数据视图算法在机器学习中是指对数据集进行可视化和探索性分析的方法。它通过图表、表格或其他可视化工具展示数据的结构、分布和关系,帮助用户理解数据特征、识别模式和发现异常。此算法在数据预处理和特征工程阶段尤为重要,有助于为后续的建模和分析提供直观的参考。
组件配置
方式一:可视化方式
在Designer工作流页面添加数据视图组件,并在界面右侧配置相关参数:
参数类型 | 参数 | 描述 |
字段设置 | 选择特征列 | 指定要进行可视化或分析的特征列,以便在图表或表格中展示这些特征的分布和关系。 |
选择目标列 | 指定用于预测或分析的目标变量(通常是标签或响应变量)。 | |
枚举特征 | 勾选的特征将被视作枚举特征处理。 | |
k:v,k:v稀疏数据格式 | 是否采用KV格式的稀疏数据。 | |
参数设置 | 连续特征离散区间数 | 用于将连续型特征划分为有限个离散区间,以便于可视化和分析。 |
执行调优 | 计算核心数 | 计算的核心数,取值范围为正整数。 |
每个核心内存 | 每个核心的内存,取值范围为1 MB~65536 MB。 |
方式二:PAI命令方式
使用PAI命令配置数据视图组件参数。您可以使用SQL脚本组件进行PAI命令调用,详情请参见场景4:在SQL脚本组件中执行PAI命令。
PAI
-name fe_meta_runner
-project algo_public
-DinputTable="pai_dense_10_10"
-DoutputTable="pai_temp_2263_20384_1"
-DmapTable="pai_temp_2263_20384_2"
-DselectedCols="pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed,age,campaign,poutcome"
-DlabelCol="y"
-DcategoryCols="previous"
-Dlifecycle="28"-DmaxBins="5" ;参数名称 | 是否必选 | 默认值 | 描述 |
inputTable | 是 | 无 | 输入表的名称。 |
inputTablePartitions | 否 | 无 | 输入表中,参与训练的分区。系统支持以下格式:
说明 指定多个分区时,分区之间使用英文逗号(,)分隔,例如name1=value1,value2。 |
outputTable | 是 | 无 | 输出表名称。 |
mapTable | 是 | 无 | 输出映射表,数据视图对String类字符串会做一个统计,映射成数字(转换成Int方便机器学习识别和训练) |
selectedCols | 是 | 无 | 输入表选择列名类型。 |
labelCol | 否 | 无 | 标签列。 |
categoryCols | 否 | 无 | 把Int或者Double字段当做枚举特征。 |
maxBins | 否 | 100 | 连续性特征等距离划分最大区间数。 |
isSparse | 否 | false | 输入数据是否为稀疏格式,取值范围为{true,false}。 |
itemSpliter | 否 | 英文逗号(,) | 当输入表数据为稀疏格式时,KV对之间的分隔符。 |
kvSpliter | 否 | 英文冒号(:) | 当输入表数据为稀疏格式时,key和value之间的分隔符。 |
lifecycle | 否 | 28 | 表的生命周期。 |
coreNum | 否 | 系统自动分配 | 计算的核心数,取值范围为正整数。取值范围[1, 9999]。 |
memSizePerCore | 否 | 系统自动分配 | 每个核心的内存,取值范围为1 MB~65536 MB。 |
示例
生成如下测试数据。
age
workclass
fwlght
edu
edu_num
married
c
family
race
sex
gail
loss
work_year
country
income
39
State-gov
77516
Bachelors
13
Never-married
Adm-clerical
Not-in-family
White
Male
2174.0
0.0
40.0
United-States
<=50K
50
Self-emp-not-inc
83311
Bachelors
13
Married-civ-spouse
Exec-managerial
Husband
White
Male
0.0
0.0
13.0
United-States
<=50K
38
Private
215646
HS-grad
9
Divorced
Handlers-cleaners
Not-in-family
White
Male
0.0
0.0
40.0
United-States
<=50K
53
Private
234721
11th
7
Married-civ-spouse
Handlers-cleaners
Husband
Black
Male
0.0
0.0
40.0
United-States
<=50K
28
Private
338409
Bachelors
13
Married-civ-spouse
Prof-specialty
Wife
Black
Female
0.0
0.0
40.0
Other
<=50K
37
Private
284582
Masters
14
Married-civ-spouse
Exec-managerial
Wife
White
Female
0.0
0.0
40.0
United-States
<=50K
49
Private
160187
9th
5
Married-spouse-absent
Other-service
Not-in-family
Black
Female
0.0
0.0
16.0
Jamaica
<=50K
52
Self-emp-not-inc
209642
HS-grad
9
Married-civ-spouse
Exec-managerial
Husband
White
Male
0.0
0.0
45.0
United-States
>50K
31
Private
45781
Masters
14
Never-married
Prof-specialty
Not-in-family
White
Female
14084.0
0.0
50.0
United-States
>50K
42
Private
159449
Bachelors
13
Married-civ-spouse
Exec-managerial
Husband
White
Male
5178.0
0.0
40.0
United-States
>50K
添加读数据表、数据视图组件,并进行连线。
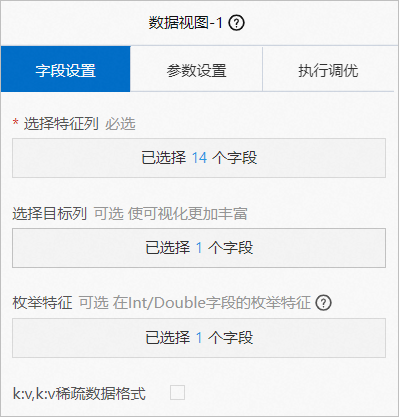
在数据视图的字段设置页签,选择income为目标列,其他14个字段为特征列,其中BIGINT类型的edu_num字段作为枚举值处理。
单击左上角
 ,运行工作流。
,运行工作流。待运行结束,右键单击步骤 2的组件,选择查看数据,查看训练结果:
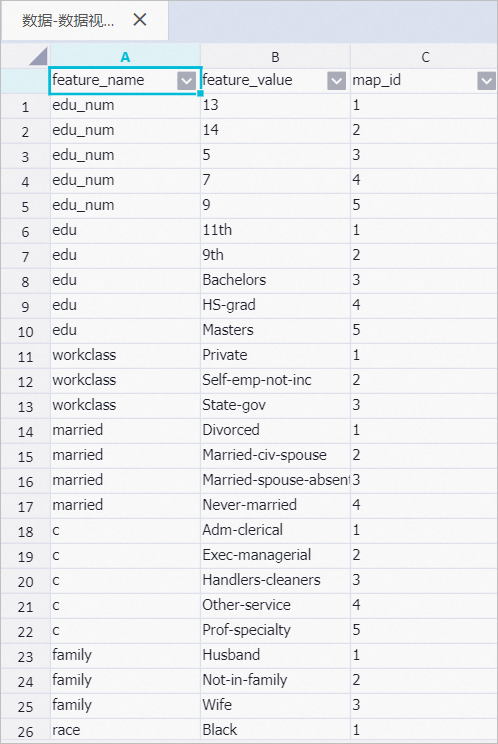
输出:为了方便数据被机器学习算法训练,将STRING字段的family、race、sex及income等映射成数值(某种程度有数据格式转换的功能)。
String字段特征值映射表
说明如果没有选择STRING类型的特征列,则输出结果中String字段特征值映射表内容为空。
输出Meta表
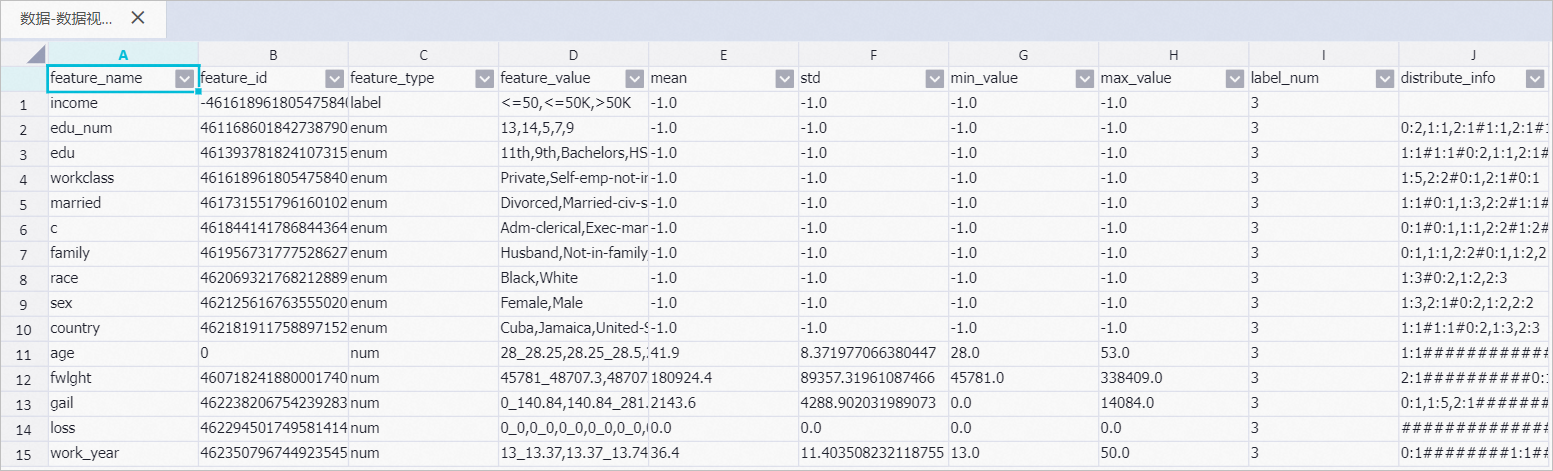 其中:distribute_info表示将最大值和最小值区间等距划分,然后统计每个区间里的数据条数。
其中:distribute_info表示将最大值和最小值区间等距划分,然后统计每个区间里的数据条数。