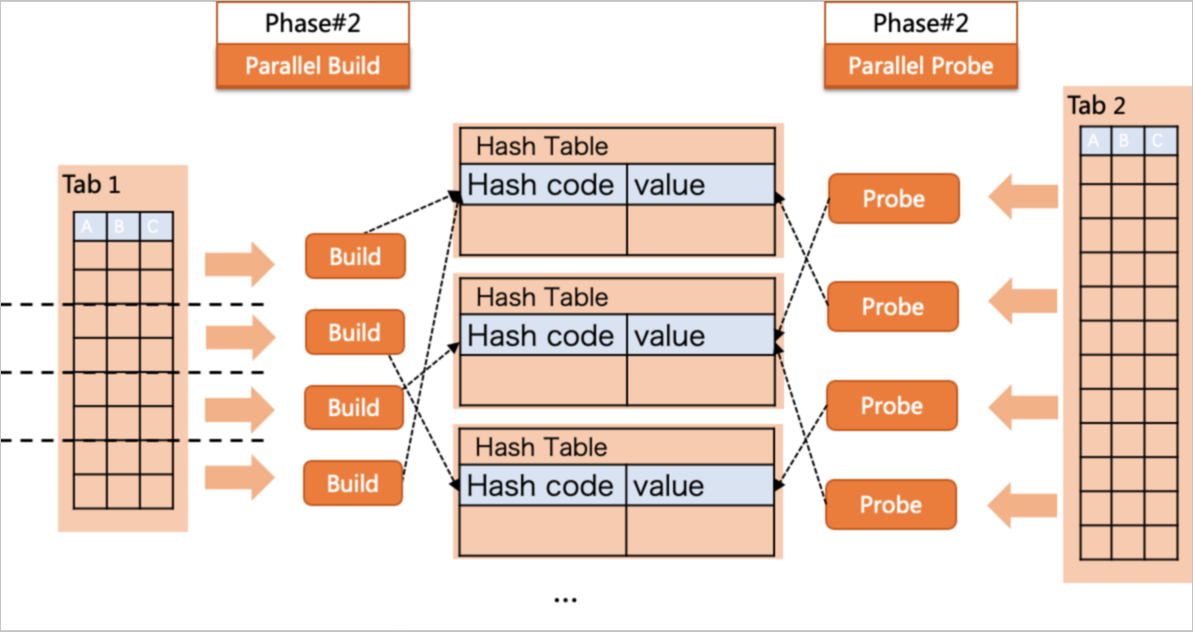
上图中是并行度为4的并行查询计划(即PolarDB会启用4个Worker来执行查询)。其中t1表会执行Parallel Scan,即由4个Worker分别扫描这个表。每个Worker使用t1的一部分数据建立各自的Hash表,再和整个t2表执行JOIN操作,最后收集(Gather)在Leader中,得到整个查询的结果。
使用方法
语法:
目前在PolarDB中Hash Join只能通过
EXPLAIN FORMAT=TREE语句来显示。示例:
如下示例中创建了2个表,且在表里插入了一些数据:
CREATE TABLE t1 (c1 INT, c2 INT); CREATE TABLE t2 (c1 INT, c2 INT); INSERT t1(c1, c2) WITH RECURSIVE seq AS ( SELECT 1 AS a, 1 AS b UNION ALL SELECT a + 1, b + 1 FROM seq WHERE a < 1000 ) SELECT a,b FROM seq; INSERT INTO t2 SELECT * FROM t1;查看SQL语句的查询计划:
EXPLAIN FORMAT=TREE SELECT /*+ PQ_DISTRIBUTE(t1 PQ_NONE) PQ_DISTRIBUTE(t2 PQ_NONE) */ * FROM t1 JOIN t2 ON t1.c1 = t2.c2;如下是上述2个表的JOIN查询计划:
EXPLAIN FORMAT=TREE EXPLAIN -> Gather (slice: 1; workers: 4) (cost=10.82 rows=4) -> Parallel inner hash join (t2.c2 = t1.c1) (cost=0.57 rows=1) -> Parallel table scan on t2, with parallel partitions: 1 (cost=0.03 rows=1) -> Parallel hash -> Parallel table scan on t1, with parallel partitions: 1 (cost=0.16 rows=1)上述是并行度为4的并行查询计划(即PolarDB会启用4个Worker来执行查询)。其中
t1表会执行Parallel Scan,即由4个Worker分扫这个表,每个Worker使用t1的一部分数据建立各自的Hash表,再和整个t2表执行JOIN操作,最后收集(Gather)在Leader,得到整个查询的结果。
Shuffle Hash Join
前提条件
集群版本需为PolarDB MySQL版8.0集群版,且Revision version为8.0.2.2.0或以上,您可以参见查询版本号确认集群版本。
并行策略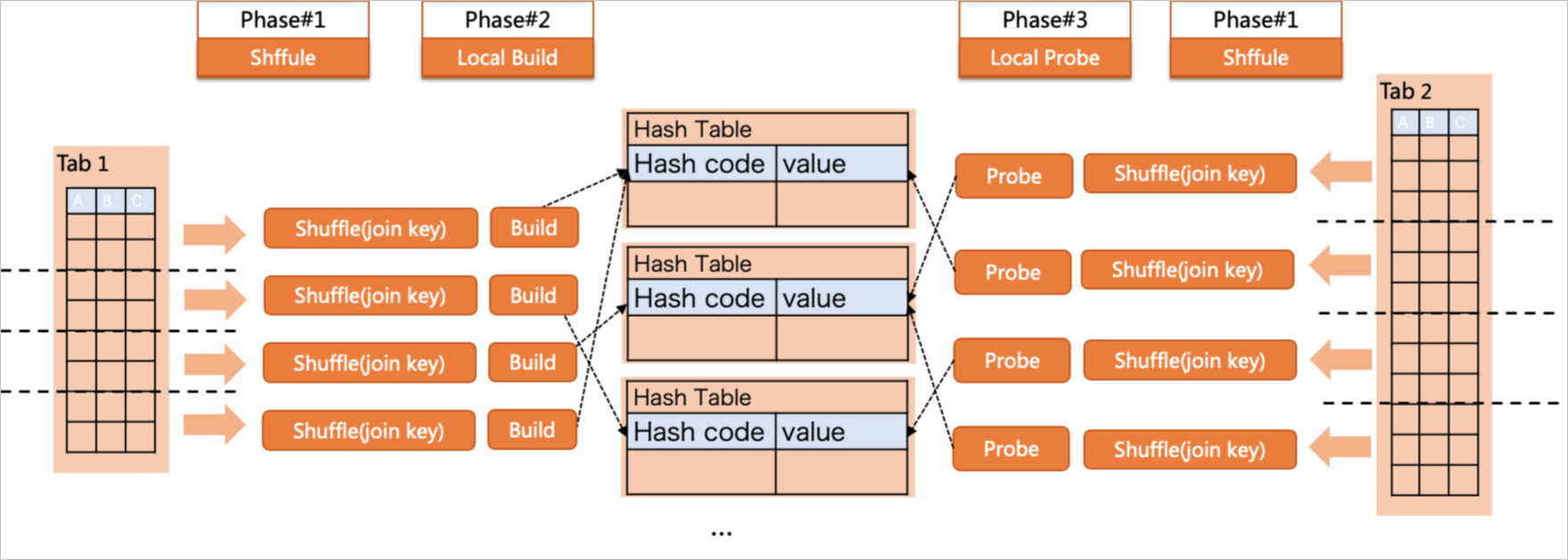
Parallel hash join实现了build+probe全阶段的并行执行,但如果共享的hash table较大,会导致转储到磁盘的IO操作,影响查询执行效率。因此引入了partition hash join来解决此问题。如上图所示,其中t1表会执行Parallel Scan,即由4个Worker分别扫描这个表,每个Worker使用t1的一部分数据,然后将数据按照join key做repartition的分发到下一个阶段的Worker中,在各个Worker内构建本地容量更小的hash table。完成构建后,会开始对t2表执行Parallel Scan,分别扫描这张表,同样按照join key做repartition的分发到已经完成hash table构建的Worker中。在Worker线程内完成分片数据的probe操作,最后收集(Gather)在Leader中,得到整个查询的结果。
使用方法
语法:
目前在PolarDB中Hash Join只能通过
EXPLAIN FORMAT=TREE语句来显示。示例:
如下示例中创建了2个表,且在表里插入了一些数据:
CREATE TABLE t1 (c1 INT, c2 INT); CREATE TABLE t2 (c1 INT, c2 INT); INSERT t1(c1, c2) WITH RECURSIVE seq AS ( SELECT 1 AS a, 1 AS b UNION ALL SELECT a + 1, b + 1 FROM seq WHERE a < 1000 ) SELECT a,b FROM seq; INSERT INTO t2 SELECT * FROM t1;查看SQL语句的查询计划:
EXPLAIN FORMAT=TREE SELECT * FROM t1 JOIN t2 ON t1.c1 = t2.c2;如下是上述2个表的JOIN查询计划:
EXPLAIN FORMAT=TREE EXPLAIN | -> Gather (slice: 1; workers: 2) (cost=33.38 rows=4) -> Inner hash join (t2.c1 = t1.c1) (cost=23.08 rows=2) -> Repartition (hash keys: t2.c1; slice: 2; workers: 1) (cost=11.35 rows=2) -> Parallel table scan on t2, with parallel partitions: 1 (cost=0.65 rows=4) -> Hash -> Repartition (hash keys: t1.c1; slice: 3; workers: 1) (cost=11.35 rows=2) -> Parallel table scan on t1, with parallel partitions: 1 (cost=0.65 rows=4)