本文将介绍企业在没有向量数据的情况下,如何通过OpenSearch向量检索版,快速搭建图像搜索服务。
用户可以直接导入图片源数据,在OpenSearch内部便捷完成图片向量化、向量搜索等步骤,实现以图搜图、以文搜图等多种图像检索能力。
方案架构
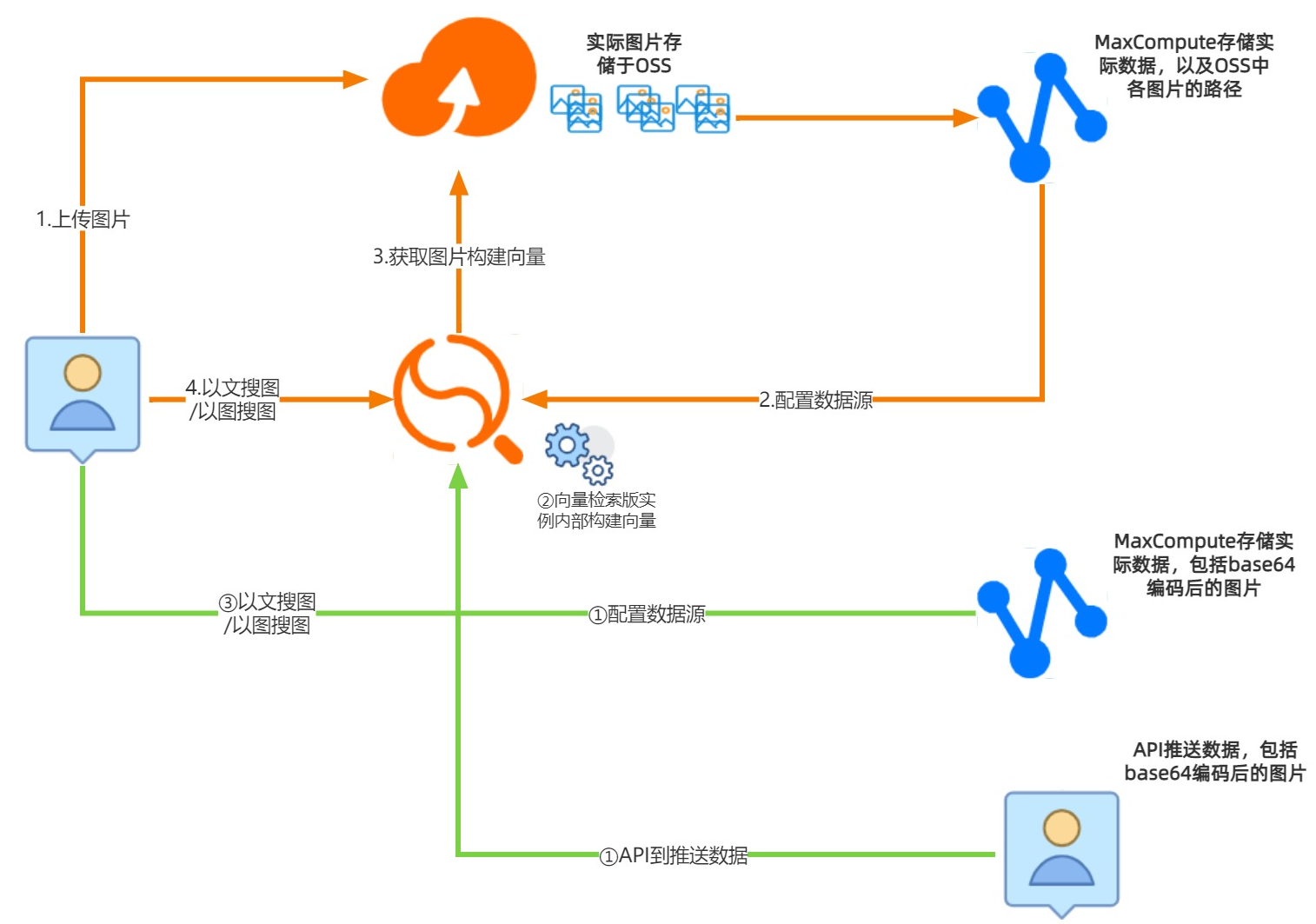
用户可以通过3种不同的方式上传图片进行图搜引擎的搭建:
OSS+MaxCompute+OpenSearch向量检索版:用户先将图片上传至OSS中,在MaxCompute中存储业务表数据以及每条数据对应的图片地址(OSS里的路径,比如/image/1.jpg)
MaxCompute+OpenSearch向量检索版:用户将图片通过base64编码后的图片及其表数据存储在MaxCompute中
API+OpenSearch向量检索版:用户通过OpenSearch向量检索版给出的数据推送接口,将base64编码后的图片及其表数据推送到OpenSearch向量检索版实例中
本文演示的是OSS+MaxCompute+OpenSearch向量检索版搭建图搜引擎。
环境准备
1、创建AK和SK
第一次开通阿里云账号并登录控制台时,会提示先创建access key才能继续使用。
创建及使用应用依赖access key参数,主账号下access key参数不能为空。
在为主账号创建access key参数后,还可以再创建RAM子账号access key通过RAM子账号进行访问,RAM子账号赋予对应访问权限,请参考RAM(子账号)的创建及授权。
2、创建对象存储OSS
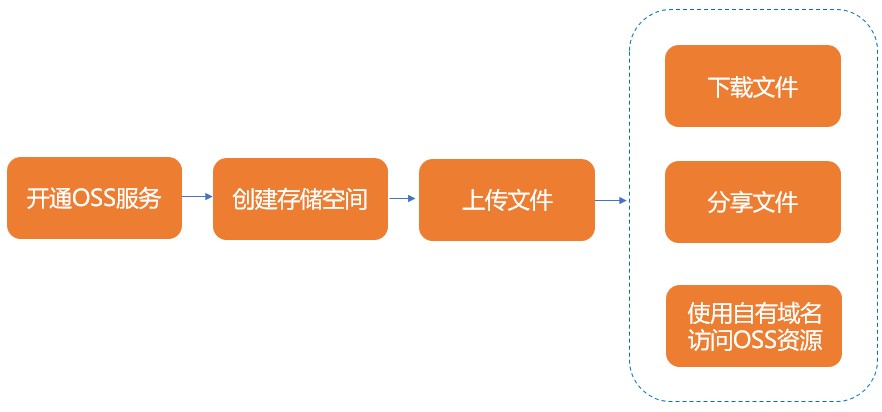
添加opensearch标签:(key-value 值均为opensearch)
本文在OSS中上传了1000张图片:
部分图片类型如下:
购买OpenSearch向量检索版实例
购买实例可参考购买OpenSearch向量检索版实例。
配置实例
新购买的实例,其状态为“待配置”,之后需要为该实例配置一张表,之后才可正常搜索。

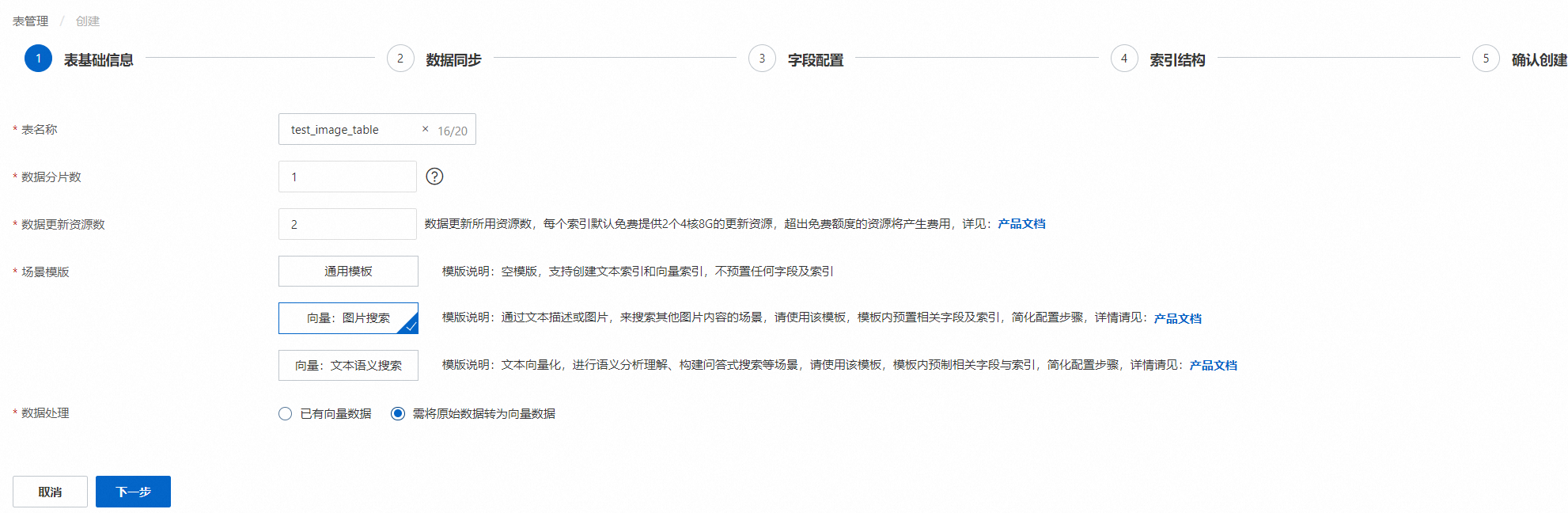
填写表基础信息,点击下一步:
配置说明:
表名称:可自定义
数据分片数:分片数设置时,请填写不超过256的正整数, 用于提升全量构建速度、单次查询性能。(部分存量实例,仍需各索引表分片数保持一致;或至少一个索引表分片数为1,其余索引表分片数一致)
数据更新资源数:数据更新所用资源数,每个索引默认免费提供2个4核8G的更新资源,超出免费额度的资源将产生费用,详情可参考向量检索版国际站计费文档
场景模板:选择“向量:图片搜索”
数据处理:选择“需将原始数据转为向量数据”
数据同步,配置数据源,校验通过后,点击下一步:
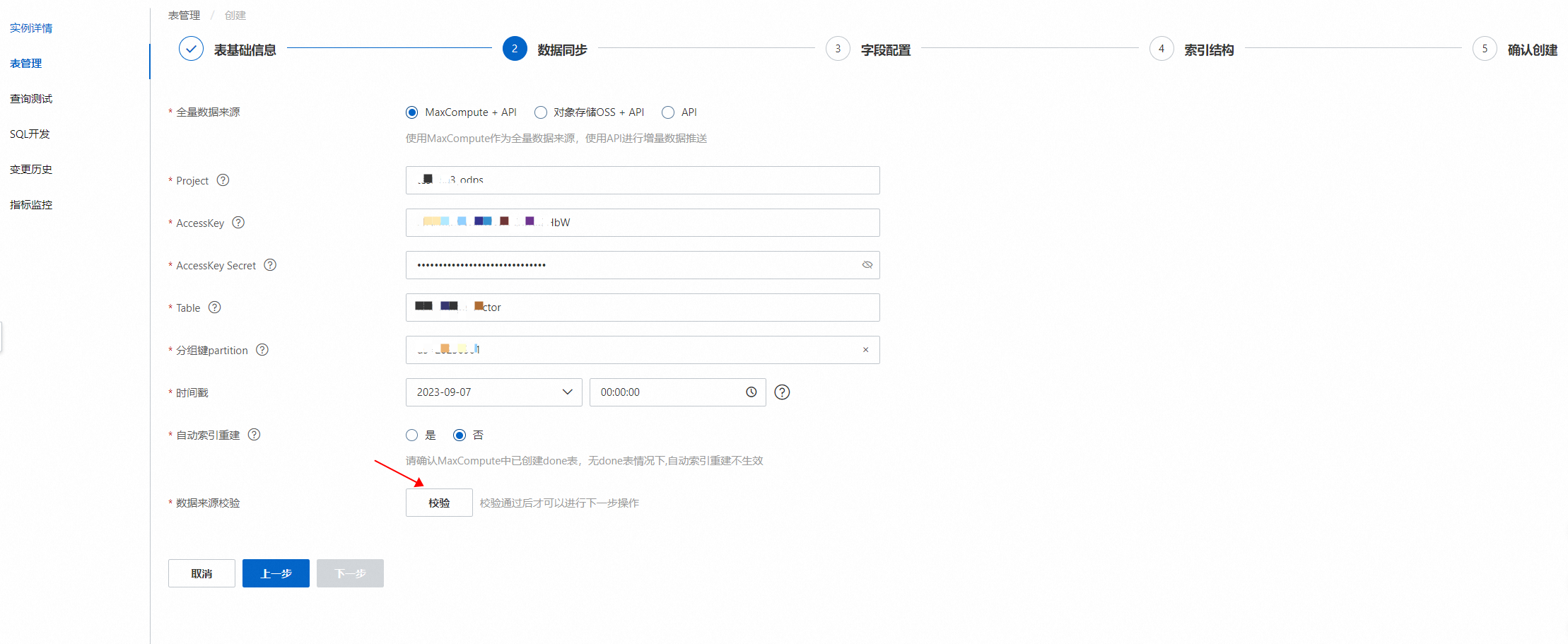
配置参数说明:
数据源类型:选择MaxCompute
Project:访问的目标MaxCompute项目名称
accesskeyId:阿里云账号或RAM用户的AccessKey ID
accesskeySecret:AccessKey ID对应的AccessKey Secret
Table:访问的目标MaxCompute 表名
分组键partition:MaxCompute数据源必须设置分区键; 示例:ds=20170626
时间戳:如果有API的增量数据,该配置表示回追多久的增量数据,系统默认最大能回追3天的API增量数据
自动索引重建:是否开启自动索引重建任务,如果开启,则将在识别到当前数据源的变更时,自动对引用该数据源的索引表进行索引重建;
开启自动索引重建,则必须创建done表,创建方式可参考自动索引重建
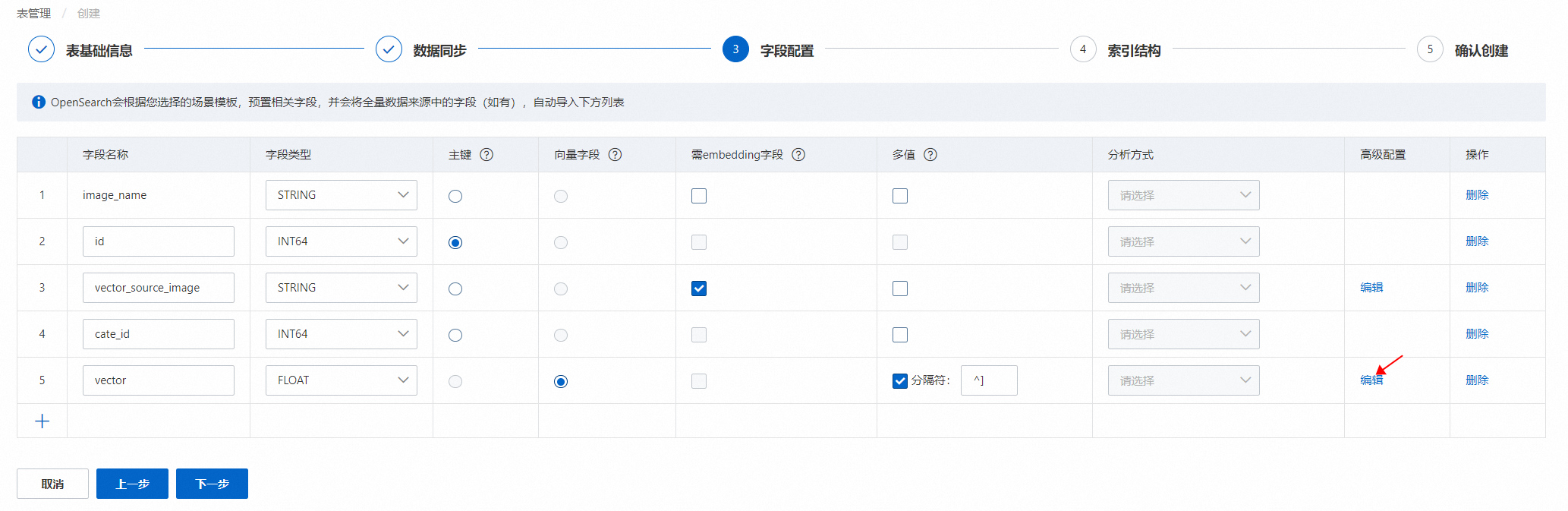
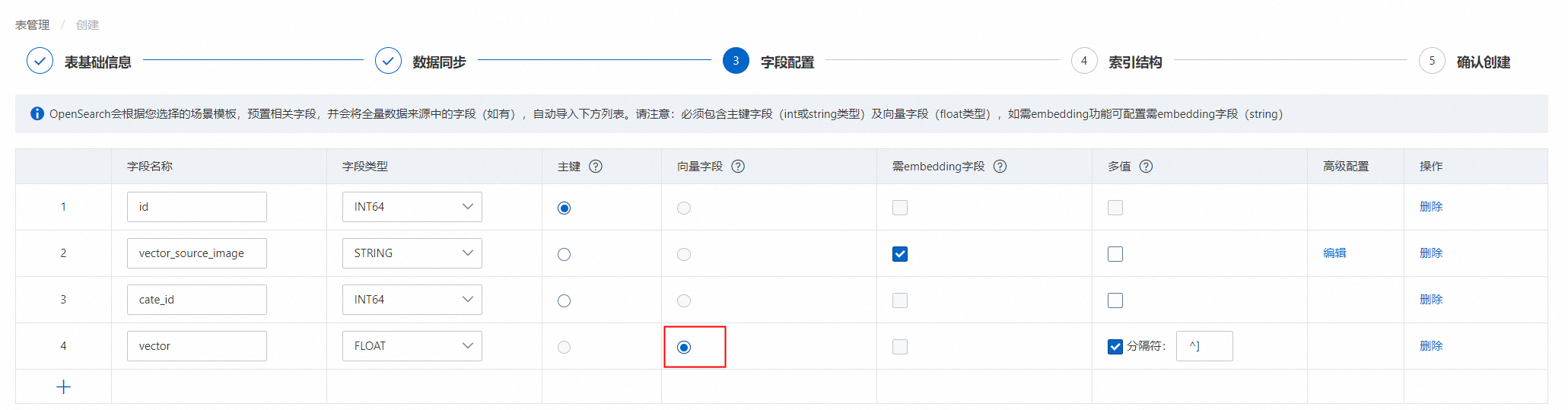
字段配置,配置完成后,点击下一步:
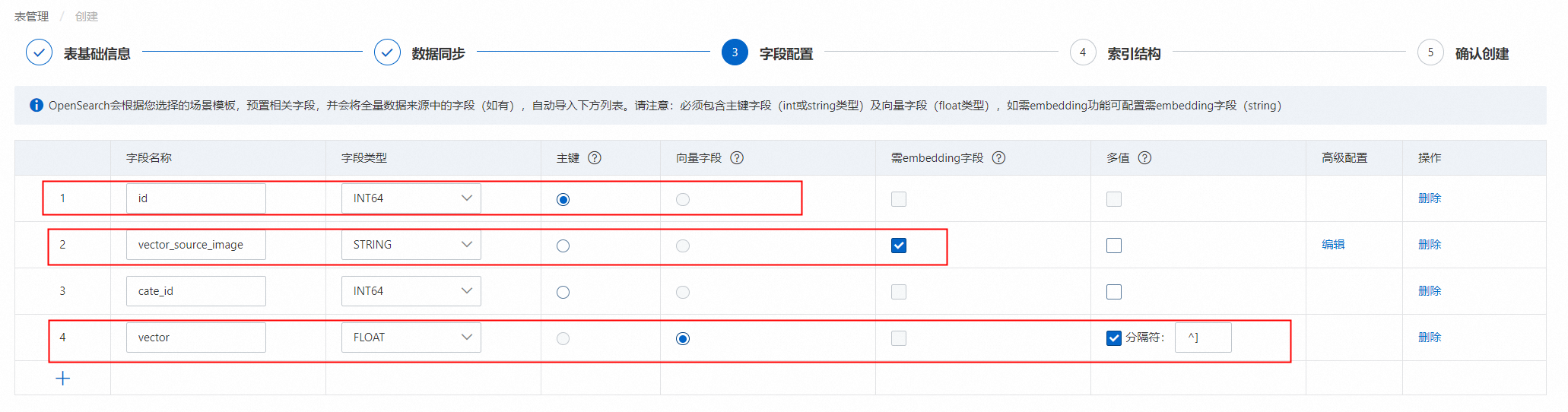
此处需要选择主键、向量字段、需embedding字段。
图片存储于OSS
模板选择“向量:图片搜索”模板后,系统默认生成4个预置字段id(主键)、cate_id(类目字段)、vector(向量字段)、vector_source_image(存储图片路径的字段),用户选择MaxCompute数据源后,从数据源同步的字段,展示在预置字段下方。
3.1.配置“vector_source_image”字段:(字段类型需要为STRING,必须勾选为需embedding字段):
用户可根据业务表字段对预置字段名称进行修改,但需要保证该字段的高级配置无误:

在弹框中填写相应信息:
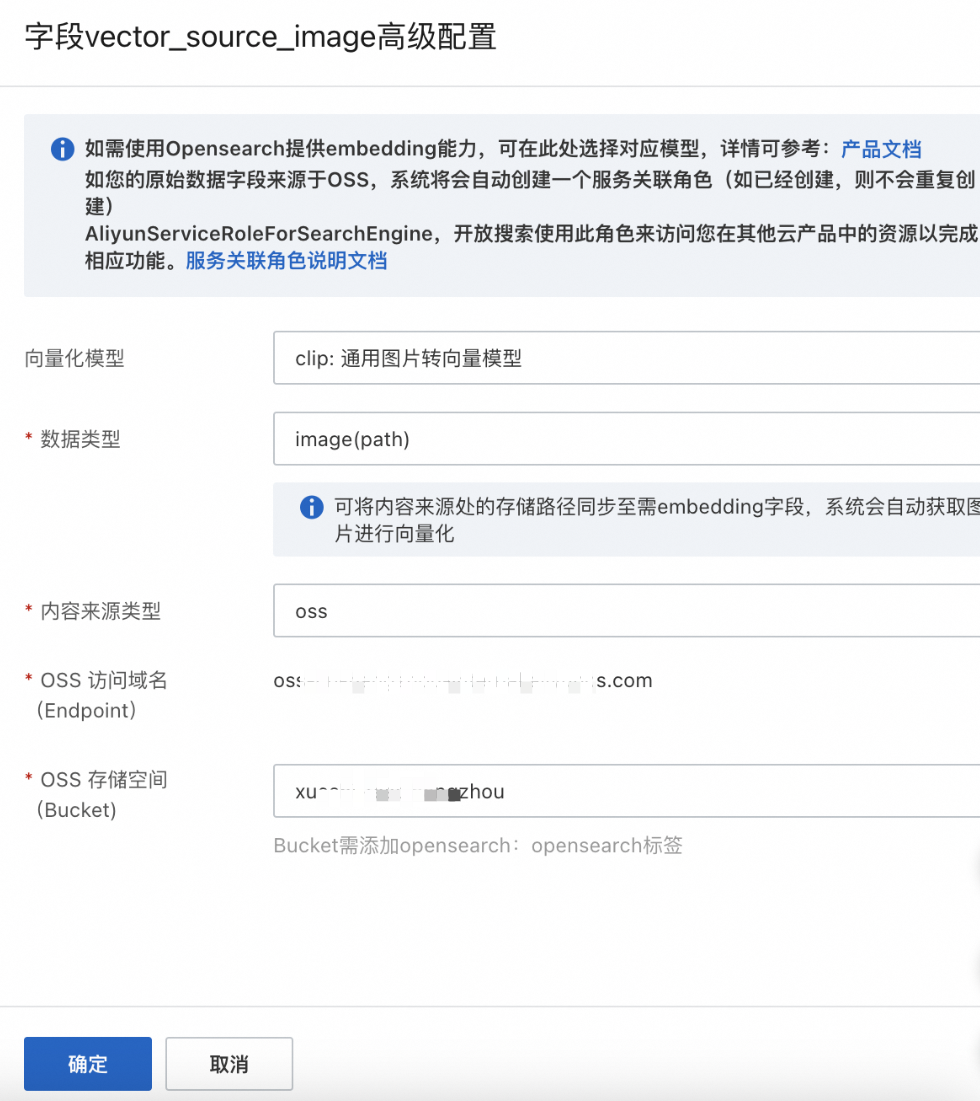
高级配置说明:
向量化模型
clip:通用图片转向量模型。
clip_ecom:电商增强图片转向量模型。
数据类型:选择image
内容来源类型:OSS
OSS存储空间:OSS的bucket名称
注意:OSS的SLR方式需要开通OpenSearch-向量检索版服务关联角色
假设某张图片在OSS的路径为“/测试图片/湖泊.jpg”,那么该字段的内容也必须是“/测试图片/湖泊.jpg”,以下图举例:
OSS的路径:
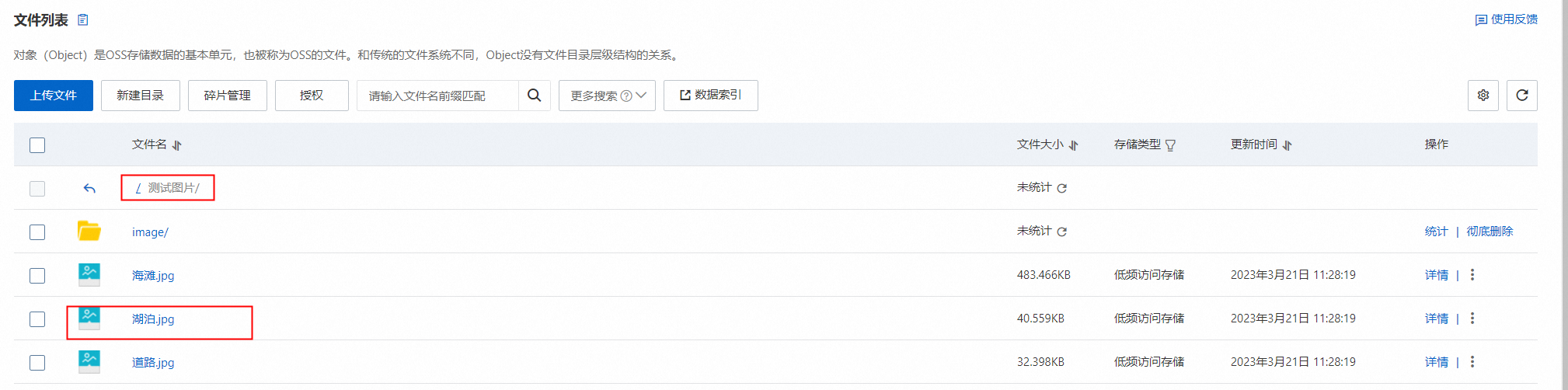
MaxCompute字段值:

3.2.配置vector向量字段:(字段类型需要为FLOAT,必须勾选为向量字段)
base64编码的图片
模板选择“向量:图片搜索”模板后,系统默认生成4个预置字段id(主键)、cate_id(类目字段)、vector(向量字段)、vector_source_image(存储图片路径的字段),用户选择MaxCompute数据源后,从数据源同步的字段,展示在预置字段下方。
3.1.配置“vector_source_image”字段:(字段类型需要为STRING,必须勾选为需embedding字段):
用户可根据业务表字段对预置字段名称进行修改,但需要保证该字段的高级配置无误:
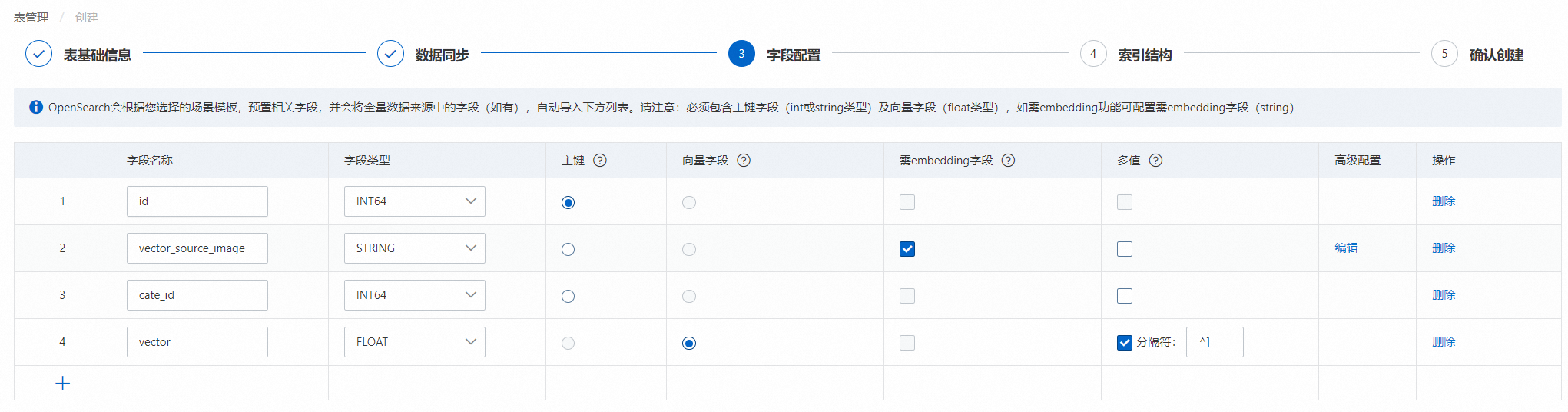
在弹框中填写相应信息:
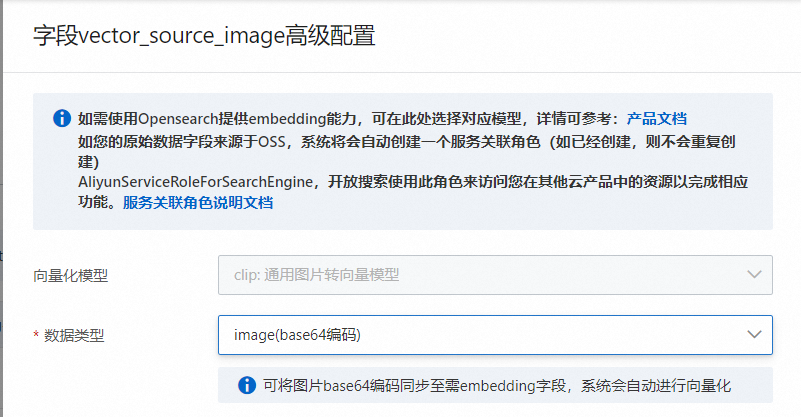
向量化模型:目前支持通用版和电商版两种模型,
clip:通用图片转向量模型。
clip_ecom:电商增强图片转向量模型。
数据类型:选择base64编码。
3.2.勾选vector向量字段:(字段类型需要为FLOAT,必须勾选为向量字段)
索引结构配置,配置完成后点击下一步:
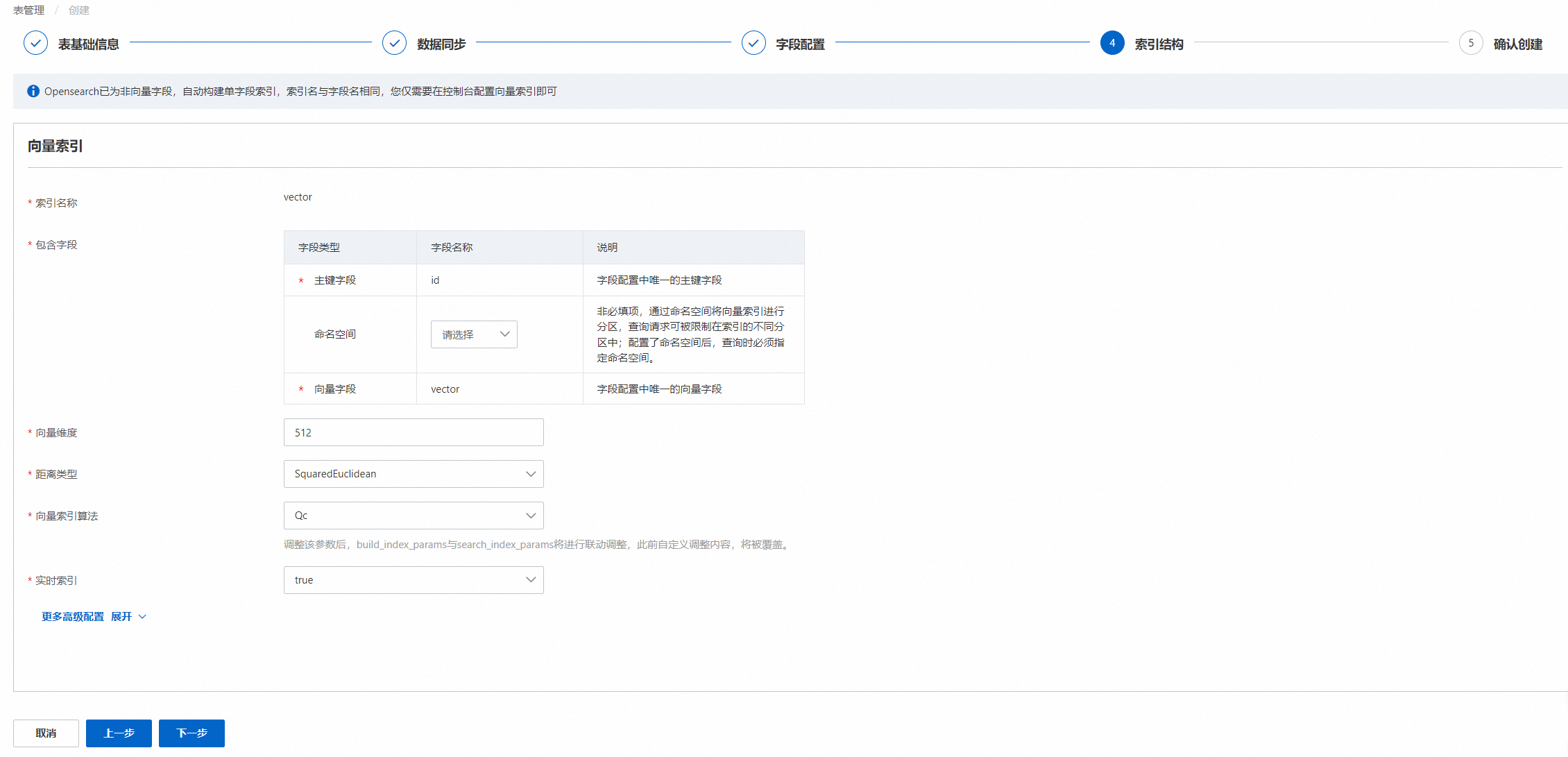
配置说明:
向量索引名称与向量字段名称相同
包含字段为主键、向量字段、命名空间字段可选
高级配置按需填写
通过引擎将图片生成的向量,默认为512维,并且不支持修改。
配置完成后,点击确认创建:
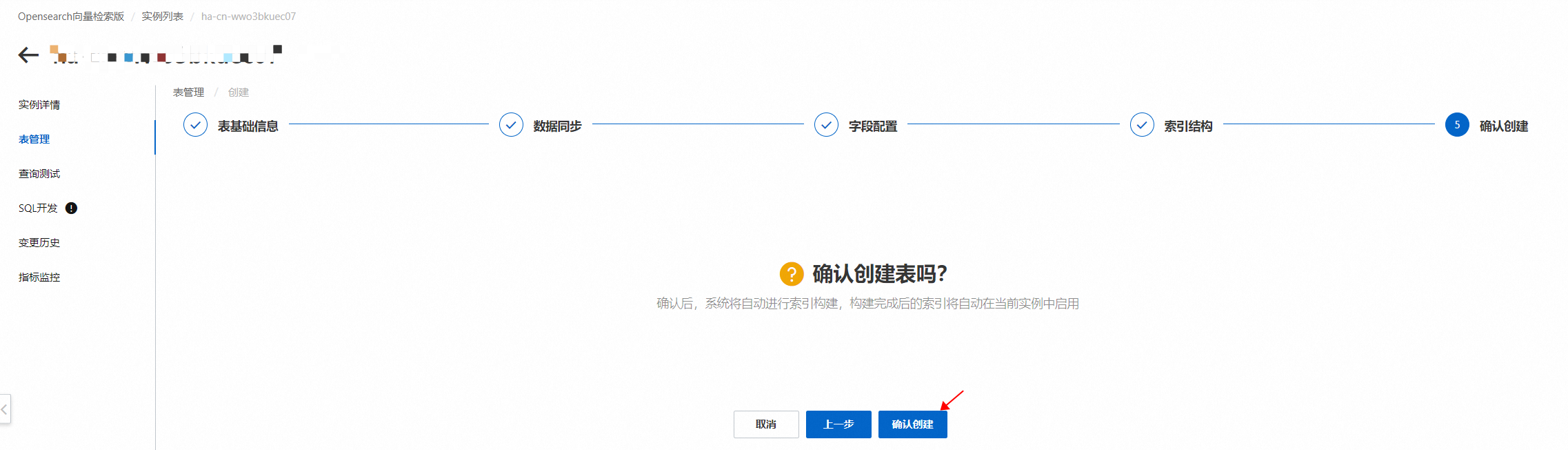
可在变更历史中查看表的创建进度:

全量完成后,即可搜索测试。
查询测试
控制台查询测试
控制台查询用法可以参考:查询测试。
SDK查询
查询示例:可参考预测查询。
结果展示:
{
"totalCount": 5,
"result": [
{
"id": 5,
"score": 1.103209137916565
},
{
"id": 3,
"score": 1.1278988122940064
},
{
"id": 2,
"score": 1.1326735019683838
}
],
"totalTime": 242.615
}result 中 记录着返回的结果。