PyODPS可在DataWorks等数据开发平台中作为数据开发节点调用。这些平台提供了PyODPS运行环境和调度执行的能力,无需您手动创建ODPS入口对象。PyODPS支持类似Pandas的快速、灵活和富有表现力的数据结构。您可以通过PyODPS提供的DataFrame API使用Pandas的数据结果处理功能。本文以DataWorks平台为例,帮助您快速开始使用PyODPS,并且能够用于实际项目。
前提条件
已创建DataWorks工作空间,并绑定MaxCompute计算资源。
操作步骤
新建PyODPS节点。
为方便您快速开始,本文中使用DataWorks PyODPS节点进行开发,详情请参见开发PyODPS 3任务。
说明以PyODPS 3节点作为示例,PyODPS 3节点底层的Python版本为3.7。
PyODPS节点获取本地处理的数据量不能超过50 MB,节点运行时占用的内存不能超过1 GB,否则节点任务会被系统中止。因此请避免在PyODPS任务中写入数据量较大的Python处理代码。
在DataWorks上编写代码并进行调试效率较低,为提升运行效率,建议本地安装IDEA进行代码开发。
新建业务流程。
进入数据开发页面,右键单击业务流程,选择新建业务流程。
新建PyODPS节点。
右键单击新建的业务流程,选择,输入节点名称,单击提交。
编辑PyODPS节点。
编写程序代码。
在PyODPS节点的编辑框中输入测试代码。以下是一个完整的使用PyODPS接口执行表操作的示例,更多关于表操作以及SQL操作的方法请参见表和SQL。
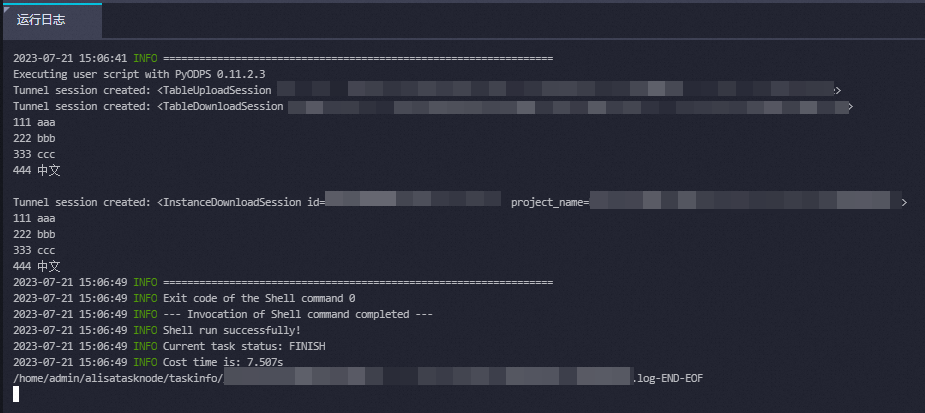
from odps import ODPS #以直接指定字段名以及字段类型的方式创建非分区表my_new_table。 #DataWorks的PyODPS节点中默认包含一个全局变量odps或者o,即为ODPS入口。您不需要手动定义ODPS入口,直接使用即可。更多信息,请参见通过DataWorks使用PyODPS。 table = o.create_table('my_new_table', 'num bigint, id string', if_not_exists=True) #向非分区表my_new_table中插入数据。 records = [[111, 'aaa'], [222, 'bbb'], [333, 'ccc'], [444, '中文']] o.write_table(table, records) #读取非分区表my_new_table中的数据。 for record in o.read_table(table): print(record[0],record[1]) #以运行SQL的方式读取表中的数据。 result = o.execute_sql('select * from my_new_table;',hints={'odps.sql.allow.fullscan': 'true'}) #读取SQL执行结果。 with result.open_reader() as reader: for record in reader: print(record[0],record[1]) #删除表以清除资源。 table.drop()运行代码。
完成编辑后,单击
 图标。运行结束后,您可以在下方的运行日志中看到运行结果。输出如下日志代表执行成功。
图标。运行结束后,您可以在下方的运行日志中看到运行结果。输出如下日志代表执行成功。