物化视图(Materialized View)是一种预先计算的方式,通过保存某些耗时操作(例如JOIN、AGGREGATE)的结果,以便在查询时直接复用,从而避免重复执行这些耗时操作,最终实现加速查询的目的。
背景信息
视图是一种虚拟表,任何对视图的查询,都会转换为视图SQL语句的查询。而物化视图是一种特殊的物理表,物化视图会存储实际的数据,占用存储资源。更多物化视图计费信息,请参见计费规则。
物化视图适用于如下场景:
模式固定、且执行频次高的查询。
查询包含非常耗时的操作,比如聚合、连接操作等。
查询仅涉及表中的很小部分数据。
物化视图与传统查询的对比如下。
对比项 | 传统查询方式 | 物化视图查询方式 |
查询语句 | 直接使用SQL语句查询数据。 | 您需要创建物化视图,然后基于物化视图查询数据。 创建物化视图语句如下: 基于创建的物化视图查询数据: 如果物化视图开启了查询改写功能,使用如下SQL语句查询数据时会直接从物化视图中查询数据: |
查询特点 | 查询涉及读表、JOIN、过滤(WHERE)操作。当源表数据量很大时,查询速度会很慢。操作复杂度较高,运行效率低。 | 查询涉及读表、过滤操作。不涉及JOIN操作。MaxCompute会自动匹配到最优物化视图,并直接从物化视图中读取数据,从而大大提高查询效率。 |
操作命令
类型 | 功能 | 角色 | 操作入口 |
基于查询语句创建物化视图。 | 具备项目创建表权限(CreateTable)的用户。 | 本文中的命令您可以在如下工具平台执行: | |
更新已创建的物化视图。 | 具备修改表权限(Alter)的用户。 | ||
修改已创建的物化视图的生命周期。 | 具备修改表权限(Alter)的用户。 | ||
开启或禁用已创建的物化视图的生命周期。 | 具备修改表权限(Alter)的用户。 | ||
查询物化视图的基本信息。 | 具备读取表元信息权限(Describe)的用户。 | ||
查看物化视图有效或无效。 | 具备读取表元信息权限(Describe)的用户。 | ||
列出项目下所有的物化视图,或符合某些规则的物化视图。 | 具备项目查看对象列表权限(List)的用户。 | ||
删除已创建的物化视图。 | 具备删除表权限(Drop)的用户。 | ||
删除已创建的物化视图的分区。 | 具备删除表权限(Drop)的用户。 | ||
当查询的分区数据不存在时,需要自动实现到原始分区表查询数据。 | 具备项目写权限(Write)及创建表权限(CreateTable)的用户。 | ||
对查询语句进行查询改写。 | 具备项目写权限(Write)及创建表权限(CreateTable)的用户。 | ||
定时更新已创建物化视图的数据。 | 具备修改表权限(Alter)的用户。 |
使用限制
不支持窗口函数、UDTF函数和非确定性函数(例如UDF、UDAF等)。
当您的业务场景必须要使用非确定性函数时,请在Session级别设置属性set odps.sql.materialized.view.support.nondeterministic.function=true;。
创建物化视图(支持分区和聚簇)
基于满足物化视图场景的数据创建物化视图,支持分区和聚簇场景。
使用限制
物化视图的名称不允许和当前项目中的已有表、视图、物化视图名称重复。您可以通过
SHOW TABLES;命令查看项目中的全部表及物化视图名称。不支持基于现有的物化视图创建新的物化视图。
不支持基于外部表创建物化视图。
注意事项
当查询语句执行失败时,物化视图也会创建失败。
物化视图分区列必须来源于某张源表,其顺序和列数目必须和源表一样,列名称可以不一样。
列注释需要指定所有列,包含分区列。如果只指定部分列,会报错。
可以同时指定分区和聚簇,此时每个分区中的数据都有指定的聚簇属性。
当查询语句中包含不支持的算子时会报错。物化视图支持的算子列表,请参见物化视图查询改写操作。
MaxCompute默认不支持使用非确定性函数(例如UDF、UDAF等)创建物化视图。当您的业务场景必须要使用非确定性函数时,请在Session级别设置属性
set odps.sql.materialized.view.support.nondeterministic.function=true;。物化视图支持生成空分区,原始表分区为空的时候,刷新物化视图,自动生成空分区。
命令格式
CREATE MATERIALIZED VIEW [IF NOT EXISTS][project_name.]<mv_name> [LIFECYCLE <days>] --指定生命周期 [BUILD DEFERRED] -- 指定是在创建时只生成表结构,不生成数据 [(<col_name> [COMMENT <col_comment>],...)] --列注释 [DISABLE REWRITE] --指定是否用于改写 [COMMENT 'table comment'] --表注释 [PARTITIONED BY (<col_name> [, <col_name>, ...]) --创建物化视图表为分区表 [CLUSTERED BY|RANGE CLUSTERED BY (<col_name> [, <col_name>, ...]) [SORTED BY (<col_name> [ASC | DESC] [, <col_name> [ASC | DESC] ...])] INTO <number_of_buckets> BUCKETS] --用于创建聚簇表时设置表的Shuffle和Sort属性 [REFRESH EVERY <num> MINUTES/HOURS/DAYS] [TBLPROPERTIES("compressionstrategy"="normal/high/extreme", --指定表数据存储压缩策略 "enable_auto_substitute"="true", --指定当分区不存在时是否转化视图来查询 "enable_auto_refresh"="true", --指定是否开启自动刷新 "refresh_interval_minutes"="120", --指定刷新时间间隔 "only_refresh_max_pt"="true" --针对分区物化视图,只自动刷新源表最新分区 )] AS <select_statement>;参数说明
参数
是否必填
说明
IF NOT EXISTS
否
如果没有指定IF NOT EXISTS且物化视图已经存在,会返回报错。
project_name
否
物化视图所属目标MaxCompute项目名称。不填写时表示当前所在MaxCompute项目。您可以登录MaxCompute管理控制台,左上角切换地域后,即可在工作区 > 项目管理页面查看到具体的MaxCompute项目名称。
mv_name
是
新建物化视图的名称。
days
否
指定物化视图的生命周期,单位为天。取值范围为1~37231。
BUILD DEFERRED
否
如果加上这个关键字代表创建物化视图时,只生成表结构,不刷新数据。
col_name
否
指定物化视图的列名称。
col_comment
否
指定物化视图的列的注释。
DISABLE REWRITE
否
设置禁止通过物化视图执行查询改写操作。不指定时表示允许通过物化视图执行查询改写操作,您可以执行
ALTER MATERIALIZED VIEW [project_name.]<mv_name> DISABLE REWRITE;命令禁止通过物化视图执行查询改写操作。同理您可以执行ALTER MATERIALIZED VIEW [project_name.]<mv_name> ENABLE REWRITE;命令允许通过物化视图执行查询改写操作。PARTITIONED BY
否
指定物化视图分区字段,表示创建的物化视图表为分区表。
CLUSTERED BY|RANGE CLUSTERED BY
否
用于创建聚簇表时设置表的Shuffle属性。
SORTED BY
否
用于创建聚簇表时设置表的Sort属性。
REFRESH EVERY
否
用于设置物化视图定时更新间隔。单位可选择:分钟/小时/天。
number_of_buckets
否
用于创建聚簇表时设置表分桶数。
TBLPROPERTIES
否
compressionstrategy指定表数据的存储压缩策略,可以选normal、high或extreme。enable_auto_substitute指定当分区不存在时是否自动穿透到原始分区表去查询数据,详细信息请参见物化视图查询改写。
enable_auto_refresh:可选,当需要自动刷新数据时需要设置为
true。refresh_interval_minutes:条件可选,当
enable_auto_refresh为true时,需要配置刷新间隔时间,单位为分钟。only_refresh_max_pt:可选,只适用于带分区的物化视图,但设置为
true时,只会刷新源表最新分区。
select_statement
是
查询语句,详细格式请参见SELECT语法。
使用示例
示例一:创建物化视图。
创建
mf_t和mf_t1两张表并插入数据。CREATE TABLE IF NOT EXISTS mf_t( id bigint, value bigint, name string) PARTITIONED BY (ds STRING); ALTER TABLE mf_t ADD PARTITION (ds='1'); INSERT INTO mf_t PARTITION (ds='1') VALUES (1,10,'kyle'),(2,20,'xia'); SELECT * FROM mf_t WHERE ds ='1'; -- 返回结果如下。 +------------+------------+------------+------------+ | id | value | name | ds | +------------+------------+------------+------------+ | 1 | 10 | kyle | 1 | | 2 | 20 | xia | 1 | +------------+------------+------------+------------+ CREATE TABLE IF NOT EXISTS mf_t1( id bigint, value bigint, name string) PARTITIONED BY (ds STRING); ALTER TABLE mf_t1 ADD PARTITION (ds='1'); INSERT INTO mf_t1 PARTITION (ds='1') VALUES (1,10,'kyle'),(3,20,'john'); SELECT * FROM mf_t1 WHERE ds ='1'; -- 返回结果如下。 +------------+------------+------------+------------+ | id | value | name | ds | +------------+------------+------------+------------+ | 1 | 10 | kyle | 1 | | 3 | 20 | john | 1 | +------------+------------+------------+------------+创建物化视图。
示例1:创建以ds为分区列的物化视图。
CREATE MATERIALIZED VIEW mf_mv LIFECYCLE 7 ( key comment 'unique id', value comment 'input value', ds comment 'partitiion' ) PARTITIONED BY (ds) AS SELECT t1.id AS key, t1.value AS value, t1.ds AS ds FROM mf_t AS t1 JOIN mf_t1 AS t2 ON t1.id = t2.id AND t1.ds=t2.ds AND t1.ds='1'; --查询物化视图 SELECT * FROM mf_mv WHERE ds =1; +------------+------------+------------+ | key | value | ds | +------------+------------+------------+ | 1 | 10 | 1 | +------------+------------+------------+示例2:创建带有聚簇属性的非分区物化视图。
CREATE MATERIALIZED VIEW mf_mv2 LIFECYCLE 7 CLUSTERED BY (key) SORTED BY (value) INTO 1024 buckets AS SELECT t1.id AS key, t1.value AS value, t1.ds AS ds FROM mf_t AS t1 JOIN mf_t1 AS t2 ON t1.id = t2.id AND t1.ds=t2.ds AND t1.ds='1';示例3:创建带有聚簇属性的分区物化视图。
CREATE MATERIALIZED VIEW mf_mv3 LIFECYCLE 7 PARTITIONED BY (ds) CLUSTERED BY (key) SORTED BY (value) INTO 1024 buckets AS SELECT t1.id AS key, t1.value AS value, t1.ds AS ds FROM mf_t AS t1 JOIN mf_t1 AS t2 ON t1.id = t2.id AND t1.ds=t2.ds AND t1.ds='1';
示例二:原始表分区为空的时候,刷新物化视图,自动生成空分区。
CREATE TABLE mf_blank_pts(id bigint ,name string) PARTITIONED BY (ds bigint); ALTER TABLE mf_blank_pts ADD PARTITION (ds = 1); ALTER TABLE mf_blank_pts ADD PARTITION (ds = 2); INSERT INTO TABLE mf_blank_pts PARTITION(ds=1) VALUES (1,"aba"),(2,"cbd"); CREATE MATERIALIZED VIEW IF NOT EXISTS mf_mv_blank_pts PARTITIONED BY (ds) AS SELECT id,name,ds FROM mf_blank_pts; ALTER MATERIALIZED VIEW mf_mv_blank_pts REBUILD PARTITION (ds>0); SHOW PARTITIONS mf_mv_blank_pts; --原表分区ds=2是没有值,当刷新ds>0分区时,物化视图里有了空分区 ds=1 ds=2 SELECT * FROM mf_mv_blank_pts WHERE ds>0; --返回只有分区1有值 +------------+------------+------------+ | id | name | ds | +------------+------------+------------+ | 1 | aba | 1 | | 2 | cbd | 1 | +------------+------------+------------+
更新物化视图
当物化视图的数据对应的表或分区产生插入、覆写、更新、删除等操作时,物化视图会自动失效,无法用于查询改写。您可以先查看物化视图状态,当物化视图失效时,执行更新操作。查看物化视图状态操作,请参见查询物化视图信息。
注意事项
物化视图的更新操作只会更新源表有数据变化的表或者分区。
您可以开启物化视图定时更新功能来定时更新数据。详情请参见物化视图定时更新。
命令格式
ALTER MATERIALIZED VIEW [<project_name>.]<mv_name> REBUILD [PARTITION (<ds>=max_pt(<table_name>),<expression1>...)];参数说明
参数
是否必填
说明
project_name
否
物化视图所属目标MaxCompute项目名称。不填写时表示当前所在MaxCompute项目。您可以登录MaxCompute管理控制台,左上角切换地域后,即可在工作区 > 项目管理页面查看到具体的MaxCompute项目名称。
mv_name
是
待更新物化视图的名称。
ds
否
物化视图分区字段名称。
max_pt
否
取指定表或者物化视图(table_name)的最大分区值。
expression
否
当更新分区物化视图时,需要指定待更新分区信息,支持表达式。
使用示例
示例一:更新非分区物化视图。
-- 创建非分区表 CREATE TABLE count_test(a BIGINT, b BIGINT); --创建非分区物化视图 CREATE MATERIALIZED VIEW count_mv LIFECYCLE 7 AS SELECT COUNT(*) FROM count_test; --更新非分区物化视图 ALTER MATERIALIZED VIEW count_mv rebuild;示例二:更新分区物化视图的某个分区。
ALTER MATERIALIZED VIEW mf_mv_blank_pts REBUILD PARTITION (ds='1');示例三:更新分区物化视图的满足指定条件的分区。
ALTER MATERIALIZED VIEW mf_mv_blank_pts REBUILD PARTITION (ds>='1', ds<='2');示例四:更新分区物化视图的最新分区数据。
-- 创建示例分区表 CREATE TABLE IF NOT EXISTS sale_detail_jt (shop_name STRING , customer_id STRING , total_price DOUBLE ) PARTITIONED BY (sale_date STRING ,region STRING ); ALTER TABLE sale_detail_jt ADD PARTITION (sale_date='2013',region='china'); INSERT INTO sale_detail_jt PARTITION (sale_date='2013',region='china') VALUES ('s1','c1',100.1), ('s2','c2',100.2), ('s3','c3',100.3); ALTER TABLE sale_detail_jt ADD PARTITION (sale_date='2013',region='en'); INSERT INTO sale_detail_jt PARTITION (sale_date='2013',region='en') VALUES ('t1','c5',200.0), ('t2','c6',300.0); --查看分区数据 SELECT * FROM sale_detail_jt WHERE sale_date='2013' AND region='china'; +-----------+-------------+-------------+-----------+--------+ | shop_name | customer_id | total_price | sale_date | region | +-----------+-------------+-------------+-----------+--------+ | s1 | c1 | 100.1 | 2013 | china | | s2 | c2 | 100.2 | 2013 | china | | s5 | c2 | 100.2 | 2013 | china | +-----------+-------------+-------------+-----------+--------+ --查看分区数据 SELECT * FROM sale_detail_jt WHERE sale_date='2013' AND region='en'; +-----------+-------------+-------------+-----------+--------+ | shop_name | customer_id | total_price | sale_date | region | +-----------+-------------+-------------+-----------+--------+ | t1 | c5 | 200.0 | 2013 | en | | t2 | c6 | 300.0 | 2013 | en | +-----------+-------------+-------------+-----------+--------+ --创建物化视图 CREATE MATERIALIZED VIEW mv_deferred BUILD DEFERRED AS SELECT * FROM sale_detail_jt; --查询物化视图 mv_deferred; SELECT * FROM mv_deferred; --返回 +-----------+-------------+-------------+-----------+--------+ | shop_name | customer_id | total_price | sale_date | region | +-----------+-------------+-------------+-----------+--------+ +-----------+-------------+-------------+-----------+--------+ --创建分区表 CREATE TABLE mf_part (id bigint,name string) PARTITIONED BY (dt string); --插入数据 INSERT INTO mf_part PARTITION(dt='2013') VALUES(1,'name1'),(2,'name2'); --查询数据 SELECT * FROM mf_part WHERE dt='2013'; --返回: +------------+------+----+ | id | name | dt | +------------+------+----+ | 1 | name1 | 2013 | | 2 | name2 | 2013 | +------------+------+----+ --创建带分区的物化视图 CREATE MATERIALIZED VIEW mv_rebuild BUILD DEFERRED PARTITIONED BY (dt) AS SELECT * FROM mf_part; --查询物化视图数据 SELECT * FROM mv_rebuild WHERE dt='2013'; --返回 +------------+------+----+ | id | name | dt | +------------+------+----+ +------------+------+----+ --刷新最新分区数据 ALTER MATERIALIZED VIEW mv_rebuild REBUILD PARTITION(dt=max_pt('mf_part')); --查询物化视图数据 SELECT * FROM mv_rebuild WHERE dt='2013'; --返回 +------------+------+----+ | id | name | dt | +------------+------+----+ | 1 | name1 | 2013 | | 2 | name2 | 2013 | +------------+------+----+
修改物化视图的生命周期
修改已创建的物化视图的生命周期。
命令格式
ALTER MATERIALIZED VIEW [<project_name>.]<mv_name> SET LIFECYCLE <days>;参数说明
参数
是否必填
说明
project_name
否
物化视图所属目标MaxCompute项目名称。不填写时表示当前所在MaxCompute项目。您可以登录MaxCompute管理控制台,左上角切换地域后,即可在工作区 > 项目管理页面查看到具体的MaxCompute项目名称。
mv_name
是
待更新物化视图的名称。
days
是
设置物化视图的新生命周期。单位为天。
使用示例
--修改物化视图的生命周期为10天。 ALTER MATERIALIZED VIEW count_mv SET LIFECYCLE 10;
开启或禁用物化视图的生命周期
开启或禁用已创建的物化视图的生命周期。
命令格式
ALTER MATERIALIZED VIEW [<project_name>.]<mv_name> [<pt_spec>] enable|disable LIFECYCLE;参数说明
参数
是否必填
说明
project_name
否
物化视图所属目标MaxCompute项目名称。不填写时表示当前所在MaxCompute项目。您可以登录MaxCompute管理控制台,左上角切换地域后,即可在工作区 > 项目管理页面查看到具体的MaxCompute项目名称。
mv_name
是
待开启或禁用生命周期的物化视图的名称。
pt_spec
否
待开启或禁用生命周期的物化视图的分区。格式为
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)。partition_col是分区字段,partition_col_value是分区值。enable|disable
是
enable代表开启,disable代表禁用,禁用后该分区或表就不涉及生命周期管理。使用示例
示例一:开启物化视图的生命周期管理。
ALTER MATERIALIZED VIEW mf_mv_blank_pts PARTITION (ds='1') enable LIFECYCLE;示例二:禁用物化视图的生命周期管理。
ALTER MATERIALIZED VIEW mf_mv_blank_pts PARTITION (ds='1') disable LIFECYCLE;
查询物化视图信息
查看物化视图的结构、修改时间等信息。
命令格式
DESC EXTENDED [<project_name>.]<mv_name>;参数说明
参数
是否必填
说明
project_name
否
物化视图所属目标MaxCompute项目名称。不填写时表示当前所在MaxCompute项目。您可以登录MaxCompute管理控制台,左上角切换地域后,即可在工作区 > 项目管理页面查看到具体的MaxCompute项目名称。
mv_name
是
待查询物化视图的名称。
使用示例
DESC EXTENDED mv;返回结果如下:
说明如下结果示例需要MaxCompute客户端升级至v0.43及以上版本,详情请参见使用本地客户端(odpscmd)连接。
+------------------------------------------------------------------------------------+ | Owner: ALIYUN$$****@***.aliyunid.com | | Project: m**** | | TableComment: | +------------------------------------------------------------------------------------+ | CreateTime: 2023-05-30 13:16:07 | | LastDDLTime: 2023-05-30 13:16:07 | | LastModifiedTime: 2023-05-30 13:16:07 | +------------------------------------------------------------------------------------+ | MaterializedView: YES | | ViewText: select id,name from mf_refresh | | Rewrite Enabled: true | | AutoRefresh Enabled: true | | Refresh Interval Minutes: 10 | +------------------------------------------------------------------------------------+ | Native Columns: | +------------------------------------------------------------------------------------+ | Field | Type | Label | ExtendedLabel | Nullable | DefaultValue | Comment | +------------------------------------------------------------------------------------+ | id | bigint | | | true | NULL | | | name | string | | | true | NULL | | +------------------------------------------------------------------------------------+ | Extended Info: | +------------------------------------------------------------------------------------+ | IsOutdated: false | | TableID: 569ec712873e44b3868e79b7a8beabab | | IsArchived: false | | PhysicalSize: 1875 | | FileNum: 2 | | StoredAs: CFile | | CompressionStrategy: normal | | odps.timemachine.retention.days: 1 | | ColdStorageStatus: N/A | | encryption_enable: false | +------------------------------------------------------------------------------------+ | AutoRefresh History: | +------------------------------------------------------------------------------------+ | InstanceId | Status | StartTime | EndTime | +------------------------------------------------------------------------------------+ | 20230619070546735ghwl1****** | TERMINATED | 2023-06-19 15:05:46 | 2023-06-19 15:05:47 | | 20230619065545586gwllc****** | TERMINATED | 2023-06-19 14:55:45 | 2023-06-19 14:55:46 | | 20230619064544463gcjgom****** | TERMINATED | 2023-06-19 14:45:44 | 2023-06-19 14:45:45 | | 20230619063543334gzxs2d****** | TERMINATED | 2023-06-19 14:35:43 | 2023-06-19 14:35:44 | | 2023061906254257gi21w2****** | TERMINATED | 2023-06-19 14:25:42 | 2023-06-19 14:25:43 | | 20230619061540813giacg8****** | TERMINATED | 2023-06-19 14:15:41 | 2023-06-19 14:15:41 | | 20230619060539674gswjq9****** | TERMINATED | 2023-06-19 14:05:39 | 2023-06-19 14:05:40 | | 20230619055538578gvdjk****** | TERMINATED | 2023-06-19 13:55:38 | 2023-06-19 13:55:40 | | 20230619054537356glqdne****** | TERMINATED | 2023-06-19 13:45:37 | 2023-06-19 13:45:38 | | 2023061905353687gcc5pl****** | TERMINATED | 2023-06-19 13:35:36 | 2023-06-19 13:35:37 | +------------------------------------------------------------------------------------+
查询物化视图状态
查询物化视图状态,以便及时知晓源表变更,确保物化视图有效。物化视图状态分为如下两种:
物化视图有效
执行查询语句时,MaxCompute会从物化视图中直接查询数据,不会从源数据中查询数据。
物化视图无效
执行查询语句时,MaxCompute无法从物化视图中直接查询数据,会从源数据中查询数据,无法实现查询加速。
用户可以通过下面的函数查看物化视图的数据是否有效。
函数声明。
boolean materialized_view_is_valid(<mv_name>,<partition_value>);使用示例。
检查mf_mv_refresh4的数据是否与原表最新的数据一致,如果一致返回
true,否则返回false。SELECT materialized_view_is_valid("count_mv");SELECT materialized_view_is_valid("mf_mv_blank_pts","1");
列出项目下物化视图
列出项目下所有的物化视图,或符合某些规则的物化视图。
SHOW MATERIALIZED VIEWS命令需要在MaxCompute客户端(odpscmd)0.43.0及以上版本中执行。
命令格式
--列出项目下所有的物化视图。 SHOW MATERIALIZED VIEWS; --列出项目下名称与materialized_view匹配的物化视图。 SHOW MATERIALIZED VIEWS LIKE '<materialized_view>';使用示例
--列出项目下名称与test*匹配的物化视图名。*表示任意字段。 SHOW MATERIALIZED VIEWS LIKE 'test*';返回结果如下。
ALIYUN$account_name:test_two_mv ALIYUN$account_name:test_create_one_mv
删除物化视图
删除已创建的物化视图。
命令格式
DROP MATERIALIZED VIEW [IF EXISTS] [<project_name>.]<mv_name> [purge];参数说明
参数
是否必填
说明
IF EXISTS
否
如果没有指定IF EXISTS且物化视图不存在会返回报错。
project_name
否
物化视图所属目标MaxCompute项目名称。不填写时表示当前所在MaxCompute项目。您可以登录MaxCompute管理控制台,左上角切换地域后,即可在工作区 > 项目管理页面查看到具体的MaxCompute项目名称。
mv_name
是
待删除物化视图的名称。
purge
否
指定
purge,在删除物化视图时,直接删除数据。使用示例
删除物化视图
mv。DROP MATERIALIZED VIEW count_mv;删除物化视图
mv的同时也删除数据。DROP MATERIALIZED VIEW count_mv purge;
删除物化视图分区
删除已创建的物化视图的单个或多个分区。
命令格式
ALTER MATERIALIZED VIEW [<project_name>.]<mv_name> DROP [IF EXISTS] PARTITION <pt_spec> [PARTITION <pt_spec>, PARTITION <pt_spec>....];参数说明
参数
是否必填
说明
project_name
否
物化视图所属目标MaxCompute项目名称。不填写时表示当前所在MaxCompute项目。您可以登录MaxCompute管理控制台,左上角切换地域后,即可在工作区 > 项目管理页面查看到具体的MaxCompute项目名称。
mv_name
是
待删除分区的分区物化视图的名称。
IF EXISTS
否
如果没有指定IF EXISTS且物化视图不存在会返回报错。
pt_spec
是
至少要指定一个分区。待删除的分区。格式为
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)。partition_col是分区字段,partition_col_value是分区值。使用示例
示例一:删除分区物化视图的某个分区。命令示例如下。
ALTER MATERIALIZED VIEW mf_mv_blank_pts DROP PARTITION (ds='1');示例二:删除分区物化视图的满足指定条件的分区。命令示例如下。
ALTER MATERIALIZED VIEW mf_mv_blank_pts DROP PARTITION (ds>='1' AND ds<='2');
物化视图查询穿透
对于分区物化视图,不一定所有分区都有数据,可能只刷新了最新的一些分区数据。但用户查询数据时,实际并不知道查询的所有分区数据是否都存在,当查询的分区数据不存在时,需要自动实现到原始分区表去查询数据,流程如下图所示。
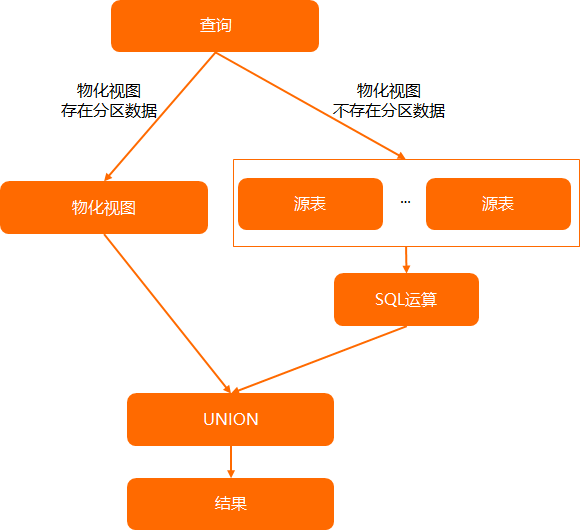
如果需要物化视图支持穿透查询能力,您需要设置如下参数:
创建物化视图时,在tblproperties属性中添加"enable_auto_substitute"="true"配置。
物化视图支持穿透查询示例如下。
创建物化视图支持分区并且支持查询穿透。
-- 创建src表。 CREATE TABLE src(id bigint,name string) PARTITIONED BY (dt string); -- 插入数据。 INSERT INTO src PARTITION(dt='20210101') VALUES(1,'Alex'); INSERT INTO src PARTITION(dt='20210102') VALUES(2,'Flink'); --创建分区物化视图支持穿透。 CREATE MATERIALIZED VIEW IF NOT EXISTS mv LIFECYCLE 7 PARTITIONED BY (dt) tblproperties("enable_auto_substitute"="true") AS SELECT id, name, dt FROM src;查询表src中的分区为20210101的数据。
SELECT * FROM mv WHERE dt='20210101';查询物化视图mv中的分区为20210102的数据,自动穿透到源表查询数据。
SELECT * FROM mv WHERE dt = '20210102'; --因为20210102的数据没有物化,则需要把查询转化到对应的源表,等价于 SELECT * FROM (SELECT id, name, dt FROM src WHERE dt='20210102') t;查询物化视图mv中分区为20201230~20210102的数据,自动穿透到源表查询的数据与物化视图的数据执行UNION操作后再返回结果。
SELECT * FROM mv WHERE dt >= '20201230' AND dt<='20210102' AND id=5; --因为20210102的数据没有物化,则需要把查询转化到对应的源表。等价于: SELECT * FROM (SELECT id, name, dt FROM src WHERE dt='20201230' OR dt='20210102' UNION ALL SELECT * FROM mv WHERE dt='20210101' ) t WHERE id = 5;
计费规则
物化视图费用包含如下两部分:
存储费用
物化视图会占用物理存储空间,产生存储费用,按量计费。更多计费信息,请参见存储费用(按量计费)。
计算费用
创建、更新、查询物化视图及查询改写(物化视图有效)过程中涉及到查询数据,会消耗计算资源产生计算费用。
当MaxCompute项目的规格类型为包年包月时,不单独收费。
当MaxCompute项目的规格类型为按量计费时,按照SQL复杂度及输入数据量计算费用。更多计费信息,请参见SQL标准计费。您需要注意如下信息:
更新物化视图执行的SQL与创建物化视图执行的SQL相同,如果该物化视图所在项目绑定的是预付费(包年包月)计算资源组,那么会使用已经购买的预付费资源,不会有额外费用;如果绑定的是后付费资源组,费用取决于执行SQL时输入的数据量和复杂度。同时刷新物化视图后会按照实际存储大小收取存储费用。
当物化视图处于生效状态时查询改写会从物化视图中读取数据,查询语句的输入数据量(从物化视图读取部分)与物化视图相关,与物化视图源表无关。当物化视图处于失效状态时不支持查询改写,查询语句会直接查询源表,查询语句的输入数据量与源表相关。更多查询物化视图状态信息,请参见查询物化视图状态。
由于多表关联生成物化视图会产生数据膨胀等原因,从物化视图读取的数据量不一定绝对小于源表,MaxCompute不能保证读取物化视图一定比读取源表节省费用。
相关文档
关于物化视图查询改写操作的相关内容,详情请参见物化视图查询改写。
关于物化视图定时更新功能的相关内容,详情请参见物化视图定时更新。