本文介绍如何查看增加Shard节点或删除Shard节点的任务进度,以及检查是否有异常阻塞任务进程的方法。
背景信息
当您对分片集群实例执行增加Shard节点或删除Shard节点操作后,可能会出现任务提交后很长时间都没完成的情况,以下内容将指导您如何检查上述问题。
在进行操作前,您需要了解以下基本知识:
了解均衡器Balancer的基本工作原理。更多介绍,请参见管理MongoDB均衡器Balancer。
了解MongoDB数据的划分方式,MongoDB的数据是根据Chunk(块)进行划分的。
了解MongoDB分片集群实例中常见的运维命令,例如
sh.status()等。了解mongo shell、mongosh或其他可视化工具的基础使用方式。
检查任务进程
步骤一:检查Balancer是否开启
在增加或删除分片任务中,Chunk的迁移是依赖Balancer完成的。如果未开启Balancer则会导致如下情况:
新增Shard节点:Chunk数据无法迁移到新的Shard节点上,同时也无法承载业务流量。
删除Shard节点:待删除Shard节点上的Chunk数据无法迁移,导致删除Shard节点的任务被阻塞。
因此,您需要开启Balancer来保障Chunk数据的正常迁移。开启Balancer的方法,请参见管理MongoDB均衡器Balancer。
确认Balancer是否开启有如下两种方法:
方法一:
sh.status()命令Balancer已开启的状态下,返回示例如下。
... autosplit: Currently enabled: yes balancer: Currently enabled: yes Currently running: yes Balancer active window is set between 08:30 and 11:30 server local time ...如果显示
“Currently enabled: no”,则表示Balancer未开启。方法二:
sh.getBalancerState()命令如果返回
true,则表示已开启Balancer。如果返回
false,则表示未开启Balancer。
步骤二:检查Balancer窗口期是否过小
Balancer控制了Chunk数据迁移的速度,Balancer仅会在窗口期时间段内迁移Chunk数据,若当前窗口期未迁移完成,会在下个窗口期继续迁移,直至迁移完成。当窗口期过小时,可能会拖慢增加Shard节点或删除Shard节点任务流的整体进度。调整Balancer窗口期的方法,请参见管理MongoDB均衡器Balancer。
您可以通过如下两种方法检查Balancer的窗口期:
方法一:
sh.status()命令返回示例如下,可以了解到Balancer的窗口期为当地时间的08:30至11:30,共计3个小时。
... autosplit: Currently enabled: yes balancer: Currently enabled: yes Currently running: yes Balancer active window is set between 08:30 and 11:30 server local time ...方法二:
sh.getBalancerWindow()命令返回示例如下,当实例中的分片集合较多时,采用此方法能够更直观地显示窗口期时间。
{ "start" : "08:30", "stop" : "11:30" }
步骤三:获取预估任务进度的必要信息
MongoDB 6.0之前版本操作方法
以下内容适用版本如下:
MongoDB 6.0之前版本实例.
内核小版本为7.0.1(基准版本为6.0.3)之前的MongoDB 6.0实例。如何查看内核小版本,请参见MongoDB小版本说明。
评估任务进度前,您需要获取Balancer的运行结果(成功和失败数量的统计)以及待迁移分片表的Chunk信息。
您可以通过如下两种方法获取Balancer的运行结果和待迁移分片表Chunk信息:
方法一:通过
sh.status()命令的输出结果获取sh.status()命令的输出结果仅需要关注两部分信息,第一部分为最近时间Balancer运行的结果,示例如下。... balancer: Collections with active migrations: <db>.<collection> started at Wed Sep 27 2023 10:25:21 GMT+0800 (CST) Failed balancer rounds in last 5 attempts: 0 Migration Results for the last 24 hours: 300 : Success databases: ...第二部分为待迁移的分片表的Chunk信息,示例如下。
... databases: ... { "_id" : "<db>", "primary" : "d-xxxxxxxxxxxxxxx3", "partitioned" : true, "version" : { "uuid" : UUID("3409a337-c370-4425-ad72-8b8c6b0abd52"), "lastMod" : 1 } } <db>.<collection> shard key: { "<shard_key>" : "hashed" } unique: false balancing: true chunks: d-xxxxxxxxxxxxxxx1 13630 d-xxxxxxxxxxxxxxx2 13629 d-xxxxxxxxxxxxxxx3 13652 d-xxxxxxxxxxxxxxx4 13630 d-xxxxxxxxxxxxxxx5 3719 too many chunks to print, use verbose if you want to force print ...以上示例中的“d-xxxxxxxxxxxxxxx5”即为新增的Shard节点。您也可以在分区表所在的库执行
getShardDistribution命令来获取Chunk数据的分布信息,示例如下。use <db> db.<collection>.getShardDistribution()方法二:直接读取config库中的相关信息
查看Chunks统计,按分片聚合,示例如下。
db.getSiblingDB("config").chunks.aggregate([{$group: {_id: "$shard", count: {$sum: 1}}}])查看指定分片上的Chunks,按namespace聚合,示例如下。
db.getSiblingDB("config").chunks.aggregate([{$match: {shard: "d-xxxxxxxxxxxxxx"}},{$group: {_id: "$ns", count: {$sum: 1}}}])查看过去1天内成功迁移到指定Shard节点的Chunk数量,示例如下。
// details.to指定chunk迁移的目标shard // time字段用ISODate指定时间范围 db.getSiblingDB("config").changelog.find({"what" : "moveChunk.commit", "details.to" : "d-xxxxxxxxxxxxx","time" : {"$gte": ISODate("2023-09-26T00:00:00")}}).count()
MongoDB 6.0之后版本操作方法
以下内容适用版本如下:
MongoDB 6.0之后版本实例.
内核小版本为7.0.1(基准版本为6.0.3)及以后的MongoDB 6.0实例。如何查看内核小版本,请参见MongoDB小版本说明。
评估任务进度前,您需要关注各分片上数据量分布情况。您依然可以使用sh.status()的结果作为参考,但是在得到结果后,需要减少对各个分片上Chunks数量不均的关注,转而关注分片上的数据量分布情况。
获取分片表的分布信息以及数据量的均匀情况。
建议您优先通过
getShardDistribution命令获取分片表的分布信息并重点关注数据量的均匀情况。示例如下: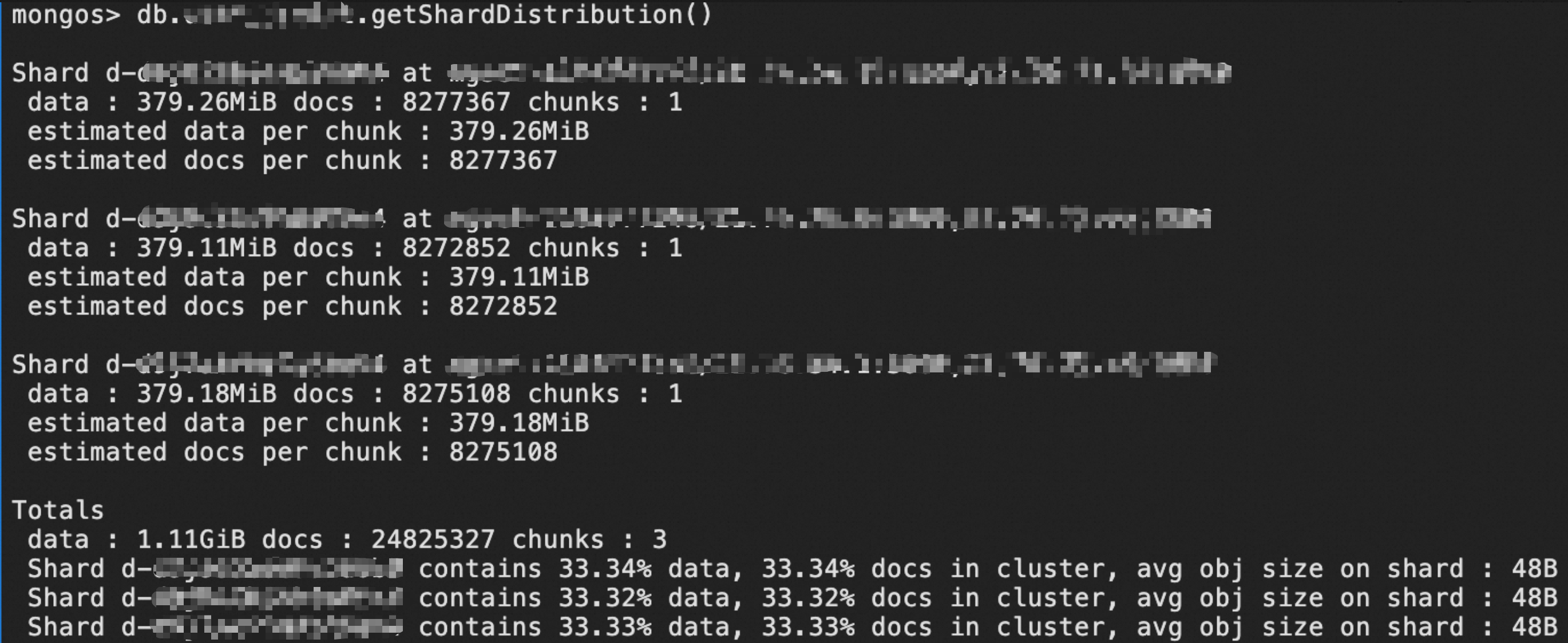
您也可以使用以下的命令获取更加详细的分布信息(包括文档数及总大小,孤立文档数及总大小):
db.getSiblingDB("admin").aggregate( [{ $shardedDataDistribution: { } },{ $match: { "ns": "<db>.<collection>" } }] ).pretty()返回示例如下,您可以看到分片间存在比较明显的数据不均匀的情况。
{ "ns" : "<db>.<collection>", "shards" : [ { "shardName" : "d-xxxxxxxxxxxxxxx1", "numOrphanedDocs" : 0, "numOwnedDocuments" : 504298920, "ownedSizeBytes" : NumberLong("833101815840"), "orphanedSizeBytes" : 0 }, { "shardName" : "d-xxxxxxxxxxxxxxx2", "numOrphanedDocs" : 0, "numOwnedDocuments" : 250283901, "ownedSizeBytes" : NumberLong("409714745937"), "orphanedSizeBytes" : 0 }, { "shardName" : "d-xxxxxxxxxxxxxxx3", "numOrphanedDocs" : 0, "numOwnedDocuments" : 109098088, "ownedSizeBytes" : NumberLong("178157177704"), "orphanedSizeBytes" : 0 }, { "shardName" : "d-xxxxxxxxxxxxxxx4", "numOrphanedDocs" : 0, "numOwnedDocuments" : 382018055, "ownedSizeBytes" : NumberLong("630329790750"), "orphanedSizeBytes" : 0 } ] }通过该返回结果,您可以获取到以下信息:实例中有4个Shard节点,分片表
<db>.<collection>的总数据量约为2051303530231字节(833101815840+409714745937+178157177704+630329790750=2051303530231),折合约为1910.4 GB。查看过去一天内成功迁移的数据量。
查询命令如下:
pipeline = [ { '$match': { 'what': 'moveChunk.commit', } }, { '$group': { '_id': { 'date': { '$dateToString': { 'format': '%Y-%m-%d', 'date': '$time'} }, }, 'chunks_moved': { '$sum': 1 }, 'docs_moved': { '$sum': '$details.counts.cloned' }, 'bytes_moved': { '$sum': '$details.counts.clonedBytes' }, } }, { '$sort': { '_id.date': -1} }, ] db.getSiblingDB("config").changelog.aggregate(pipeline)返回示例如下:

通过该返回结果可以看到
2024-09-21这一天内,移动的数据量为183117965820字节,折合约为170.5 GB。
步骤四:预估任务进度及完成时间
MongoDB 6.0之前版本操作方法
以下内容适用版本如下:
MongoDB 6.0之前版本实例.
内核小版本为7.0.1(基准版本为6.0.3)之前的MongoDB 6.0实例。如何查看内核小版本,请参见MongoDB小版本说明。
获取分片表已成功迁移的Chunk数量以及当前分片表数据分布情况后,您就可以预估出任务的整体进度和预期完成时间。
假如当前增加Shard节点的场景中,总Chunk数量保持不变,Shard节点数量也保持不变(期间不会有新增或删除Shard节点的任务),增加Shard节点的过程中业务负载基本保持固定,且Balancer的参数设置均为默认值。以步骤三的MongoDB 6.0之前版本操作方法中示例为例,可以得知以下信息:
Shard节点数量为5。
在Balancer窗口期内,成功迁移的Chunk数量为300个。
分片表
<db>.<collection>的总Chunk数量为58260个(13630+13629+13652+13630+3719=58260)。
因此可以计算出:
达到均衡状态时,每个分片上的Chunk数量应为11652个(58260÷5=11652)。
按照当前的迁移速度,任务完成还需要26.4天((11652-3719)÷300≈26.4)。
该增加Shard节点任务进度为32%(3719÷11652=32%)。
实际的业务场景中,总Chunk数量还会随着业务写入以及Chunk分裂而增加。因此假设条件为理想情况,实际耗时可能会更久。
MongoDB 6.0之后版本操作方法
以下内容适用版本如下:
MongoDB 6.0之后版本实例.
内核小版本为7.0.1(基准版本为6.0.3)及以后的MongoDB 6.0实例。如何查看内核小版本,请参见MongoDB小版本说明。
假如分片集群实例中只有一个表需要均衡。以步骤三的MongoDB 6.0以后版本操作方法中示例为例,可以得知以下信息:
Shard节点数量为4。
2024-09-21一天内移动的数据量约为170.5GB(183117965820字节)。分片表
<db>.<collection>的总数据量约为1910.4GB(833101815840+409714745937+178157177704+630329790750=2051303530231字节)。
因此可以计算出:
达到均衡状态时,每个Shard上的数据量应大致为477.6GB(512825882557.75字节)。
各个分片上为了达到均衡状态,需要移动的总数据量为875559682949字节,折合815.4GB。其中:
Shard1需要迁移的数据量为320275933282.25字节(833101815840-512825882557.75)。
Shard2需要迁移的数据量为103111136620.75字节(409714745937-512825882557.75)。
Shard3需要迁移的数据量为334668704853.75字节(178157177704-512825882557.75)。
Shard4需要迁移的数据量为117503908192.25字节(630329790750-512825882557.75)。
(320275933282.25+103111136620.75+334668704853.75+117503908192.25=875559682949)
按照当前的迁移速度,达到均衡状态还需要大概4.8天(815.4 GB÷170.5 GB/天≈4.8天)。
步骤五:确认任务流是否阻塞(删除Shard节点)
如果删除Shard节点的任务被阻塞,执行sh.status()命令后,返回信息中没有看到过去时间段有Chunk数据迁移成功,且待删除Shard节点上依然残留部分Chunk数据未迁移走。此时删除Shard节点任务无法完成,并且会影响您在云数据库MongoDB控制台对实例的其他运维操作。
上述场景中sh.status()命令的返回信息示例如下图所示。
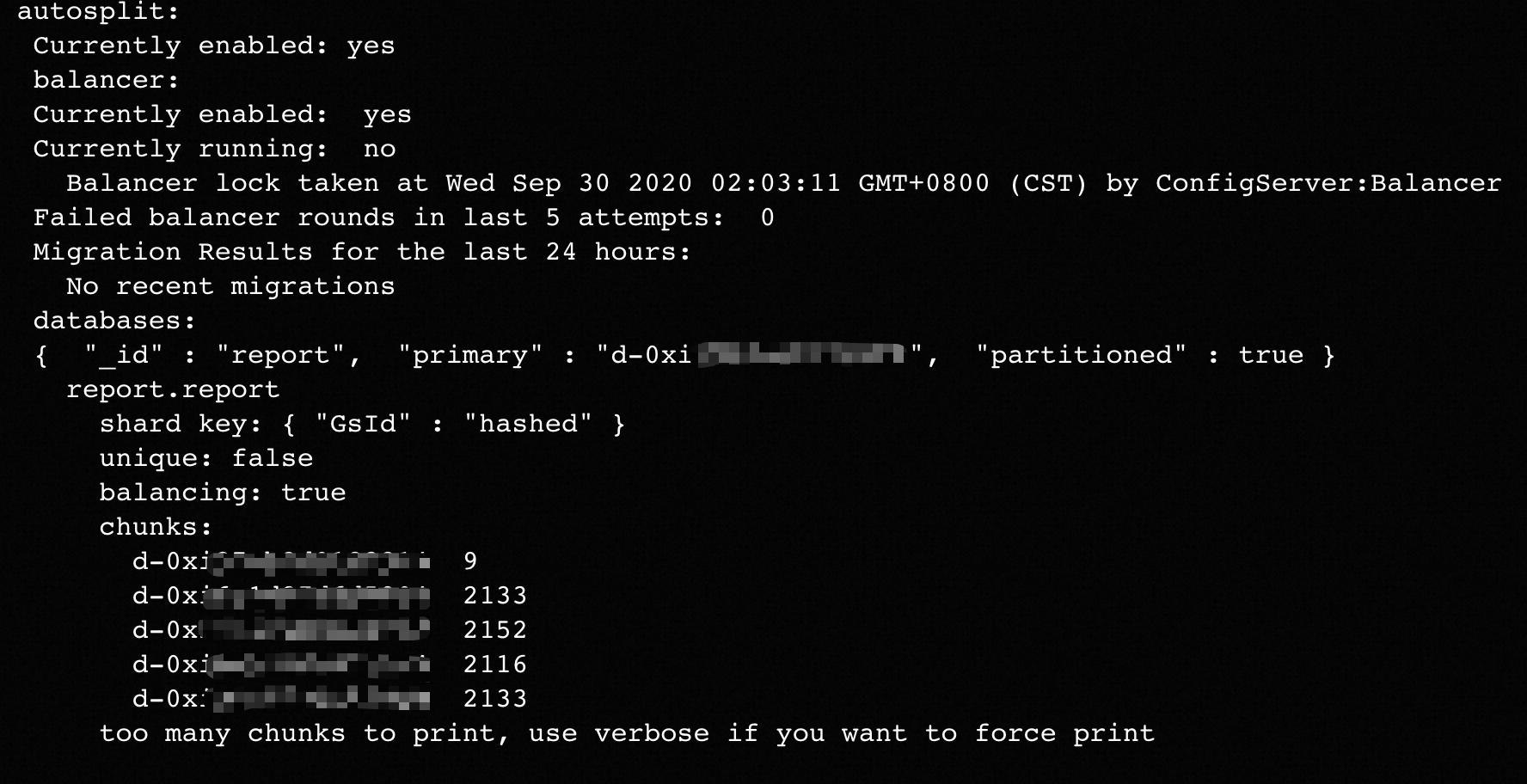
出现上述问题可能是因为Jumbo Chunk阻塞了删除Shard节点的进程,您可以通过如下的命令确认。
db.getSiblingDB("config").chunks.aggregate([{$match: {shard: "d-xxxxxxxxxxxxxx", jumbo:true}},{$group: {_id: "$ns", count: {$sum: 1}}}])一般情况下,出现Jumbo Chunk是因为设计的分片键(Shard Key)不合理(例如存在热点Key)等因素导致。您可以在业务侧尝试使用以下方法解决:
如果您的MongoDB数据库的大版本为4.4,则可以通过refineCollectionShardKey命令来优化您的Shard key设计,通过为原本分片键添加后缀的方式来使得分片键的基数更大,从而解决Jumbo Chunk的问题。
如果您的MongoDB数据库的大版本为5.0及以上,则可以通过reshardCollection命令来将指定分片表按照新的分片键重新分片。更多介绍,请参见Reshard a Collection。
如果您确认部分业务数据可删除,则可以删除对应Jumbo Chunk中的数据,该方法可以减少Jumbo Chunk的大小。减少数据后Jumbo Chunk可能成为一个普通的Chunk,然后被均衡器Balancer迁出。
您可以调大
chunkSize参数来使判断Jumbo Chunk的条件发生变化,建议在阿里云技术支持工程师的协助下进行操作。
如果以上方法都无法解决您的问题,建议您提交工单联系技术支持协助解决。
加速新增或删除任务进程
如果您希望增删Shard节点的整体流程可以在更短的时间内完成,您可以尝试以下加速方法:
将Balancer的窗口期时间调大,Chunk迁移过程带来的额外负载可能会对业务侧产生影响,请您评估风险后再进行调整。调整Balancer窗口期的方法,请参见管理MongoDB均衡器Balancer。
调整分片集群实例的setParameter.chunkMigrationConcurrency参数修改Chunk迁移的并发数,该参数的使用说明,请参见参数调优建议。
在业务低峰期手动执行
moveChunk操作,更多介绍,请参见sh.moveChunk()。示例如下。sh.moveChunk("<db>.<collection>", {"<shard_key>": <value>}, "d-xxxxxxxxxxxxx") // example: sh.moveChunk("records.people", { zipcode: "53187" }, "shard0019")提交工单联系技术支持对相关内核参数进行调整。