MaxCompute支持通过创建Paimon外部表来与存储在OSS上的Paimon表目录建立映射关系,并访问其中的数据。本文将介绍如何创建Paimon外部表并通过MaxCompute访问Paimon外部表。
背景信息
Apache Paimon是一种流批一体的湖存储格式,具备高吞吐的写入和低延迟的查询能力。阿里云实时计算Flink版、开源大数据平台E-MapReduce的常见计算引擎(如Spark、Hive或Trino)都与Paimon有完善的集成。借助Apache Paimon,您可以快速构建自己的数据湖存储服务在存储服务OSS上,并接入MaxCompute实现数据湖的分析。关于Apache Paimon的详细信息,请参见Apache Paimon。
前提条件
当前执行操作的账号已具备创建MaxCompute表(CreateTable)的权限。更多表权限信息,请参见MaxCompute权限。
已创建MaxCompute项目。具体操作,请参见创建MaxCompute项目。
已创建存储空间(Bucket)以及对应的文件目录。具体操作,请参见创建存储空间。
说明由于MaxCompute只在部分地域部署,跨地域的数据连通性可能存在问题,因此建议Bucket与MaxCompute项目所在地域保持一致。
已购买Flink全托管,具体操作请参见开通实时计算Flink版。
注意事项
当前MaxCompute仅支持对Paimon外部表的读取操作,暂时不支持写入和自动跟随Paimon表结构变更等操作。
Paimon当前暂时不支持开启了Schema操作的MaxCompute项目。
Paimon外部表不支持cluster属性。
Paimon外部表暂不支持查询回溯历史版本的数据等特性。
创建Paimon外部表命令语法
MaxCompute创建Paimon外部表的语法定义如下:
CREATE EXTERNAL TABLE [if NOT EXISTS] <mc_oss_extable_name>
(
<col_name> <data_type>,
...
)
[partitioned BY (<col_name> <data_type>, ...)]
stored BY 'org.apache.paimon.hive.PaimonStorageHandler'
WITH serdeproperties (
'odps.properties.rolearn'='acs:ram::xxxxxxxxxxxxx:role/aliyunodpsdefaultrole'
)
location '<oss_location>'
USING 'paimon_maxcompute_connector.jar';若您创建的Paimon外部表为分区表时,需要额外执行引入分区数据的操作。命令详情,请参见补全OSS外部表分区数据语法。
方式一(推荐):自动解析OSS目录结构,识别分区,为OSS外部表添加分区信息。
msck repair TABLE <mc_oss_extable_name> ADD partitions;方式二:手动执行如下命令为OSS外部表添加分区信息。
ALTER TABLE <mc_oss_extable_name> ADD PARTITION (<col_name>= <col_value>);
参数说明如下:
参数名称 | 可选/必填 | 说明 |
mc_oss_extable_name | 必填 | 待创建的Paimon外部表的名称。 表名大小写不敏感,在查询外部表时,无需区分大小写,且不支持强制转换大小写。 |
col_name | 必填 | Paimon外部表的列名称。 在读取Paimon数据场景,创建的Paimon外部表结构必须与Paimon数据文件结构保持一致,否则无法成功读取Paimon数据。 |
data_type | 必填 | Paimon外部表的列数据类型。 在读取Paimon数据场景,创建的Paimon外部表各列数据类型必须与Paimon数据文件各列数据类型保持一致,否则无法成功读取Paimon数据。 |
odps.properties.rolearn | 必填 | 指定RAM中Role(具有访问OSS权限)的ARN信息。 您可以通过RAM控制台中的角色详情获取。 |
oss_location | 必填 | 数据文件所在OSS路径。格式为
|
使用说明
步骤一:在Flink中准备数据
创建Paimon Catalog和Paimon表,并在表中插入数据,参考示例操作步骤如下。如果您在Flink中已有Paimon表和数据,可以跳过此步。
登录实时计算控制台,创建Paimon Catalog。具体操作,请参见创建Paimon Catalog。
创建Paimon表。具体操作,请参见管理Paimon表。
在元数据管理页面,选择已创建Paimon Catalog下的default,然后单击创建表,如下图所示。
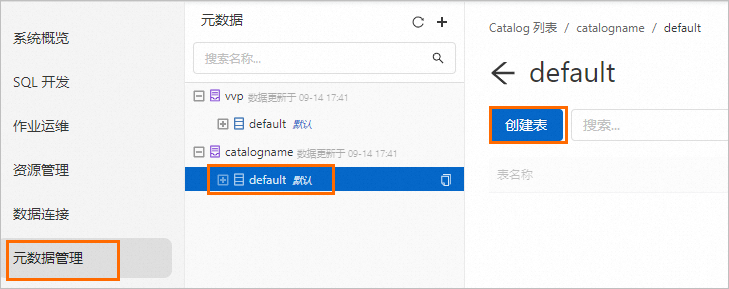
在添加表对话框,选择Apache Paimon连接器,输入以下语句,单击确定。本文以test_tbl表为例。
CREATE TABLE `catalogname`.`default`.test_tbl ( dt STRING, id BIGINT, data STRING, PRIMARY KEY (dt, id) NOT ENFORCED ) PARTITIONED BY (dt);在SQL 开发页面,创建包含如下语句的SQL作业,部署并运行作业。关于如何创建并运行SQL作业详情,请参见SQL作业开发。
INSERT INTO `catalogname`.`default`.test_tbl VALUES ('2023-04-21', 1, 'AAA'), ('2023-04-21', 2, 'BBB'), ('2023-04-22', 1, 'CCC'), ('2023-04-22', 2, 'DDD');说明请确认SQL作业的引擎版本为vvr-8.0.1-flink-1.17及以上版本。
若SQL作业有限流作业(例如执行
INSERT INTO ... VALUES ...语句),需要在作业运维页面,编辑运行参数配置,在其他配置设置execution.checkpointing.checkpoints-after-tasks-finish.enabled: true代码。关于如何配置作业的运行参数详情,请参见配置作业部署信息。
步骤二:在MaxCompute项目中上传Paimon插件
您可以选择以下其中一种方式,在已创建的MaxCompute项目中上传Paimon插件。
使用MaxCompute客户端
通过客户端(odpscmd)访问已创建的MaxCompute项目,并执行以下代码,将paimon_maxcompute_connector.jar上传至MaxCompute项目中。
ADD JAR <path_to_paimon_maxcompute_connector.jar>;使用DataWorks
登录DataWorks控制台,在左侧导航栏选择工作空间,单击目标工作空间操作列中的快速进入 > 数据开发。
在数据开发页面,单击新建按钮,选择新建资源 > JAR。
在新建资源对话框,配置新建资源参数,上传
paimon_maxcompute_connector.jar,单击新建。新建资源操作详情,请参见步骤一:创建或上传资源。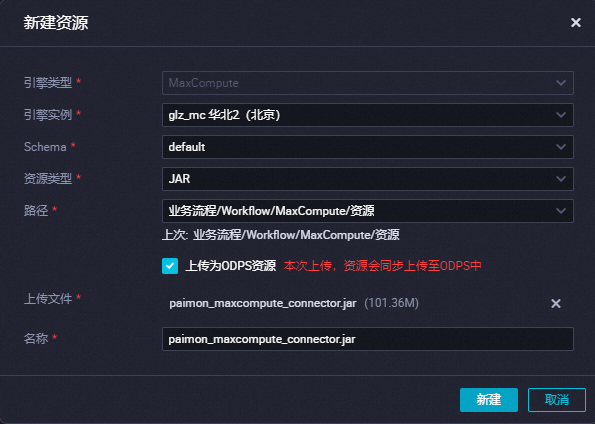
资源创建完成后,您需在资源编辑页面,单击工具栏中的
 图标,提交资源至调度开发服务器端。
图标,提交资源至调度开发服务器端。
步骤三:通过MaxCompute创建Paimon外表
使用本地客户端(odpscmd)连接或其他可以运行MaxCompute SQL的工具,创建MaxCompute Paimon外部表。本文以oss_extable_paimon_1pt为例。
CREATE EXTERNAL TABLE oss_extable_paimon_1pt
(
id BIGINT,
data STRING
)
PARTITIONED BY (dt STRING )
stored BY 'org.apache.paimon.hive.PaimonStorageHandler'
WITH serdeproperties (
'odps.properties.rolearn'='acs:ram::124*********:role/aliyunodpsdefaultrole'
)
location 'oss://oss-cn-beijing-internal.aliyuncs.com/paimon_flink/test_db_y.db/test_tbl/'
USING 'paimon_maxcompute_connector.jar'
;步骤四:通过MaxCompute读取Paimon外部表
使用本地客户端(odpscmd)或其他可以运行MaxCompute SQL的工具,执行以下命令。
SET odps.sql.common.table.planner.ext.hive.bridge = true; SET odps.sql.hive.compatible = true;执行以下命令,查询MaxCompute Paimon外部表
oss_extable_paimon_1pt。SELECT * FROM oss_extable_paimon_1pt;示例返回结果如下。
+------------+------------+------------+ | id | data | dt | +------------+------------+------------+ | 1 | AAA | 2023-04-21 | | 2 | BBB | 2023-04-21 | +------------+------------+------------+说明若返回结果中没有显示分区信息,您可以通过如下命令追加分区信息:
msck repair table oss_extable_paimon_1pt add partitions;
相关文档
您还可以在Flink中以自定义Catalog的方式创建MaxCompute Paimon外部表,并在写入数据后,通过MaxCompute查询并消费Paimon数据,详情请参见基于Flink创建MaxCompute Paimon外部表。