本文介绍如何在DLC计算资源上提交AutoML实验进行超参数调优。本方案采用PyTorch框架,通过torchvision.datasets.MNIST模块自动下载和加载MNIST手写数字数据集,并对其进行模型训练,以寻找最佳超参数配置。提供单机、分布式及嵌套参数三种训练模式供选择,以满足不同训练需求。
前提条件
首次使用AutoML功能时,需要完成AutoML相关权限授权。具体操作,请参见云产品依赖与授权:AutoML。
已完成DLC相关权限授权,授权方法详情请参见云产品依赖与授权:DLC。
已创建工作空间并关联了通用计算资源公共资源组。具体操作,请参见创建及管理工作空间。
已开通OSS并创建OSS Bucket存储空间,详情请参见控制台快速入门。
步骤一:创建数据集
步骤二:新建实验
进入新建实验页面,并按照以下操作步骤配置关键参数,其他参数配置详情,请参见新建实验。参数配置完成后,单击提交。
设置执行配置。
本方案提供单机训练、分布式训练以及嵌套参数训练三种训练方式,您可以选择其中一种训练方式。
单机训练参数配置说明
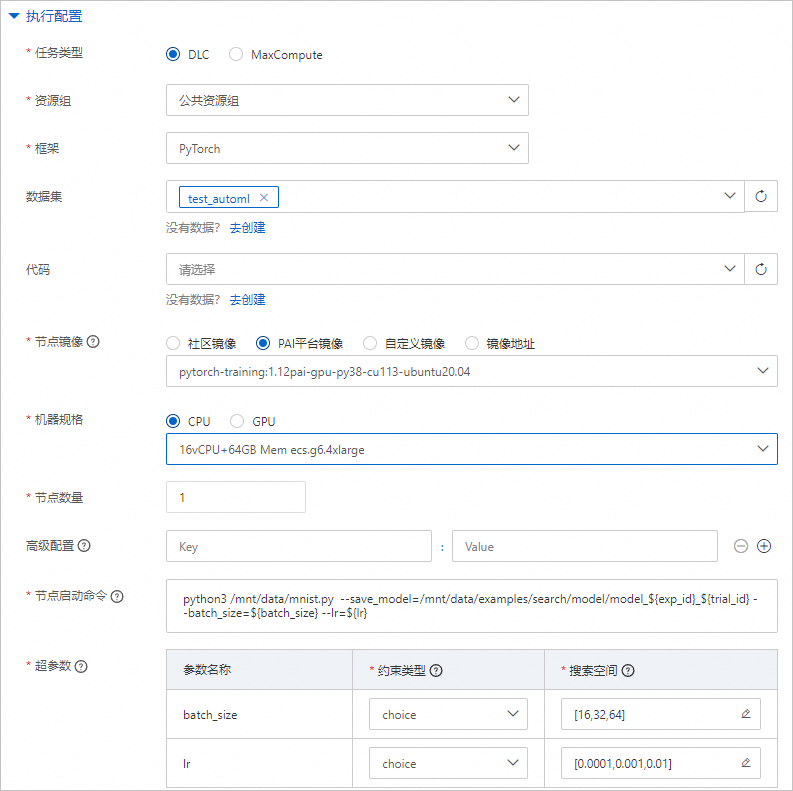
参数
描述
任务类型
选择DLC。
资源组
选择公共资源组。
框架
选择PyTorch。
数据集
选择步骤一中已创建的数据集。
节点镜像
选择PAI平台镜像 >
pytorch-training:1.12PAI-gpu-py38-cu113-ubuntu20.04。机器规格
选择CPU >
ecs.g6.4xlarge。节点数量
设置为1。
启动命令
配置为
python3 /mnt/data/mnist.py --save_model=/mnt/data/examples/search/model/model_${exp_id}_${trial_id} --batch_size=${batch_size} --lr=${lr}。超参数
batch_size
约束类型:选择choice。
搜索空间:单击
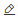 ,增加3个枚举值,分别为16,32和64。
,增加3个枚举值,分别为16,32和64。
lr
约束类型:选择choice。
搜索空间:单击
,增加3个枚举值,分别为0.0001、0.001和0.01。
使用上述配置可以生成9种超参数组合,后续实验会分别为每种超参数组合创建一个Trial,在每个Trial中使用一组超参数组合来运行脚本。
分布式训练参数配置说明
参数
描述
任务类型
选择DLC。
资源组
选择公共资源组。
框架
选择PyTorch。
数据集
选择步骤一中已创建的数据集。
节点镜像
选择PAI平台镜像 >
pytorch-training:1.12PAI-gpu-py38-cu113-ubuntu20.04。机器规格
选择CPU >
ecs.g6.4xlarge。节点数量
设置为3。
启动命令
配置为
python -m torch.distributed.launch --master_addr=$MASTER_ADDR --master_port=$MASTER_PORT --nproc_per_node=1 --nnodes=$WORLD_SIZE --node_rank=$RANK /mnt/data/mnist.py --data_dir=/mnt/data/examples/search/data --save_model=/mnt/data/examples/search/pai/model/model_${exp_id}_${trial_id} --batch_size=${batch_size} --lr=${lr}。超参数
batch_size
约束类型:选择choice。
搜索空间:单击
,增加3个枚举值,分别为16、32和64。
lr
约束类型:选择choice。
搜索空间:单击
,增加3个枚举值,分别为0.0001、0.001和0.01。
使用上述配置可以生成9种超参数组合,后续实验会分别为每种超参数组合创建一个Trial,在每个Trial中使用一组超参数组合来运行脚本。
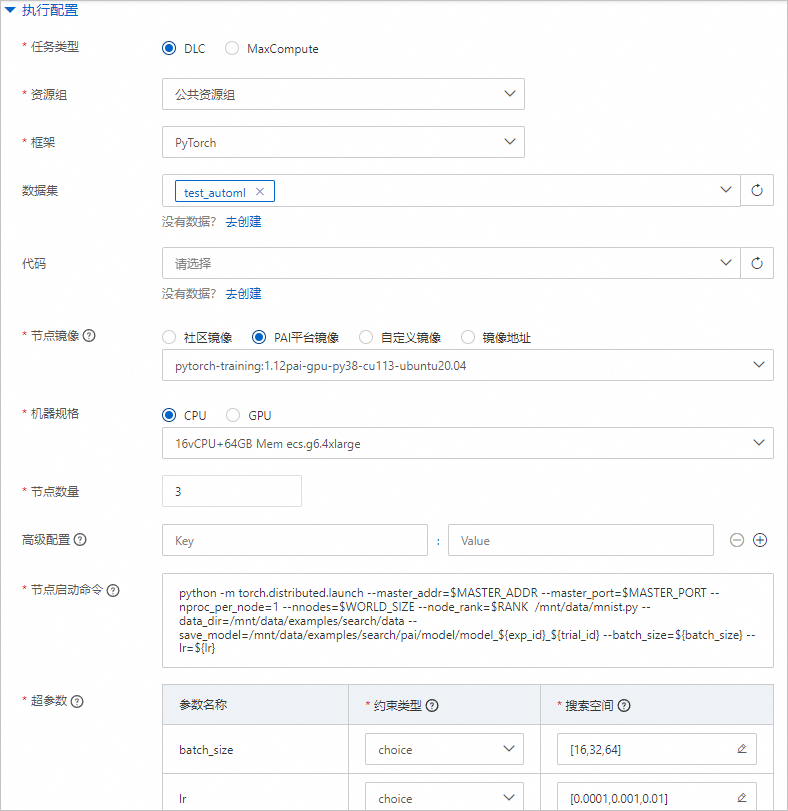
嵌套参数训练参数配置说明
参数
描述
任务类型
选择DLC。
资源组
选择公共资源组。
框架
选择PyTorch。
数据集
选择步骤一中已创建的数据集。
节点镜像
选择PAI平台镜像 >
pytorch-training:1.12PAI-gpu-py38-cu113-ubuntu20.04。机器规格
选择CPU >
ecs.g6.4xlarge。节点数量
设置为1。
启动命令
配置为
python3 /mnt/data/mnist.py --save_model=/mnt/data/examples/search/pai/model/model_${exp_id}_${trial_id} --batch_size=${nested_params}.{batch_size} --lr=${nested_params}.{lr} --gamma=${gamma}。超参数
nested_params
约束类型:选择choice。
搜索空间:单击
,增加2个枚举值,分别为{"_name":"large","{lr}":{"_type":"choice","_value":[0.02,0.2]},"{batch_size}":{"_type":"choice","_value":[256,128]}}和{"_name":"small","{lr}":{"_type":"choice","_value":[0.01,0.1]},"{batch_size}":{"_type":"choice","_value":[64,32]}}。
gamma
约束类型:选择choice。
搜索空间:单击
,增加3个枚举值,分别为0.8、0.7和0.9。
使用上述配置可以生成9种超参数组合,后续实验会分别为每种超参数组合创建一个Trial,在每个Trial中使用一组超参数组合来运行脚本。
设置Trial配置。
参数
描述
优化指标
指标类型
选择stdout。表示最终指标从运行过程中的stdout中提取。
计算方式
选择best。
指标权重
配置如下:
key:validation: accuracy=([0-9\\.]+)。
Value:1。
指标来源
命令关键字配置为cmd1。
优化方向
选择越大越好。
模型存储路径
设置为保存模型的OSS路径。本方案配置为
oss://examplebucket/examples/model/model_${exp_id}_${trial_id}。设置搜索配置。
参数
描述
搜索算法
选择TPE。算法详情说明,请参见支持的搜索算法。
最大搜索次数
配置为3。表示该实验允许运行的最多Trial个数为3个。
最大并发量
配置为2。表示该实验允许并行运行的最多Trial个数为2个。
开启earlystop
打开开关。如果一个Trial在评估一组特定的超参数组合时发现效果明显很差,则会提前终止该Trial的评估过程。
start step
配置为5。表示该Trial在最早执行完5次评估后,可以决定是否提前停止。
步骤三:查看实验详情和运行结果
在实验列表中,单击目标实验名称,进入实验详情页面。
在该页面,您可以查看Trial的执行进度和状态统计。实验根据配置的搜索算法和最大搜索次数自动创建3个Trial。
单击Trial列表,您可以在该页面查看该实验自动生成的所有Trial列表,以及每个Trial的执行状态、最终指标和超参数组合。
相关文档
您也可以提交MaxCompute计算资源的超参数调优实验,详情请参见MaxCompute K均值聚类最佳实践。
关于AutoML更详细的使用方法和原理介绍,请参见自动机器学习(AutoML)。