本文为您介绍如何使用DLC提供的算力健康检测能力。
功能介绍
在AI训练场景,可能会遇到以下问题:
资源故障导致任务中断与GPU资源浪费:在任务花费一定时间加载模型Checkpoint或其他初始化操作后,由于申请的资源存在故障,无法顺利开始训练,需要调查定位故障问题并重新提交任务。该过程中会导致GPU资源的浪费。
性能问题定位与测试手段不足:在任务运行阶段,如果发现模型训练性能下降,可能是慢节点导致的,但缺少快捷有效的问题定位方法。此外,资源组内机器的GPU算力和通信性能测试也欠缺便捷且可靠的基准程序。
针对上述问题,DLC提供了算力健康检测(SanityCheck)功能,旨在对分布式训练任务的算力资源健康度与性能进行检查。在创建DLC训练任务时可以开启该功能,健康检测会对参与训练的资源进行全面检测,自动隔离故障节点,并触发后台自动化运维流程,有效减少任务训练初期遇到问题的可能性,提升训练成功率。此外,在检测完成后,会给出有关GPU算力以及通信性能的检测报告,可以帮助识别和定位可能导致任务训练性能下降的问题因素,整体提升问题诊断的效率。
使用限制
目前,该功能仅支持使用灵骏智算资源创建的PyTorch训练任务,且要求任务资源的GPU(卡数)为整机配置。灵骏智算资源目前仅对白名单用户开放,若有需要,请联系您的商务经理。
开启健康检测
通过控制台
在PAI控制台中创建DLC训练任务时,通过配置以下关键参数,开启健康检测功能。任务成功创建后,系统将占用一定的时间用于检测资源健康度和可用性,并给出检测结果。
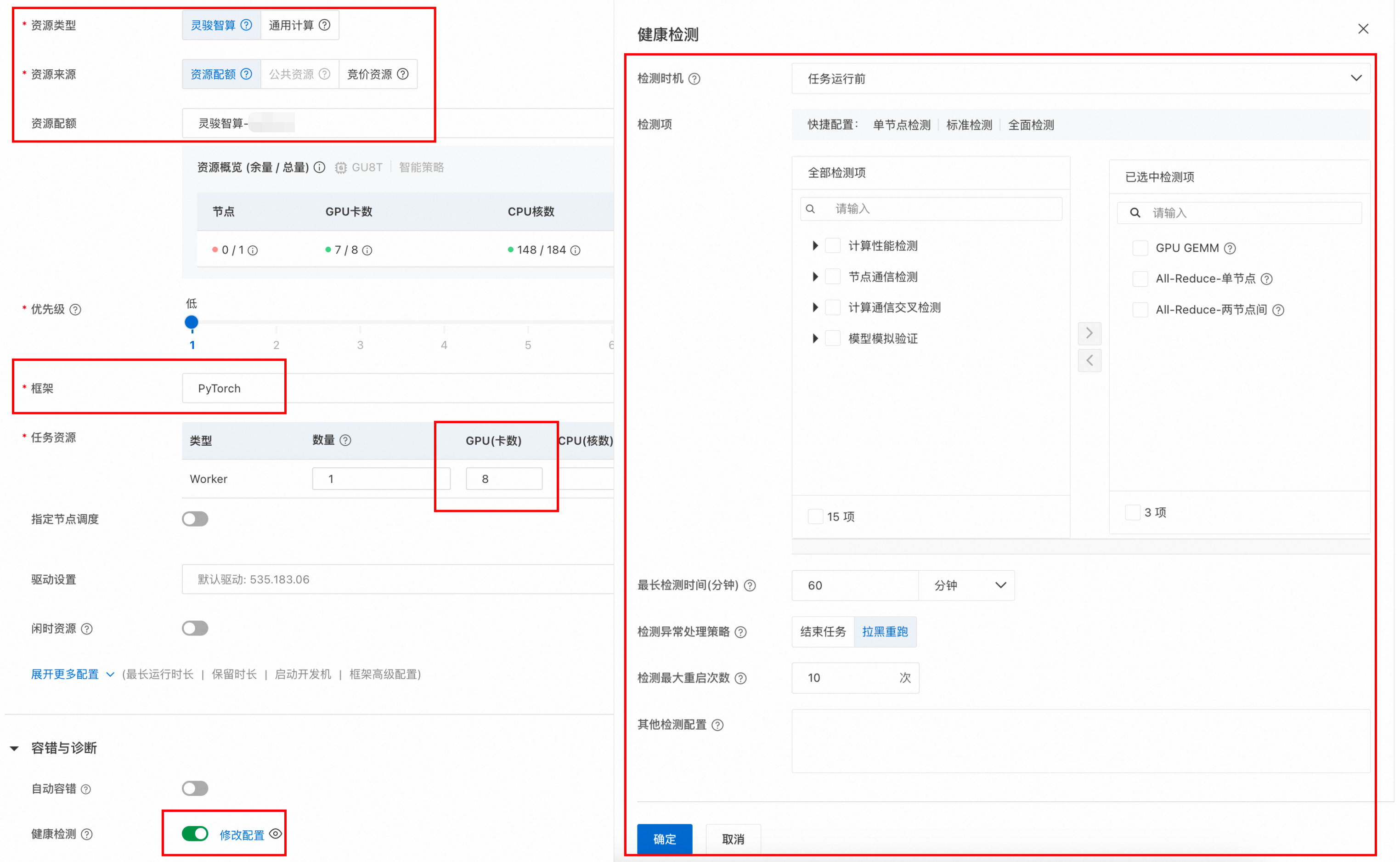
其中关键参数配置说明如下:
资源信息配置:
参数
描述
资源类型
选择灵骏智算资源。
资源来源
选择资源配额。
资源配额
选择已创建的灵骏智算资源配额。如何创建资源配额,请参见创建资源配额。
框架
选择PyTorch。
任务资源
GPU(卡数)需要是整机配置。
容错与诊断配置:打开健康检测开关,并配置以下参数:
参数
描述
检测时机
任务运行前(默认):即任务获取到资源后,先基于该训练任务的算力节点进行预先检测,再执行用户代码。
任务重启后:即当任务运行异常,AIMaster自动容错将任务重启后,进行算力健康检测。
说明选择该配置项时,必须打开自动容错功能。更多内容介绍,请参见AIMaster:弹性自动容错引擎。
检测项
检测项包括 计算性能检测、节点通信检测、计算通信交叉检测,以及模型模拟验证四大类检测。更多检测项说明及推荐场景,请参见附录:检测项说明。
默认开启GPU GEMM(用于检测GPU GEMM性能情况)、All-Reduce(用于检测节点通信性能,识别通信慢节点/故障节点)检测。
检测项支持搜索或勾选。您也可以选择快捷配置,一键快速选定检测项模板。
最长检测时间
健康检测最长运行时间,默认为60分钟。若检测超时,会触发检测异常处理策略。
检测异常处理策略
当健康检测未通过时,系统将根据您选择的处理策略,对任务进行操作:
结束任务:当识别到故障或可疑节点,任务将终止并标记为检测未通过。
拉黑重跑:当识别到故障或可疑节点,系统将自动拉黑该节点,重启任务并重跑检测,直到检测全部通过。
检测最大重启次数
当检测处理策略为“拉黑重跑”时,支持配置最大重启次数,默认为10次。当超过最大重启次数,任务自动失败。
其他检测配置
默认为空,支持高级参数配置。
查看检测结果
健康检测状态说明
DLC任务在健康检测中的相关状态项如下:
检测中:正在进行算力健康检测环节。
检测未通过:在执行算力健康检测过程中,如果检测出异常节点,或检测超时,状态将显示为检测未通过。
检测通过:算力健康检测全部通过后,任务将直接进入运行中的状态。
查看健康检测结果
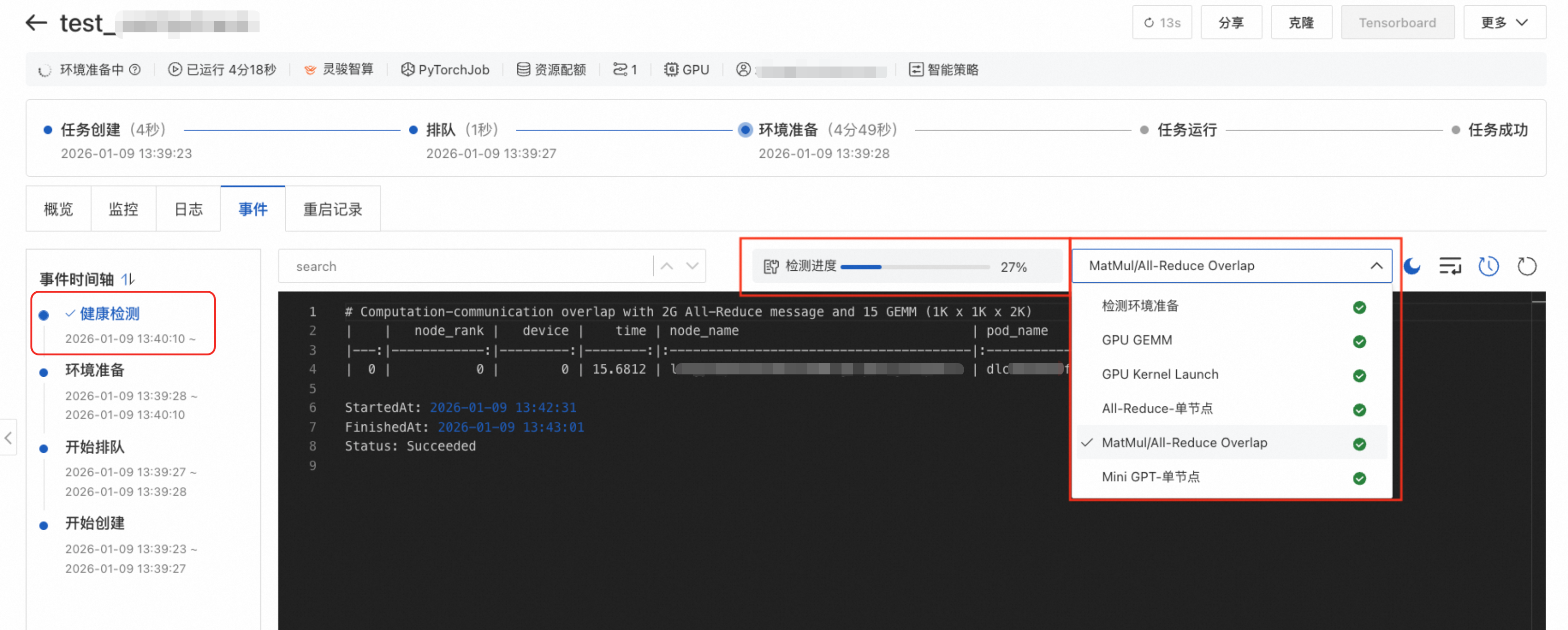
通过控制台
DLC任务详情页,事件页签,单击健康检测,可以查看检测进度及检测结果。
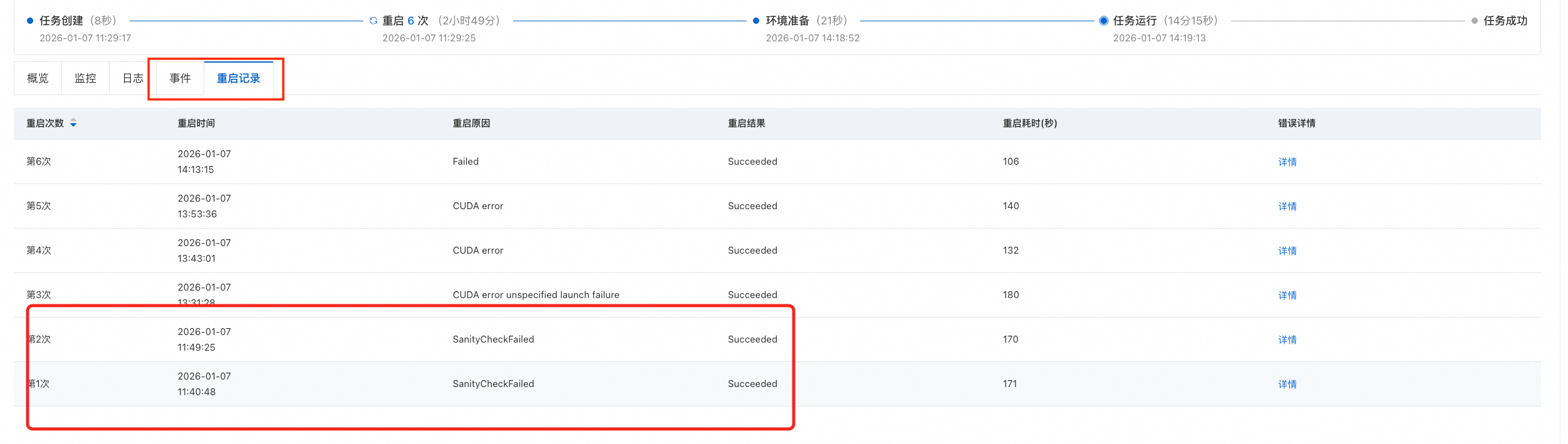
单击重启记录页签,可以查看重启次数、重启原因、重启结果等信息。
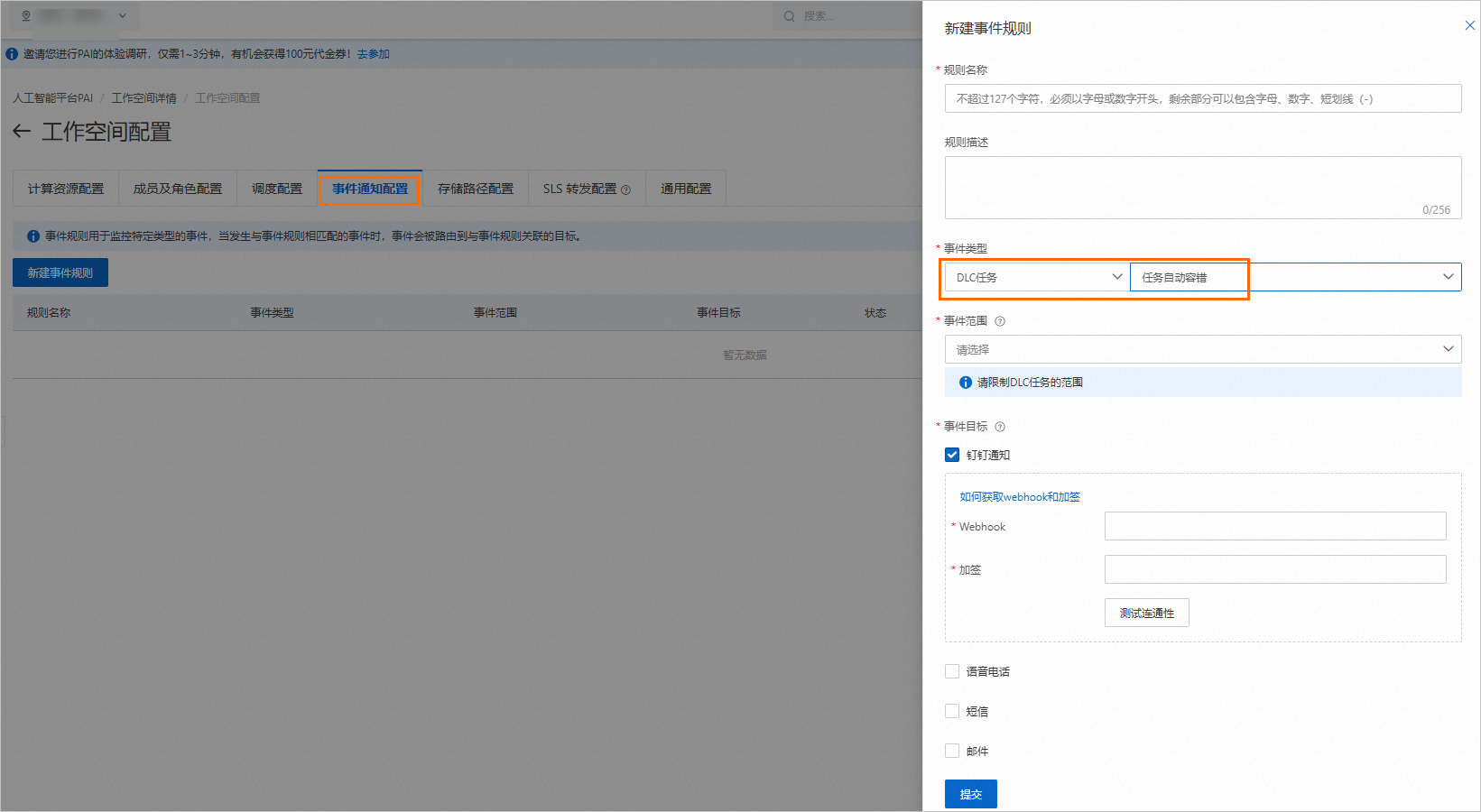
配置消息通知
您可以在PAI工作空间的事件通知配置中创建消息通知规则,其中事件类型选择DLC任务>任务自动容错,其他参数配置详情,请参见消息通知。当算力健康检测未通过时,会发送消息通知。
工作空间创建消息通知使用说明: 事件通知配置。
附录:检测项说明
预估检测时长以2台机器为单位,数值仅供参考,请以实际情况为准。
检测项 | 含义说明(推荐场景) | 预估检测时长 | |
计算性能检测 | GPU GEMM | 用于检测GPU GEMM性能情况,可识别:
| 1 分钟 |
GPU Kernel Launch | 用于检测 GPU Kernel 启动延迟情况,可识别:
| 1 分钟 | |
节点通信检测 | All-Reduce | 用于检测节点通信性能,识别通信慢节点/故障节点。在不同的通信模式下,可识别:
| 单个集合通信检测 5 分钟 |
All-to-All | |||
All-Gather | |||
Multi-All-Reduce | |||
Network Connectivity | 用于检测机头或机尾网络连通性,识别通信连通异常节点。 | 2 分钟 | |
计算通信交叉检测 | MatMul/All-Reduce Overlap | 用于检测通信kernel和计算kernel重叠时单节点的性能情况,可识别:
| 1 分钟 |
模型模拟验证 | Mini GPT | 使用模型模拟验证AI系统可靠性,可识别:
| 1 分钟 |
Megatron GPT | 5 分钟 | ||
ResNet | 2 分钟 | ||