最大连通子图算法用于识别无向图中最大的连通部分,即图中最大的节点集合,其中任意两节点间都可通过路径相连。该算法常用于网络分析、图像处理等领域。它通过深度优先搜索(DFS)或广度优先搜索(BFS)来遍历图,识别所有连通组件,再从中找出包含节点最多的子图。
配置组件
方法一:可视化方式
在Designer工作流页面添加最大连通子图组件,并在界面右侧配置相关参数:
参数类型 | 参数 | 描述 |
字段设置 | 起始节点 | 边表的起点所在列。 |
结束节点 | 边表的终点所在列。 | |
执行调优 | 进程数量 | 作业并行执行的节点数。数字越大并行度越高,但是框架通讯开销会增大。 |
进程内存 | 单个作业可使用的最大内存量,单位:MB,默认值为4096。 如果实际使用内存超过该值,会抛出 | |
数据切分大小 | 数据切分的大小,单位:MB,默认值为64。 |
方法二:PAI命令方式
使用PAI命令配置最大连通子图组件参数。您可以使用SQL脚本组件进行PAI命令调用,详情请参见场景4:在SQL脚本组件中执行PAI命令。
PAI -name MaximalConnectedComponent
-project algo_public
-DinputEdgeTableName=MaximalConnectedComponent_func_test_edge
-DfromVertexCol=flow_out_id
-DtoVertexCol=flow_in_id
-DoutputTableName=MaximalConnectedComponent_func_test_result;参数 | 是否必选 | 默认值 | 描述 |
inputEdgeTableName | 是 | 无 | 输入边表名。 |
inputEdgeTablePartitions | 否 | 全表读入 | 输入边表的分区。 |
fromVertexCol | 是 | 无 | 输入边表的起点所在列。 |
toVertexCol | 是 | 无 | 输入边表的终点所在列。 |
outputTableName | 是 | 无 | 输出表名。 |
outputTablePartitions | 否 | 无 | 输出表的分区。 |
lifecycle | 否 | 无 | 输出表的生命周期。 |
workerNum | 否 | 未设置 | 作业并行执行的节点数。数字越大并行度越高,但是框架通讯开销会增大。 |
workerMem | 否 | 4096 | 单个作业可使用的最大内存量,单位:MB,默认值为4096。 如果实际使用内存超过该值,会抛出 |
splitSize | 否 | 64 | 数据切分的大小,单位:MB。 |
使用示例
添加SQL脚本组件,输入以下SQL语句生成训练数据。
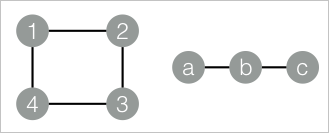
drop table if exists MaximalConnectedComponent_func_test_edge; create table MaximalConnectedComponent_func_test_edge as select * from ( select '1' as flow_out_id,'2' as flow_in_id union all select '2' as flow_out_id,'3' as flow_in_id union all select '3' as flow_out_id,'4' as flow_in_id union all select '1' as flow_out_id,'4' as flow_in_id union all select 'a' as flow_out_id,'b' as flow_in_id union all select 'b' as flow_out_id,'c' as flow_in_id )tmp; drop table if exists MaximalConnectedComponent_func_test_result; create table MaximalConnectedComponent_func_test_result ( node string, grp_id string );对应的数据结构图:
添加SQL脚本组件,输入以下PAI命令进行训练。
drop table if exists ${o1}; PAI -name MaximalConnectedComponent -project algo_public -DinputEdgeTableName=MaximalConnectedComponent_func_test_edge -DfromVertexCol=flow_out_id -DtoVertexCol=flow_in_id -DoutputTableName=${o1};右击上一步的组件,选择查看数据 > SQL脚本的输出,查看训练结果。
| node1 | grp_id | | ----- | ------ | | a | c | | b | c | | c | c | | 1 | 4 | | 2 | 4 | | 3 | 4 | | 4 | 4 |