Spark on MaxCompute支持三种运行方式:Local模式、Cluster模式和DataWorks执行模式。
Local模式
Spark on MaxCompute支持用户以原生Spark Local模式进行作业调试。
与Yarn Cluster模式类似,您首先需要做以下准备工作:
准备MaxCompute项目以及对应的AccessKey ID、AccessKey Secret。
下载Spark on MaxCompute客户端。
准备环境变量。
配置spark-defaults.conf。
下载工程模板并编译。
上述操作更多信息,请参见搭建Linux开发环境。
通过Spark on MaxCompute客户端以Spark-Submit方式提交作业,代码示例如下:
## Java/Scala
cd $SPARK_HOME
./bin/spark-submit --master local[4] --class com.aliyun.odps.spark.examples.SparkPi \
/path/to/odps-spark-examples/spark-examples/target/spark-examples-2.0.0-SNAPSHOT-shaded.jar
## PySpark
cd $SPARK_HOME
./bin/spark-submit --master local[4] \
/path/to/odps-spark-examples/spark-examples/src/main/python/odps_table_rw.py注意事项
Local模式读写MaxCompute表速度慢,是因为Local模式是通过Tunnel来读写的,读写速度相比于Yarn Cluster模式慢。
Local模式是在本地执行的,部分用户会经常遇到Local模式下可以访问VPC,但是在Yarn Cluster模式下无法访问VPC。
Local模式是处于用户本机环境,网络没有隔离。而Yarn Cluster模式是处于MaxCompute的网络隔离环境中,必须要配置VPC访问相关参数。
Local模式下访问VPC的Endpoint通常是外网Endpoint,而Yarn Cluster模式下访问VPC的Endpoint通常是VPC网络Endpoint。更多Endpoint信息,请参见Endpoint。
IDEA Local模式下需要将相关配置写入代码中,而在Yarn Cluster模式运行时一定要将这些配置从代码中删除。
IDEA Local模式执行
Spark on MaxCompute支持用户在IDEA中以Local[N]的模式直接运行代码,而不需要通过Spark on MaxCompute客户端提交,您需要注意以下两点:
在IDEA中运行Local模式时,不能直接引用spark-defaults.conf的配置,需要手动指定相关配置,即在
main下创建resource>odps.conf目录,并在odps.conf中指定相关配置。配置示例如下:说明Spark 2.4.5及以上版本需要在
odps.conf中指定配置项。dops.access.id="" odps.access.key="" odps.end.point="" odps.project.name=""务必注意需要在IDEA中手动添加Spark on MaxCompute客户端的相关依赖(
jars目录),否则会出现如下报错:the value of spark.sql.catalogimplementation should be one of hive in-memory but was odps您可以按照如下流程配置依赖:
在IDEA的顶部菜单栏,选择。
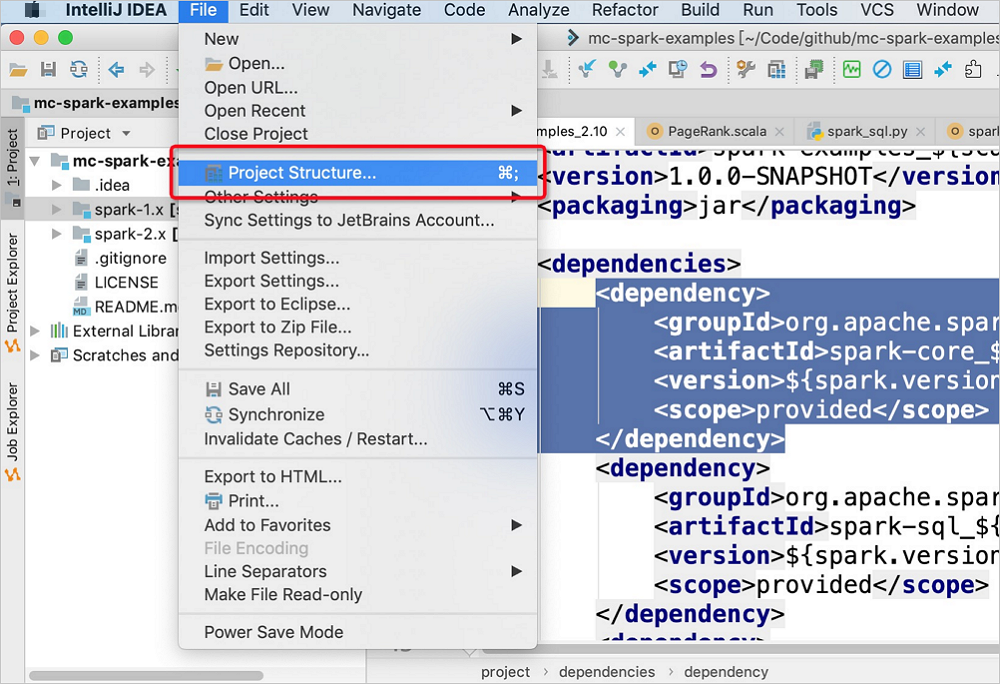
在Project Structure的Modules页面,选择目标Spark Module。单击右侧Dependencies后,在左下角单击
 图标,选择JARS or directories...。
图标,选择JARS or directories...。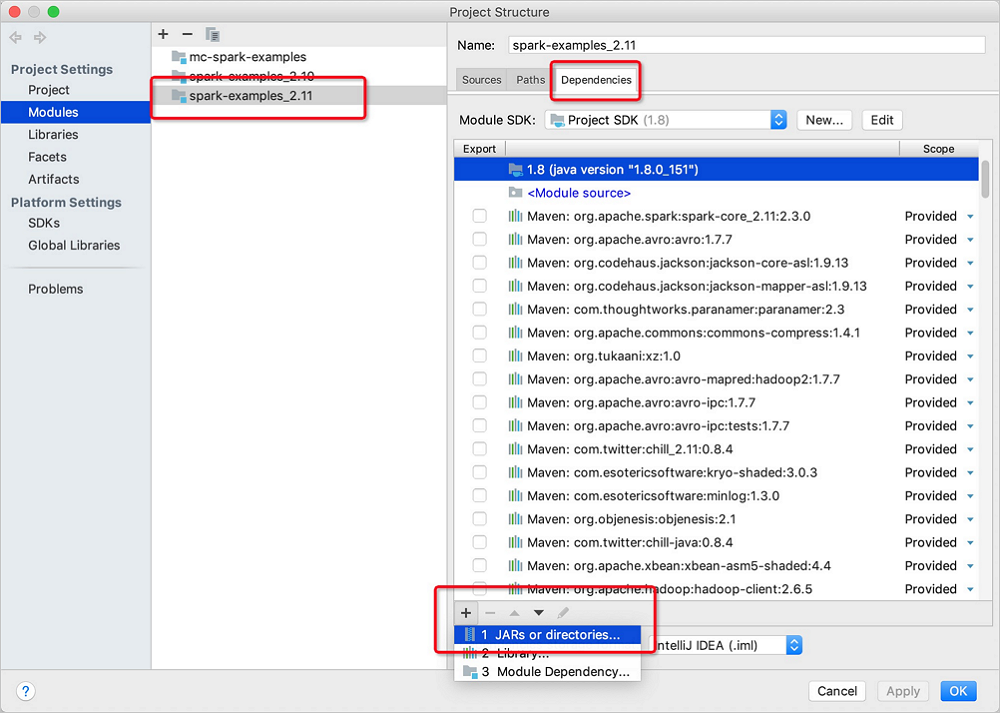
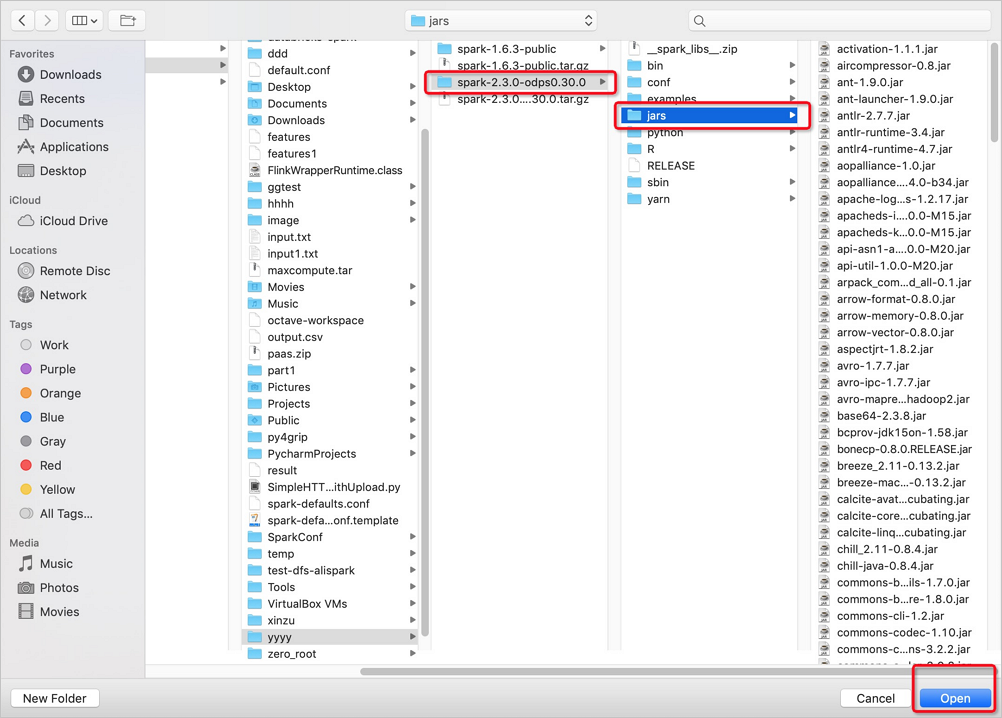
在打开的jars目录下,选择Spark on MaxCompute版本及jars,单击Open。
单击OK。
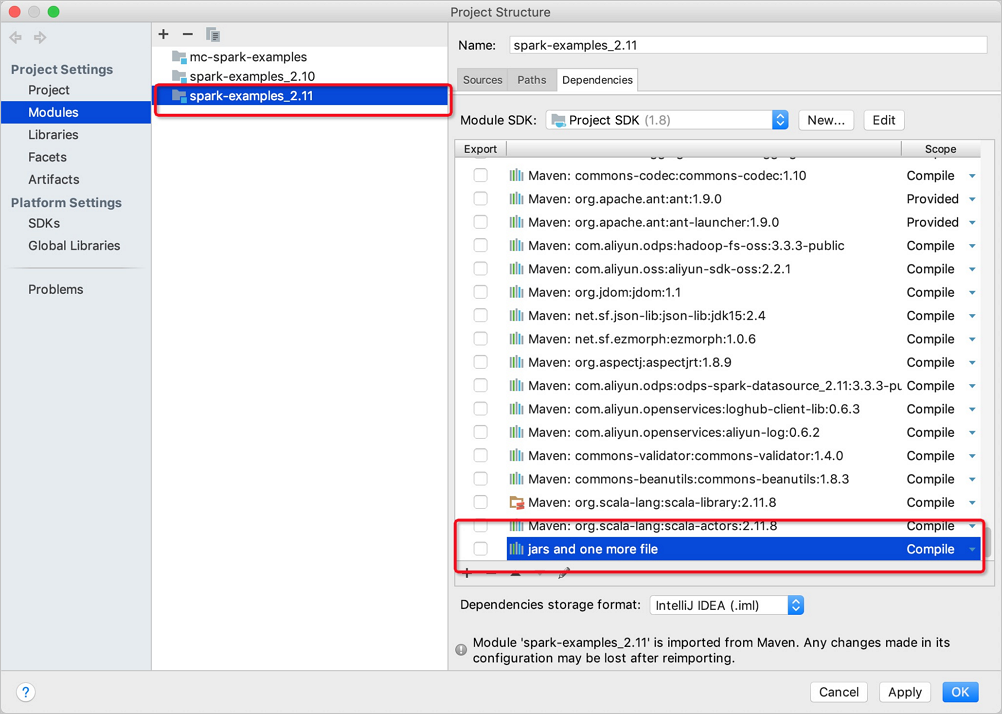
通过IDEA提交作业。
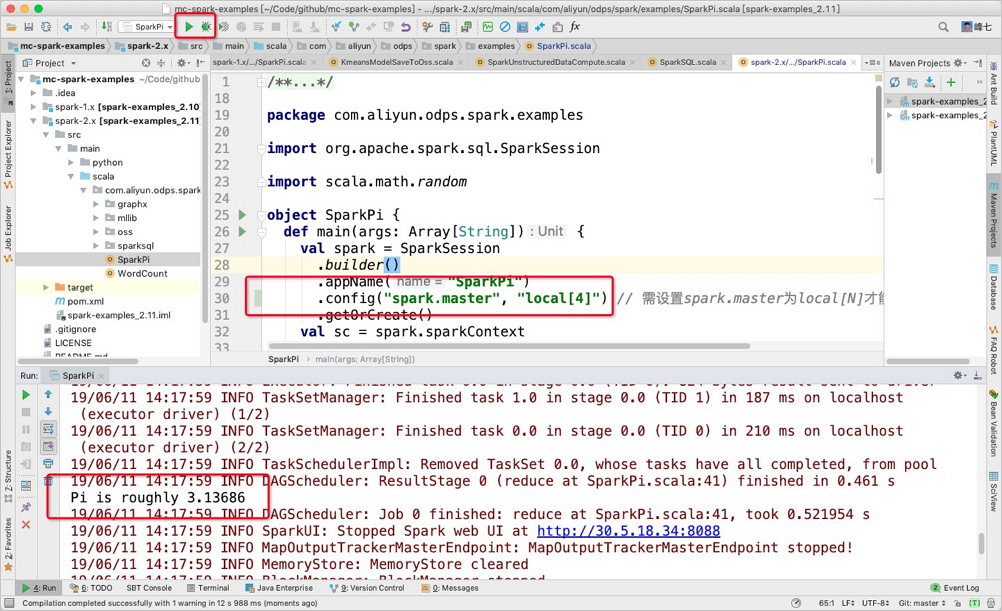
Cluster模式
在Cluster模式中,您需要指定自定义程序入口main。main结束(Success or Fail)时,对应的Spark作业就会结束。使用场景适合于离线作业,可与阿里云DataWorks产品结合进行作业调度,命令行提交方式如下。
# /path/to/MaxCompute-Spark为编译后的Application JAR包路径。
cd $SPARK_HOME
bin/spark-submit --master yarn-cluster --class com.aliyun.odps.spark.examples.SparkPi \
/path/to/MaxCompute-Spark/spark-2.x/target/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jarDataWorks执行模式
您可以在DataWorks中运行Spark on MaxCompute离线作业(Cluster模式),以方便与其它类型执行节点集成和调度。
操作步骤如下:
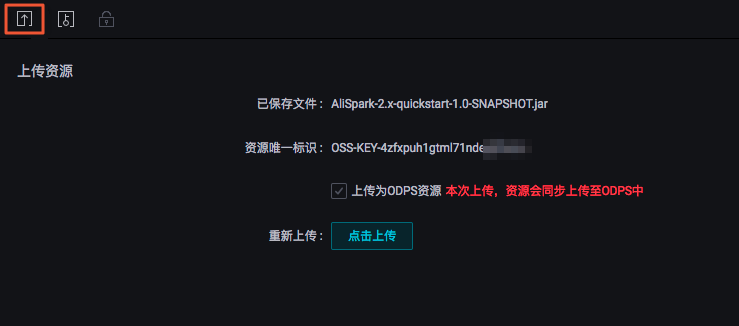
您需要在DataWorks的业务流程中上传并提交(单击提交按钮)资源。
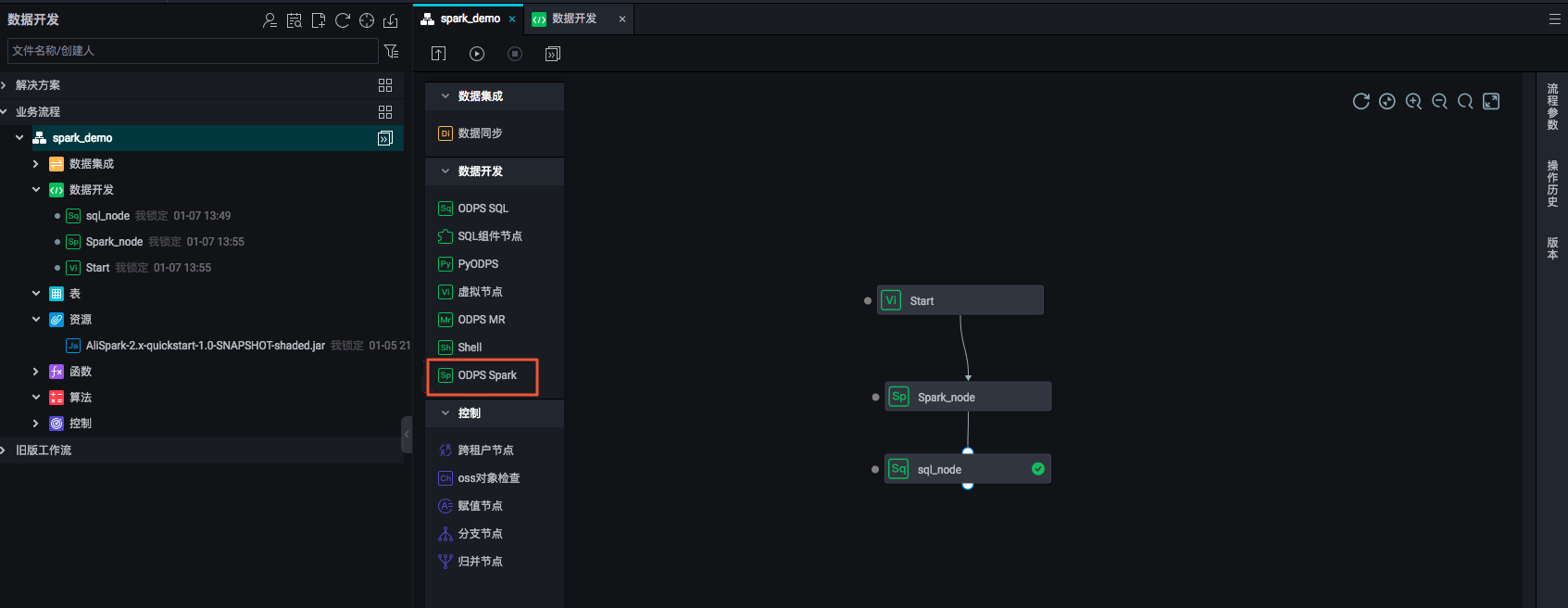
在创建的业务流程中,从数据开发组件中选择ODPS Spark节点。
双击工作流中的Spark节点,对Spark作业进行任务定义。
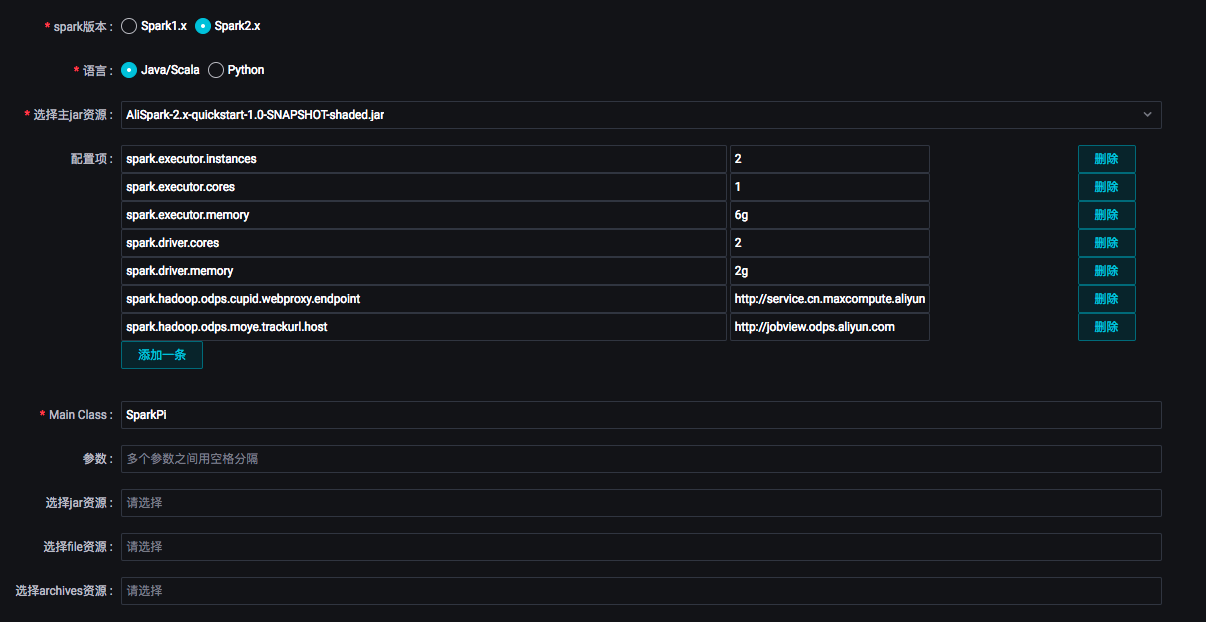 ODPS Spark节点支持三种spark版本和两种语言。选择不同的语言,会显示相应不同的配置。您可以根据界面提示进行配置,参数详情请参见开发ODPS Spark任务。其中:
ODPS Spark节点支持三种spark版本和两种语言。选择不同的语言,会显示相应不同的配置。您可以根据界面提示进行配置,参数详情请参见开发ODPS Spark任务。其中:选择主jar资源:指定任务所使用的资源文件。此处的资源文件需要您提前上传至DataWorks上。
配置项:指定提交作业时的配置项。
其中
spark.hadoop.odps.access.id、spark.hadoop.odps.access.key和spark.hadoop.odps.end.point无需配置,默认为MaxCompute项目的值(有特殊原因可显式配置,将覆盖默认值)。除此之外,
spark-defaults.conf中的配置需要逐条加到ODPS Spark节点配置项中,例如Executor的数量、内存大小和spark.hadoop.odps.runtime.end.point的配置。ODPS Spark节点的资源文件和配置项对应于spark-submit命令的参数和选项,如下表。此外,您也不需要上传spark-defaults.conf文件,而是将spark-defaults.conf文件中的配置都逐条加到ODPS Spark节点配置项中。
ODPS SPARK节点
spark-submit
主Java、Python资源
app jar or python file配置项
--conf PROP=VALUEMain Class
--class CLASS_NAME参数
[app arguments]选择JAR资源
--jars JARS选择Python资源
--py-files PY_FILES选择File资源
--files FILES选择Archives资源
--archives ARCHIVES
手动执行Spark节点,可以查看该任务的执行日志,从打印出来的日志中可以获取该任务的Logview和Jobview的URL,便于进一步查看与诊断。
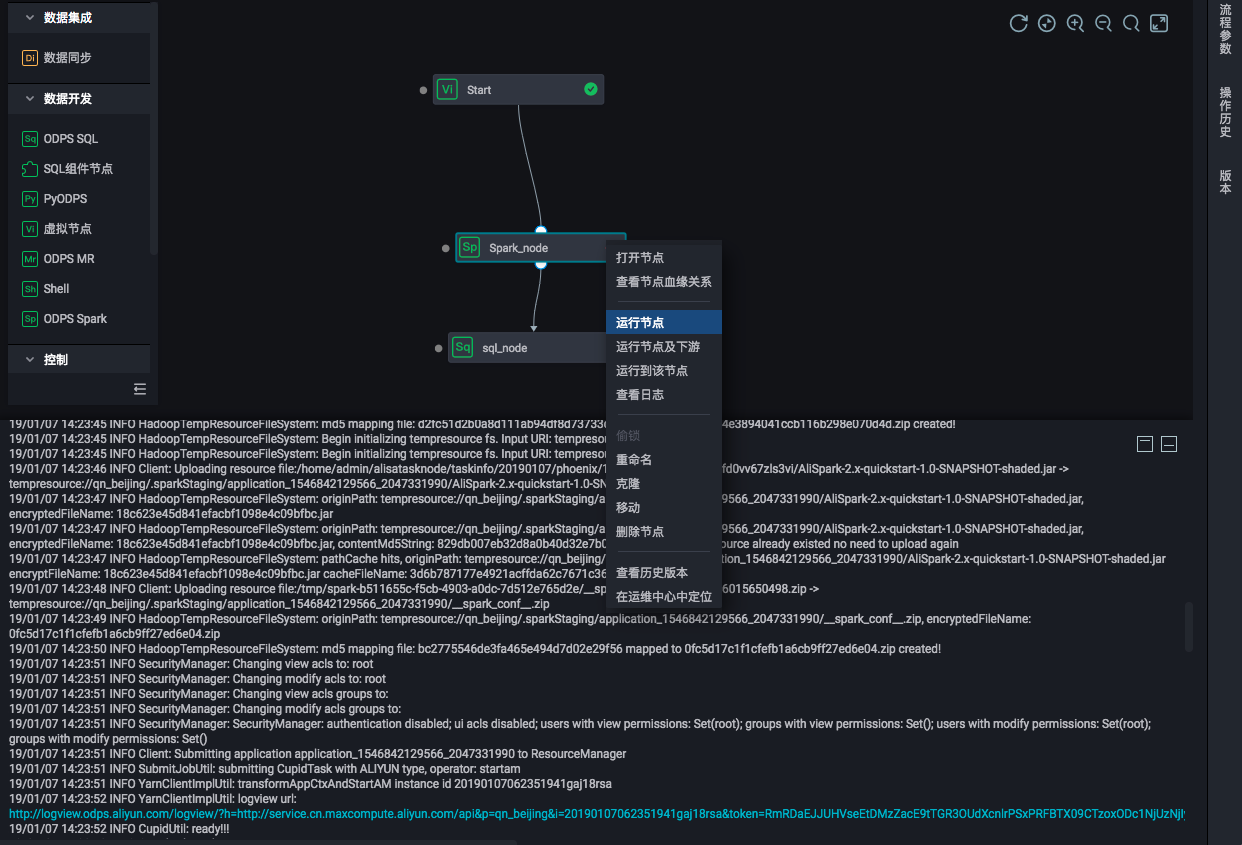
Spark作业定义完成后,即可在业务流程中对不同类型服务进行编排、统一调度执行。