本文将介绍在创建表时选择对象存储OSS+API为数据源的操作步骤。
添加步骤可分为以下两步:
开通OSS服务
OSS+API数据源的添加
步骤一:开通OSS服务
1. 开通服务
开通OSS服务,需要和已购买的OpenSearch服务是同一账号、相同地域。
OSS服务需要和已购买的OpenSearch服务是同一账号、相同地域,否则会出现鉴权失败的情况。
2. 创建Bucket
在上传文件到OSS之前,您需要创建一个用于存储文件的存储空间Bucket,可以参考创建存储空间了解。
路径:对象存储OSS 管理控制台 → Bucket列表 → 创建 Bucket
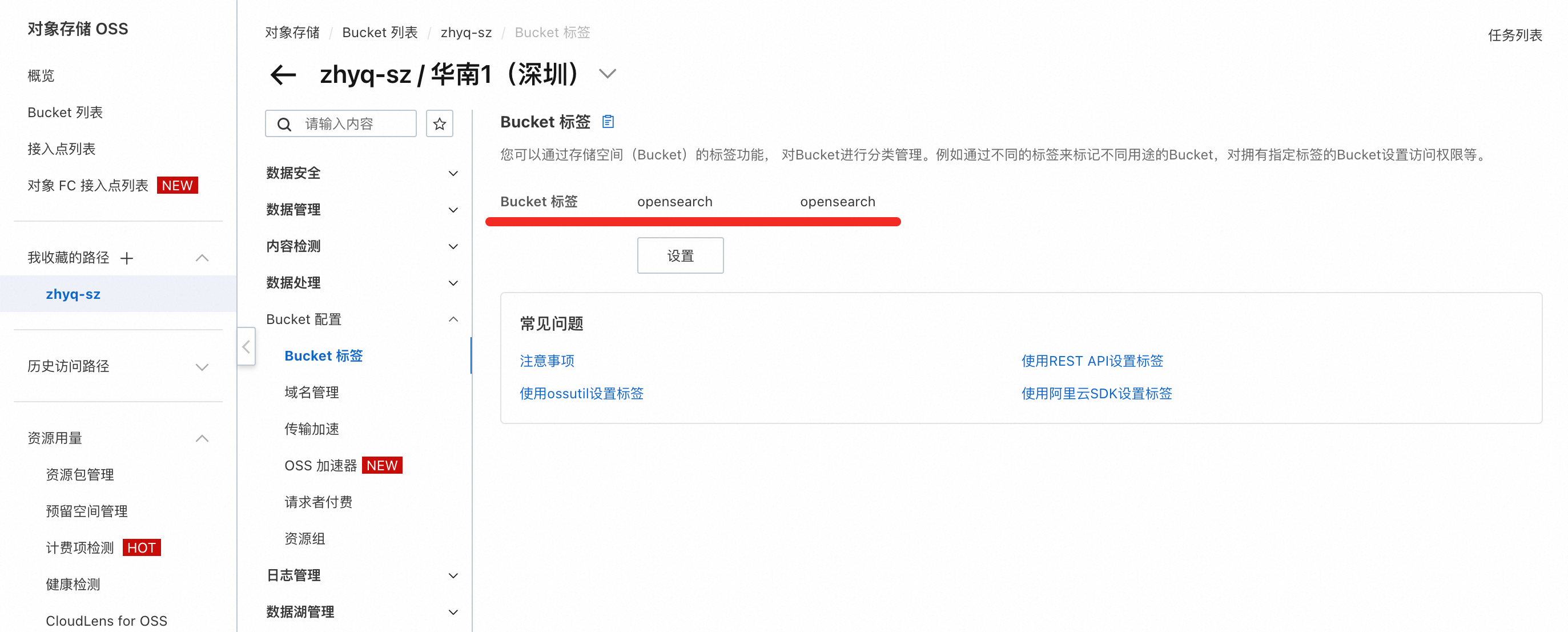
进入已创建的Bucket内,添加OpenSearch标签。
路径:Bucket配置 → Bucket 标签 → 创建标签
3. OSS文件格式设置
a. OSS文件格式
为了使传输的文件能够被用于索引构建的数据源,请确保:
文件采用UTF-8编码。
文件数据格式转化为HA3格式或JSON格式。
ⅰ. JSON格式设置
文件里面每行一个JSON数据。
'\n'表示换行符,单条记录、一个JSON内部不能有换行符。
配置的目录下面不能放其他文件。
JSON字段的类型都是String,引擎建索引的时候,会根据schema转换为字段指定的类型。
多条记录示例,参考以下示例:
{"field_double": ["100.0", "221.123", "500.3333333"], "field_int32": ["100", "200", "300"], "title": "华为 Mate 9 麒麟960芯片 徕卡双镜头", "color": "红", "empty_int32": "", "price": "3599", "CMD": "add", "nid": "1", "gather_cn_str": "", "desc": ["str1", "str2", "str3"], "brand": "Huawei", "size": "5.9","__subdocs__":[{"sub_pk":"100","sub_field1":"200","sub_field2":["100","200","300"]},{"sub_pk":"200","sub_field1":"200","sub_field2":["100","200","300"]}]}
{"field_double": ["100.0", "221.123", "500.3333333", "100.0", "221.123", "500.3333333"], "field_int32": ["100", "200", "300", "100", "200", "300"], "title": "Huawei/华为 P10 Plus全网通手机", "color": "蓝", "empty_int32": "", "price": "4388", "CMD": "add", "nid": "2", "gather_cn_str": "color蓝", "desc": ["str1", "str2", "str3", "str1", "str2", "str3"], "brand": "Huawei", "size": "5.5","__subdocs__":[{"sub_pk":"100","sub_field1":"200","sub_field2":["100","200","300"]},{"sub_pk":"200","sub_field1":"200","sub_field2":["100","200","300"]}]}ⅱ. HA3格式设置
首先看一个完整的数据文件standard_sample.data的内容。
CMD=add^_
PK=12345321^_
url=http://www.aliyun.com/index.html^_
title=阿里云计算有限公司^_
body=xxxxxx xxx^_
time=3123423421^_
multi_value_field=1234^]324^]342^_
bidwords=mp3^\price=35.8^Ptime=13867236221^]mp4^\price=32.8^Ptime=13867236221^_
^^
CMD=delete^_
PK=12345321^_CMD=add^_
PK=12345321^_
url=http://www.aliyun.com/index.html^_
title=阿里云计算有限公司^_
body=xxxxxx xxx^_
time=3123423421^_
multi_value_field=1234^]324^]342^_
bidwords=mp3^\price=35.8^Ptime=13867236221^]mp4^\price=32.8^Ptime=13867236221^_
^^
CMD=delete^_
PK=12345321^_文件分隔符定义:可以看到上面的数据文件中总共有两个命令,分别是add、delete。每个命令由多行组成,每行都是一个key-value对。 命令与命令之间用'^^\n'分隔,每一对key-value之间以'^_\n'分隔,多值之间以'^]'分隔,以下是文件分隔符介绍。
C++编码 | ASCII 16进制 | 描述 | (emacs/vi)中的显示形态 | emacs中输入方法 | vi中输入方法 |
"\x1F\n" | 1F0A | key value分隔符 | ^_(接换行) | C-q C-7 | C-v C-7 |
"\x1E\n" | 1E0A | 命令分隔符 | ^^(接换行) | C-q C-6 | C-v C-6 |
"\x1D" | 1D | multi value 分隔符 | ^] | C-q C-5 | C-v C-5 |
"\x1C" | 1C | section weight标志符 | ^\ | C-q C-4 | C-v C-4 |
"\x1D" | 1D | section 分隔符 | ^] | C-q C-5 | C-v C-5 |
"\x03" | 03 | sub doc 字段分隔符 | ^C | C-q C-c | C-v C-c |
命令格式定义
Add命令格式:add命令表示往索引中增加新的内容,add命令第一行必须为CMD=add,后面是该文档的field,field顺序可以与schema中fields顺序一致,所有出现的field必须是fields中指定的。
CMD=add^_ PK=12345321^_ url=http://www.aliyun.com/index.html^_ title=阿里云计算有限公司^_ body=xxxxxx xxx^_ time=3123423421^_ multi_value_field=1234^]324^]342^_ bidwords=mp3^\price=35.8^Ptime=13867236221^]mp4^\price=32.8^Ptime=13867236221^_ ^^CMD=add^_ PK=12345321^_ url=http://www.aliyun.com/index.html^_ title=阿里云计算有限公司^_ body=xxxxxx xxx^_ time=3123423421^_ multi_value_field=1234^]324^]342^_ bidwords=mp3^\price=35.8^Ptime=13867236221^]mp4^\price=32.8^Ptime=13867236221^_ ^^Delete命令格式:delete命令表示从索引中删除指定的内容。delete命令第一行必须为CMD=delete,接下来为index schema中定义属性为primary key 的field,以及用于partition hash的field,如果两个field相同,则只需要出现一个field。
CMD=delete^_ PK=12345321^_ ^^CMD=delete^_ PK=12345321^_ ^^
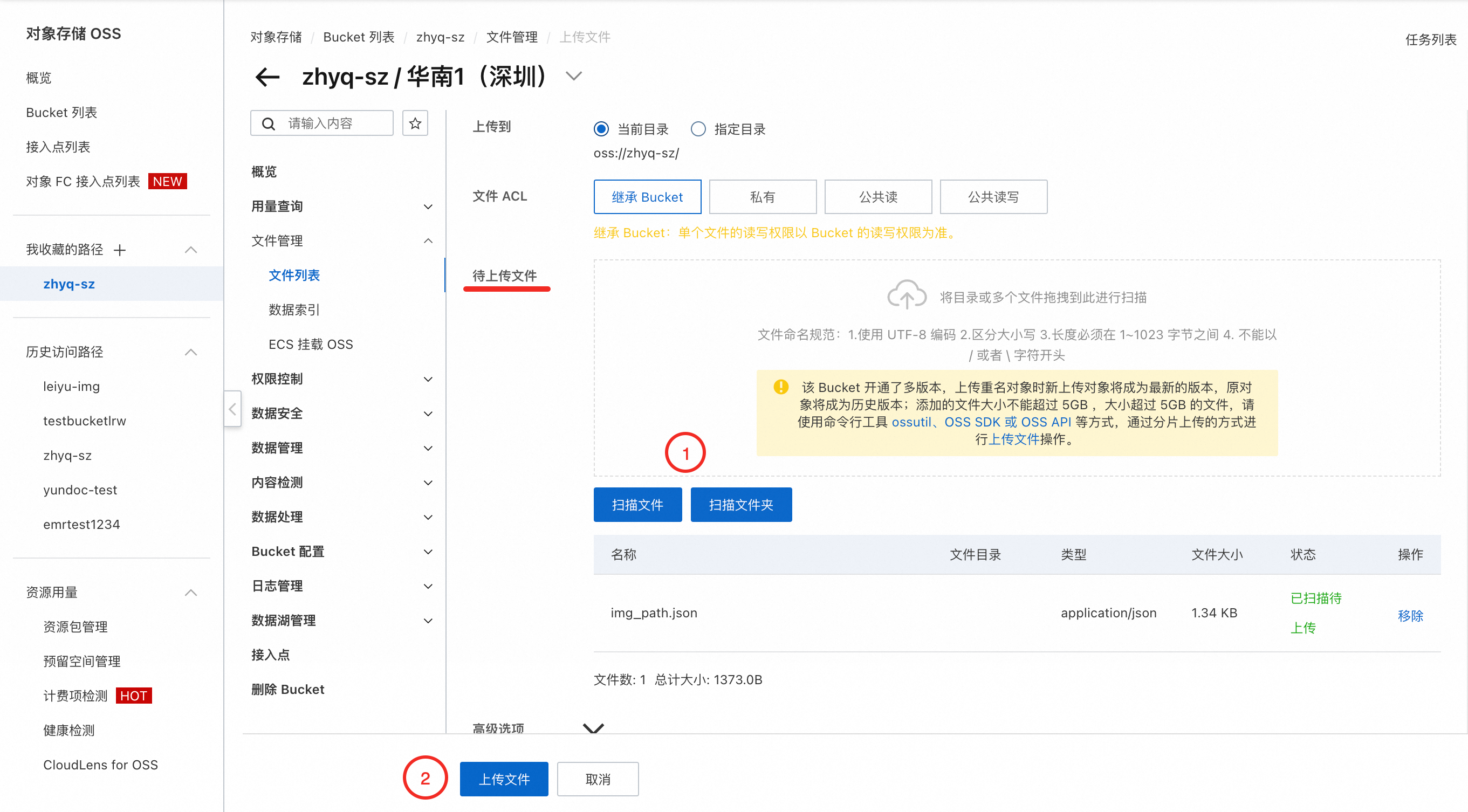
b. 上传文件到Bucket
返回到新创建的Bucket控制页,在左侧导航栏找到文件管理 → 文件列表 → 上传文件 。
在 待上传文件 项中选择扫描文件的方式,勾选好上传的内容,再点击 上传文件 ,完成文件的上传。
步骤二:OSS+API数据源添加
购买实例:可参考购买OpenSearch向量检索版实例。
1. 表基础信息
从 实例列表 中找到已购买的向量检索版实例,在操作栏中点击管理 ,左侧导航栏找到表管理 → 添加表 。
完成表的基础信息填写后,点击 下一步 。
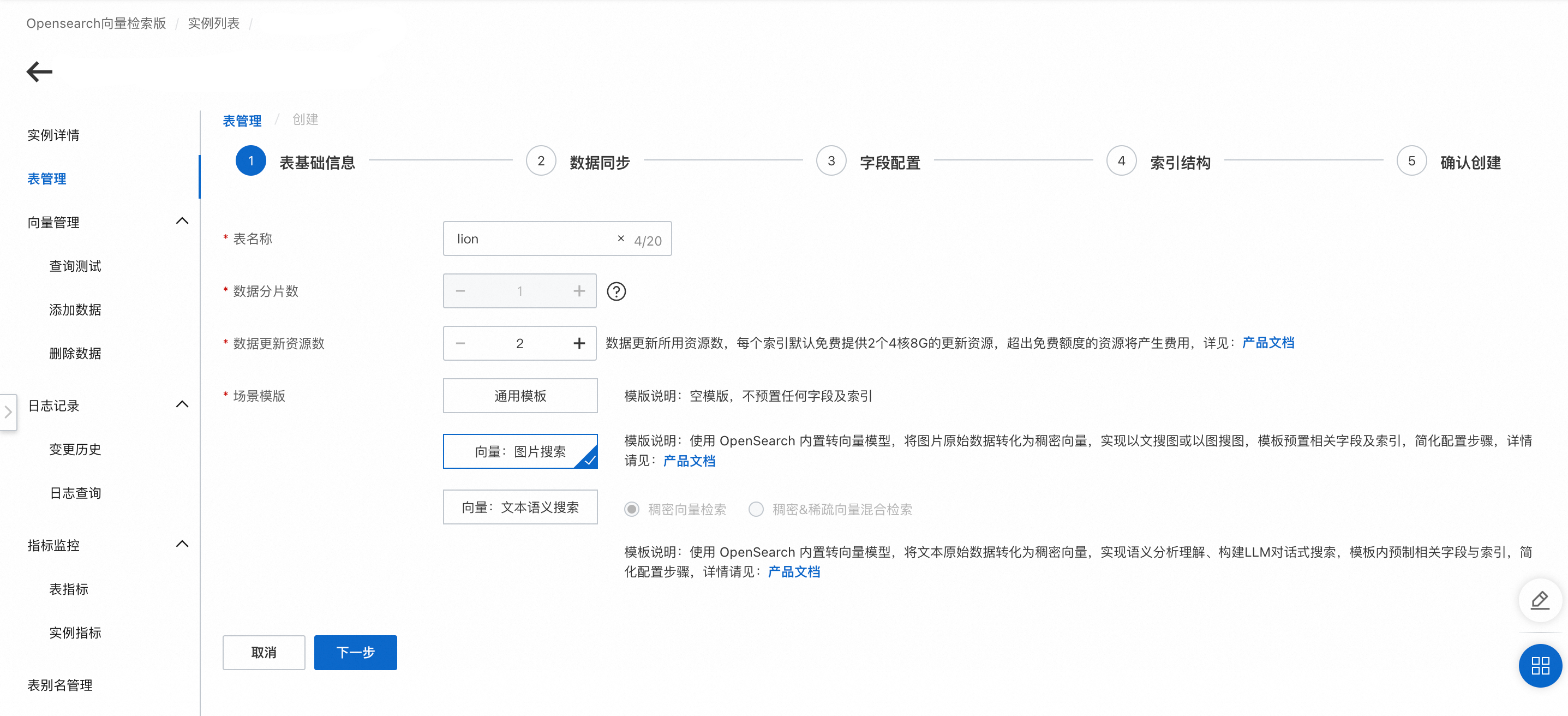
配置说明:
表名称:可以自定义。
数据分片数:请填写不超过256的正整数, 用于提升全量构建速度、单次查询性能。
数据更新资源数:数据更新所用资源数,每个索引默认免费提供2个4核8G的更新资源,超出免费额度的资源将产生费用,详情可参考向量检索版国际站计费文档。
场景模板:共3个模板可供选择,包含1.通用模板、2.向量:图片搜索模板、3.向量:文本语义搜索模板
2. 数据同步
全量数据源 选择「对象存储OSS+API」,并完成其他项的配置,数据来源校验通过后,点击 下一步 。
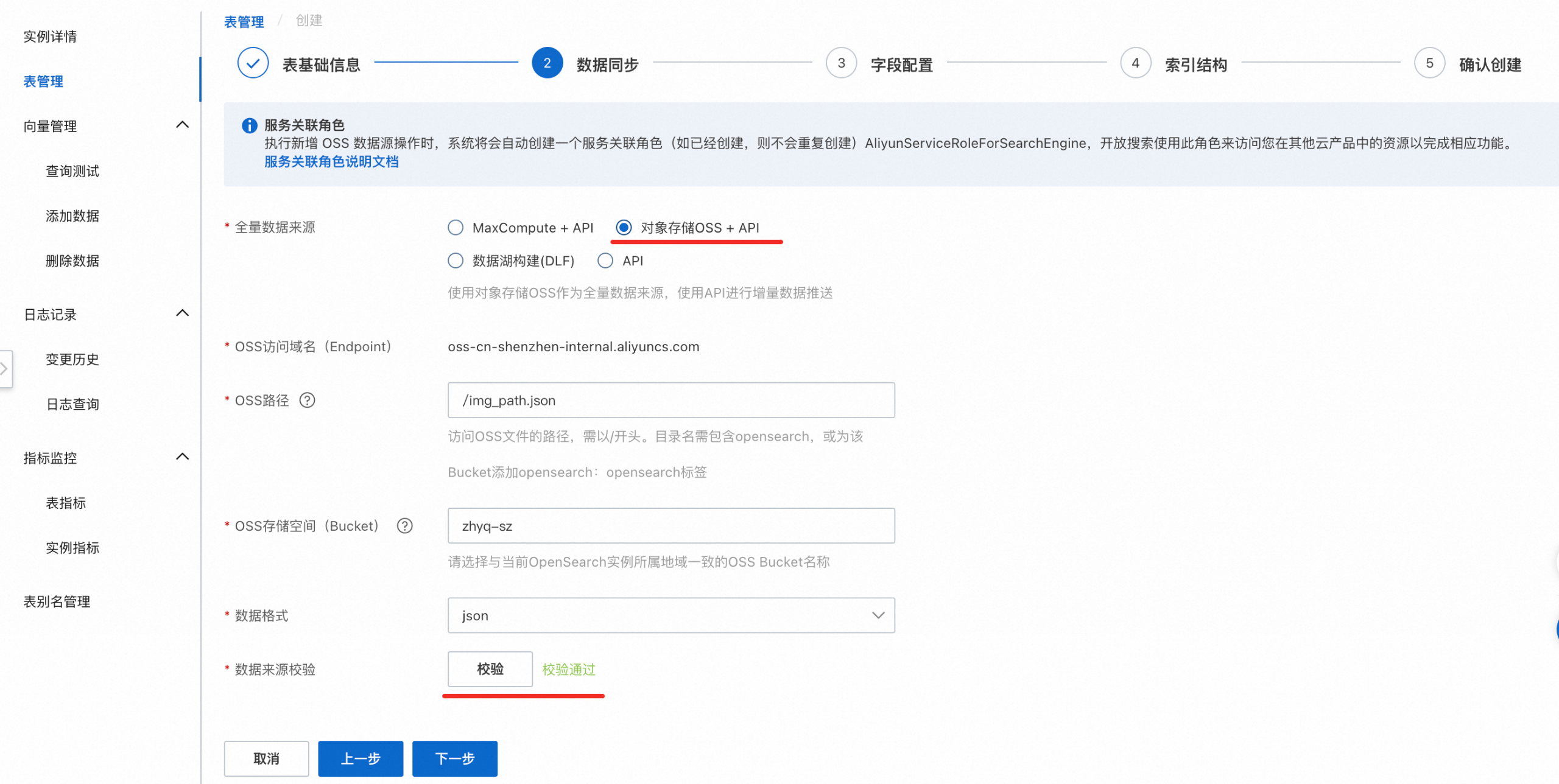
配置说明:
OSS路径:访问OSS文件的路径,需以/开头,路径中不允许包含?、=、&符号,文件不能放在根目录,需放在某个文件夹下然后填写路径。
OSS存储空间(Bucket):OSS的Bucket名称。
数据格式:传输文件需要是HA3或JSON,否则文件数据无法传输成功。
数据来源校验:校验通过后可进行下一步。
3. 字段配置
向量检索版会根据您选择的场景模板,预置相关字段,并会将全量数据来源中的字段,自动导入下方列表,字段配置、需数据预处理-去配置 都设置完成后,点击 下一步 。
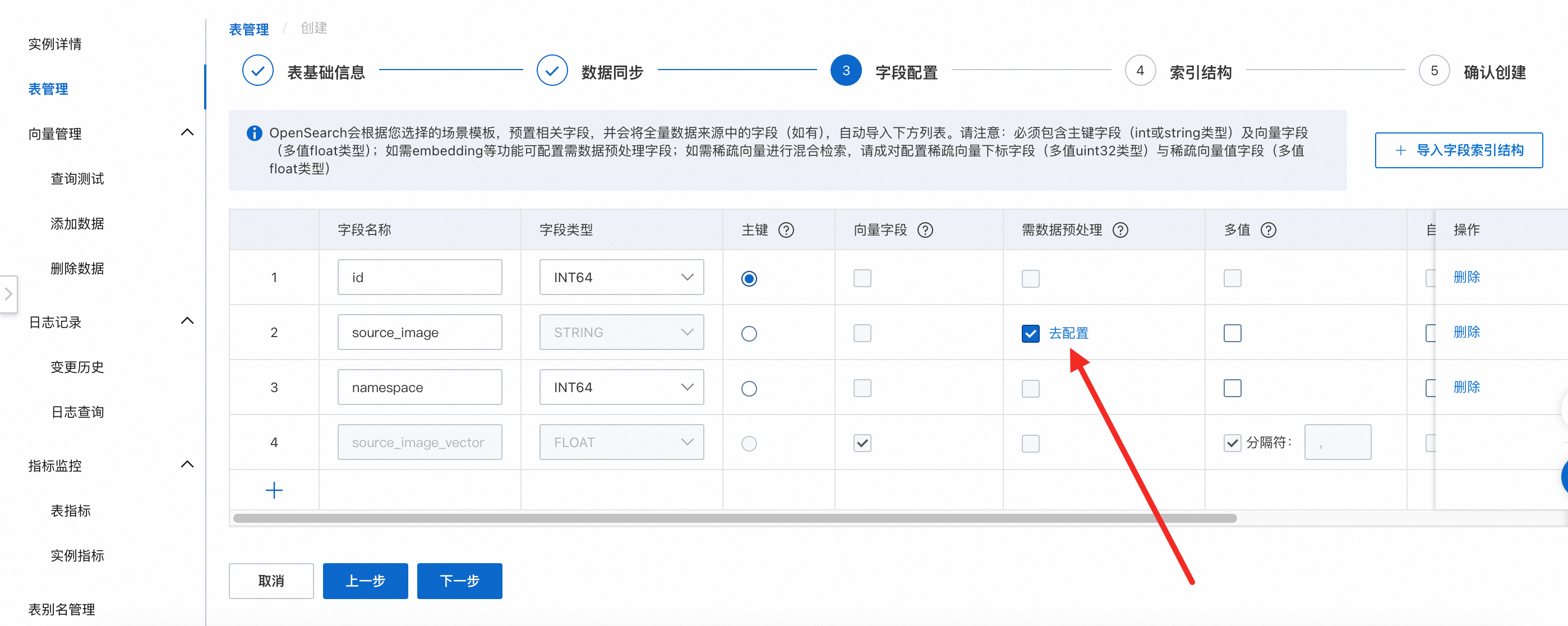
字段含义:
id(主键)
source_image(源图片)
namespace(命名空间)
source_image_vector(源图片向量)
配置说明:
必选字段有:主键字段和向量字段,主键字段为int或string类型并且需要勾选主键按钮,向量字段为float类型并且需要勾选向量字段按钮。
向量字段默认为多值的float类型,多值分隔符默认使用分割符英文逗号进行切分,也可以输入自定义多值分隔符。
当数据中缺少字段或字段为空时,系统将自动补充默认值,数字类型默认补0,STRING类型默认补空字符串,支持自定义默认值。
需数据预处理 - 去配置:点击去配置,进入字段 source_image 数据预处理配置界面。
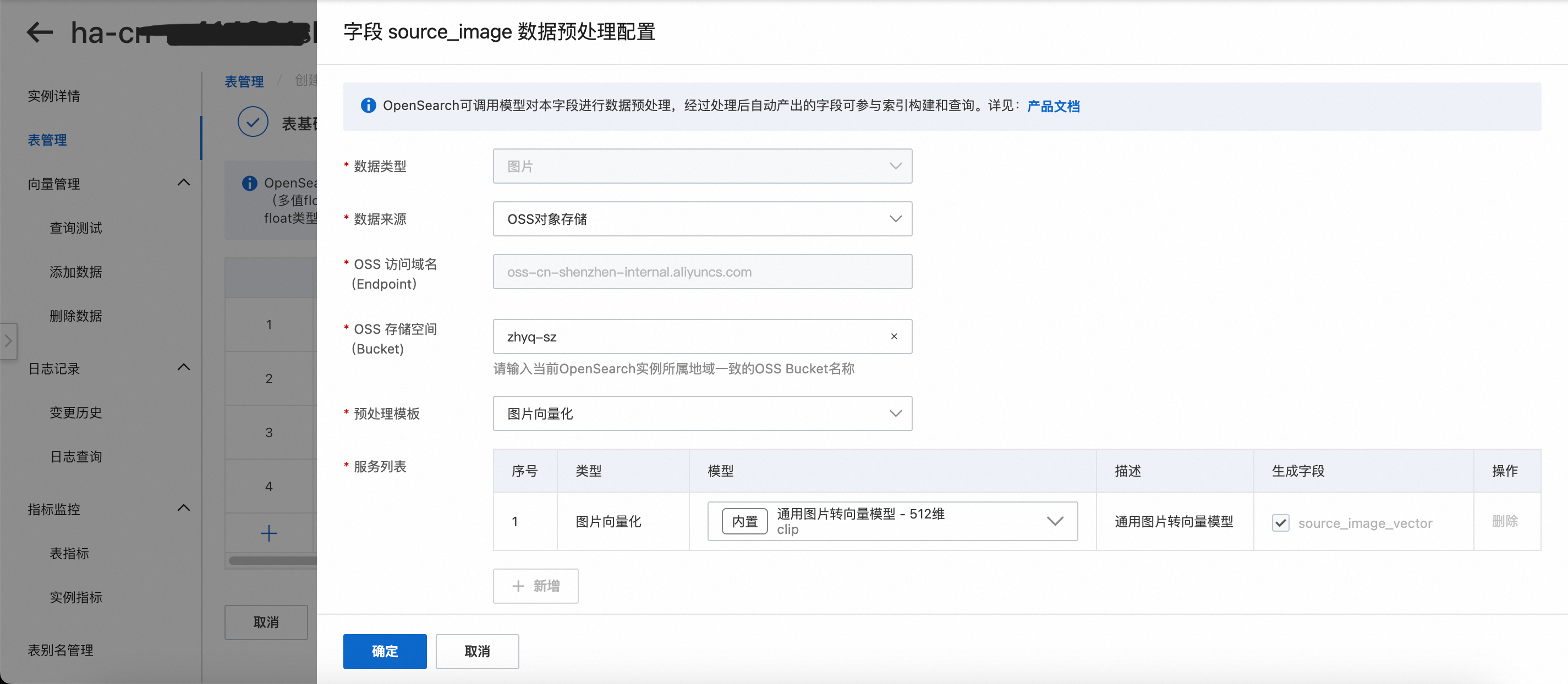
数据来源:有OSS对象存储和Base64编码的两种数据类型选项,本次选择OSS对象存储方式。
OSS对象存储:需要填写OSS路径,其实就是将图片存放在OSS的文件夹里面,从OSS直接导入。
Base64编码:相当于需要先将图片进行一次编码,然后存储在数据库中,或者直接用API方式进行传输。
预处理模板:会根据要进行预处理的数据类型(文本或图片)而展示不同模板,由于本次预处理的是图片类型的数据,所以此时预处理模板展示的分别是(1.图片向量化、2.OCR图片文字识别、3.OCR图片文字识别+图片向量化)3种模板,本次演示选择图片向量化预处理模板。
服务列表:
选定预处理模板后,自动出现模板下的服务列表,展示该模板下所用到的模型种类。
可选的模型来源:
内置模型:模型种类与数量较少,可免费调用。
自定义模型:用户可根据自身需求自定义模型,在向量检索版页面模型列表>自定义模型中进行新增模型操作,详情请参见自定义模型。
4. 索引结构
索引结构配置,配置完成后,点击下一步。
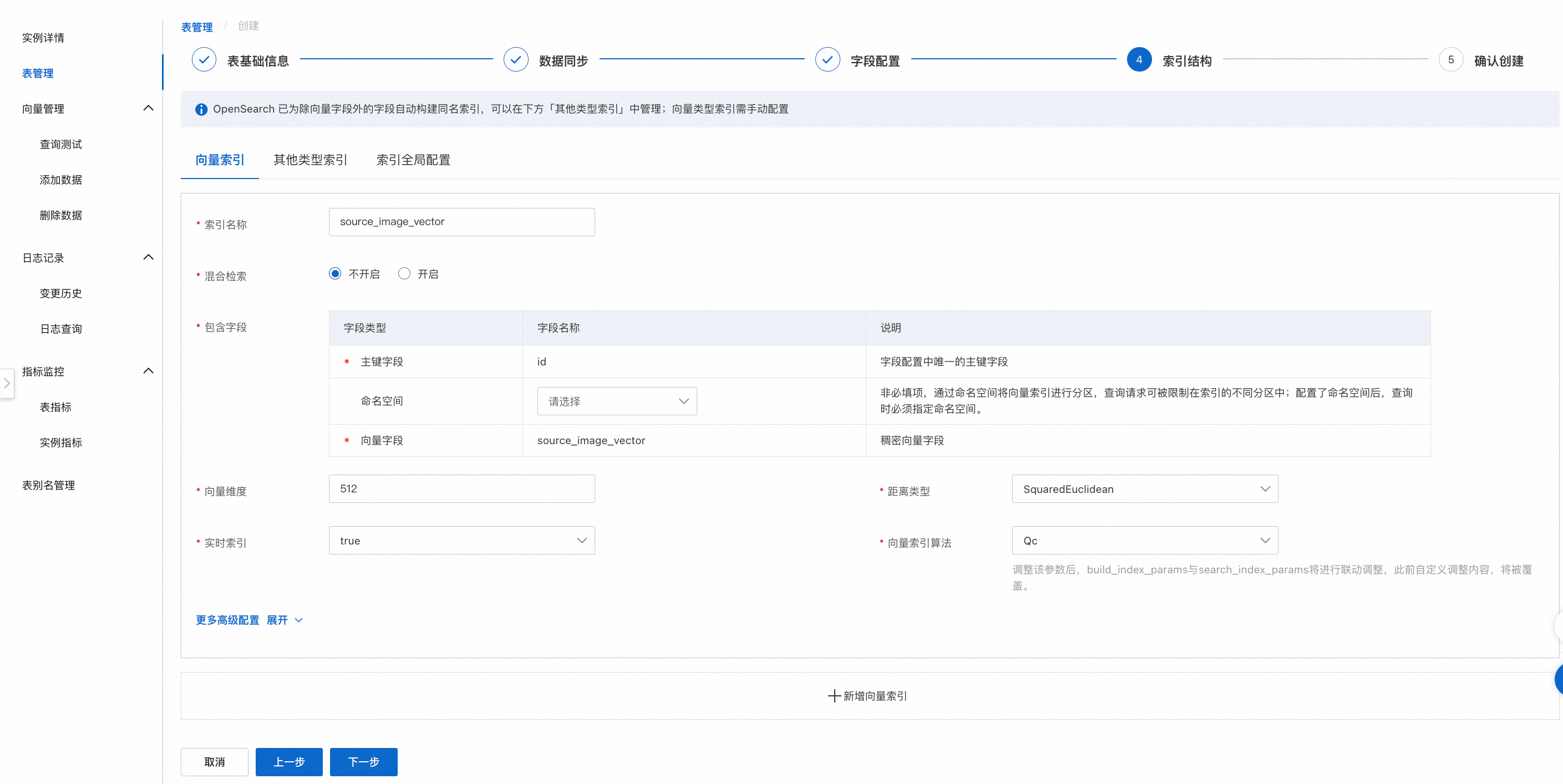
配置说明:
包含字段:主键字段、向量字段必须填写,命名空间字段非必填,可以为空。
向量维度、实时索引、距离类型、向量索引算法可以根据业务情况填写。
更多高级配置:可直接使用默认参数或根据业务情况调整,详情可参考向量索引通用配置,索引结构页设置完毕后,点击下一步,进入确认创建页。
5. 确认创建
点击 确认创建 ,完成后还需等待2分钟,返回到 实例列表 页,待实例状态为“ 正常 ”后,就可以从 操作栏 - 查询测试 进行后续的搜索和测试。