本文为您介绍如何在PyODPS中查看一级分区。
前提条件
请提前完成如下操作:
在DataWorks上完成业务流程创建。详情请参见创建业务流程。
操作步骤
说明
本例使用DataWorks简单模式,创建工作空间时,默认保持参加数据开发(Data Studio)公测不开启,公测工作空间不适用本例。
准备测试数据。
创建表并上传数据。操作方法请参见建表并上传数据。
表结构以及源数据信息如下。
分区表user_detail建表语句如下。
CREATE TABLE IF NOT EXISTS user_detail ( userid BIGINT COMMENT '用户id', job STRING COMMENT '工作类型', education STRING COMMENT '教育程度' ) COMMENT '用户信息表' PARTITIONED BY (dt STRING COMMENT '日期',region STRING COMMENT '地区');源数据表user_detail_ods建表语句如下。
CREATE TABLE IF NOT EXISTS user_detail_ods ( userid BIGINT COMMENT '用户id', job STRING COMMENT '工作类型', education STRING COMMENT '教育程度', dt STRING COMMENT '日期', region STRING COMMENT '地区' );测试数据保存为user_detail.txt文件。将此文件上传至表user_detail_ods中。
0001,互联网,本科,20190715,beijing 0002,教育,大专,20190716,beijing 0003,金融,硕士,20190715,shandong 0004,互联网,硕士,20190715,beijing
将源数据表
user_detail_ods中的数据写入分区表user_detail。登录DataWorks控制台。
在左侧导航栏,单击工作空间。
确认目标工作空间,选择操作列中的。
右键单击业务流程,选择。
输入节点名称,并单击确认。
在ODPS SQL节点中输入如下代码。
INSERT OVERWRITE TABLE user_detail PARTITION (dt, region) SELECT userid, job, education, dt, region FROM user_detail_ods;单击运行,完成数据写入。
使用PyODPS查看一级分区。
登录DataWorks控制台。
在左侧导航栏,单击工作空间。
确认目标工作空间,选择操作列中的。
在数据开发页面,右键单击已经创建的业务流程,选择。
输入节点名称,单击确认。
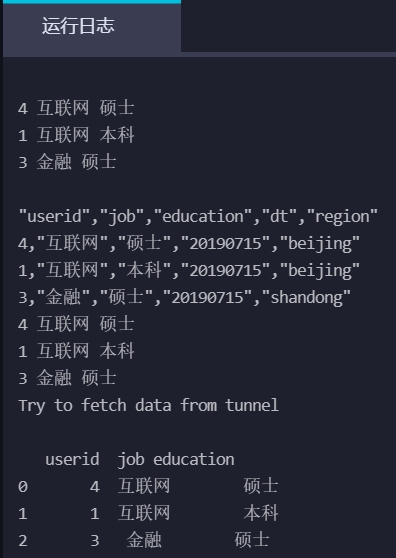
在PyODPS 2节点中输入如下代码查看一级分区数据。
import sys reload(sys) #修改系统默认编码。 sys.setdefaultencoding('utf8') #异步方式读取一级分区。 instance = o.run_sql('select * from user_detail WHERE dt=\'20190715\'') instance.wait_for_success() for record in instance.open_reader(): print record["userid"],record["job"],record["education"] #同步方式读取一级分区。 with o.execute_sql('select * from user_detail WHERE dt=\'20190715\'').open_reader() as reader4: print reader4.raw for record in reader4: print record["userid"],record["job"],record["education"] #使用ODPS的DataFrame获取一级分区。 pt_df = DataFrame(o.get_table('user_detail').get_partition('dt=20190715')) print pt_df.head(10)单击运行按钮。
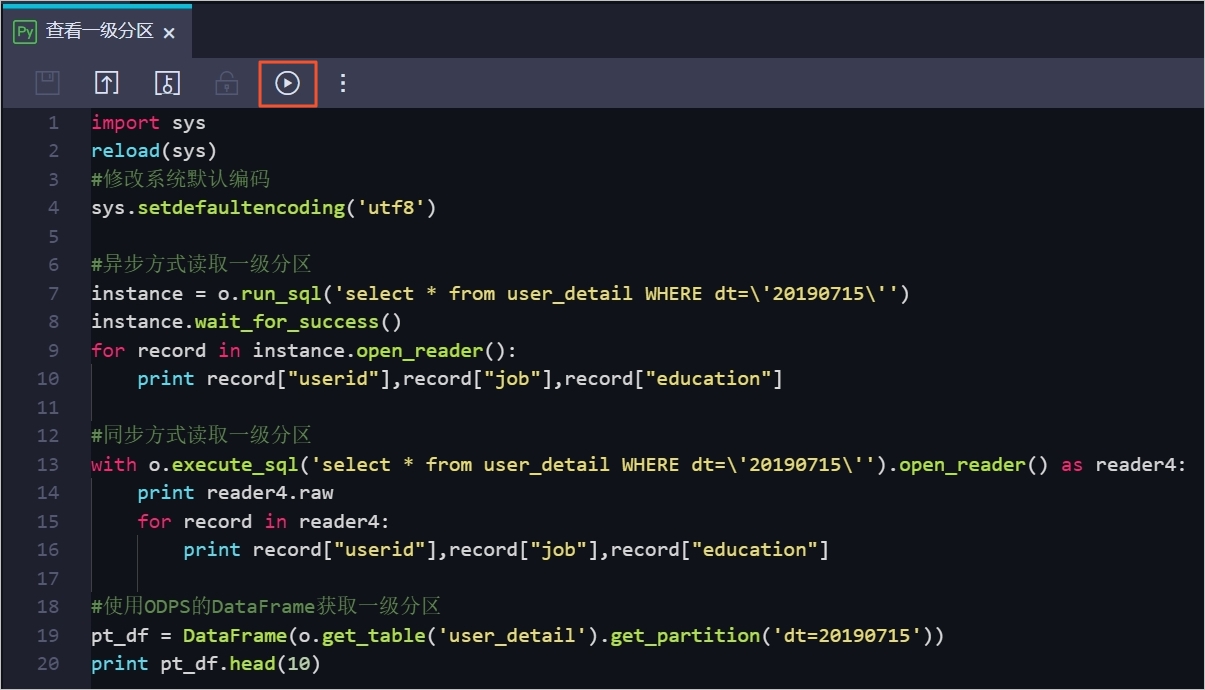
在运行日志中查看运行结果。