修改表操作。
适用范围
表结构变更(Schema Evolution)包括对现有表新增复杂数据类型列、删除列、修改列顺序和修改列的数据类型。在下列场景中,如果执行了更改表的列顺序、添加新列并修改列顺序或删除列这三种操作,会使表的读写行为发生变化,且存在以下限制:
作业类型是MapReduce 1.0时,Graph任务无法读写修改表。
CUPID作业只有Spark以下版本可以读表,但是不可以写表:
Spark-2.3.0-odps0.34.0
Spark-3.1.1-odps0.34.0
PAI作业可以读表,但不可以写表。
Hologres作业在1.3版本之前,Hologres引用修改的表作为外部表时,无法读写该表。
如果发生表结构变更,则不支持CLONE TABLE。
如果发生表结构变更,则使用Streaming Tunnel会报错。
修改表的所有人
修改表的所有人,即表Owner。
命令格式
ALTER TABLE <table_name> changeowner TO <new_owner>;参数说明
table_name:必填。待修改Owner的表名。
new_owner:必填。修改后的Owner账号。
使用示例
-- 将表test1的所有人修改为ALIYUN$xxx@aliyun.com。 ALTER TABLE test1 changeowner TO 'ALIYUN$xxx@aliyun.com';
修改表的注释
修改表的注释内容。
命令格式
ALTER TABLE <table_name> SET COMMENT '<new_comment>';参数说明
table_name:必填。待修改注释的表的名称。
new_comment:必填。修改后的注释内容。
使用示例
ALTER TABLE sale_detail SET COMMENT 'new comments for table sale_detail';可以通过MaxCompute的
DESC <table_name>命令查看表中COMMENT的修改结果。
修改表的修改时间
MaxCompute SQL提供touch操作,可将表的LastModifiedTime修改为当前时间。此操作会使MaxCompute认为表的数据有变动,生命周期的计算会重新开始。
命令格式
ALTER TABLE <table_name> touch;参数说明
table_name:必填。待修改表的修改时间的表名称。
使用示例
ALTER TABLE sale_detail touch;
修改表的聚簇属性
对于分区表,MaxCompute支持通过ALTER TABLE语句增加或者去除聚簇属性。
命令格式
增加表的Hash聚簇属性的语法格式如下:
ALTER TABLE <table_name> [clustered BY (<col_name> [, <col_name>, ...]) [sorted BY (<col_name> [ASC | DESC] [, <col_name> [ASC | DESC] ...])] INTO <number_of_buckets> buckets];去除表的Hash聚簇属性的语法格式如下:
ALTER TABLE <table_name> NOT clustered;增加表的Range聚簇属性,Bucket数不是必须的,可以省略,此时系统会根据数据量自动决定最佳的Bucket数目。语法格式如下:
ALTER TABLE <table_name> [RANGE clustered BY (<col_name> [, <col_name>, ...]) [sorted BY (<col_name> [ASC | DESC] [, <col_name> [ASC | DESC] ...])] INTO <number_of_buckets> buckets];去除表或分区的Range聚簇属性的语法格式如下:
ALTER TABLE <table_name> NOT clustered; ALTER TABLE <table_name> PARTITION [<pt_spec>] NOT clustered;说明通过
ALTER TABLE改变聚簇属性,只对分区表有效,非分区表一旦建立聚簇属性就无法改变。ALTER TABLE语句适用于存量表,在增加了新的聚簇属性后,新的分区将按设置的聚簇属性存储。ALTER TABLE只会影响分区表的新建分区(包括INSERT OVERWEITE生成的),新分区将按新的聚簇属性存储,老数据分区的聚簇属性和存储保持不变。即在一张曾经做过聚簇属性设置的表上,关闭了聚簇属性,再增加聚簇设置,可以在新分区设置不同于之前的聚簇列、排序列及分桶数。由于
ALTER TABLE只影响新分区,所以该语句不可以再指定分区。
参数说明
参数与CREATE TABLE一致。
使用示例
-- 创建一个分区表。 CREATE TABLE IF NOT EXISTS sale_detail( shop_name STRING, customer_id STRING, total_price DOUBLE) partitioned BY (sale_date STRING, region STRING); -- 修改表格的cluster属性。 ALTER TABLE sale_detail clustered BY (customer_id) sorted BY (customer_id) INTO 10 buckets;更多关于cluster属性的介绍请参见Hash Clustering、Range Clustering。
修改PK Delta Table表属性
命令格式
-- PK Delta Table分区表更新bucket数 ALTER TABLE <table_name> SET tblproperties("write.bucket.num"="64"); -- PK Delta Table非分区表更新bucket数,修改后存量数据会按照新bucket数重新分布 ALTER TABLE <table_name> REWRITE tblproperties("write.bucket.num"="128"); -- 更新retain属性,表示TimeTravel可查询数据历史状态的时间范围(单位为小时) ALTER TABLE <table_name> SET tblproperties("acid.data.retain.hours"="60");
重命名表
重命名表的名称。仅修改表的名字,不改动表中的数据。
命令格式
ALTER TABLE <table_name> RENAME TO <new_table_name>;参数说明
table_name:必填。待修改名称的表。
new_table_name:必填。修改后的表名称。如果已存在与new_table_name同名的表,会返回报错。
使用示例
ALTER TABLE sale_detail RENAME TO sale_detail_rename;
修改表的生命周期
修改已存在的分区表或非分区表的生命周期。
命令格式
ALTER TABLE <table_name> SET LIFECYCLE <days>;参数说明
table_name:必填。需要修改生命周期的表名。
days:必填。修改后的生命周期时间,只能为正整数,单位为天。
使用示例
-- 修改sale_detail_rename表,将生命周期设为50天。 ALTER TABLE sale_detail_rename SET LIFECYCLE 50;
禁止或恢复生命周期
禁止或恢复指定表或分区的生命周期。
命令格式
ALTER TABLE <table_name> PARTITION [<pt_spec>] {enable|disable} LIFECYCLE;参数说明
table_name:必填。待禁止或恢复生命周期的表的名称。
pt_spec:可选。待禁止或恢复生命周期的表的分区信息。格式为
partition_col1=col1_value1, partition_col2=col2_value1...。对于有多级分区的表,必须指明全部的分区值。enable:恢复表或指定分区的生命周期功能。
表及其分区重新参与生命周期回收,默认使用当前表及分区上的生命周期配置。
开启表生命周期前可以修改表及分区的生命周期配置,防止开启表生命周期后因使用之前的配置导致数据被误回收。
disable:禁止表或指定分区的生命周期功能。
禁止表本身及其所有分区被生命周期回收,优先级高于恢复表分区生命周期。即当使用
table disable LIFECYCLE时,pt_spec enable LIFECYCLE设置无效。禁止表的生命周期功能后,表的生命周期配置及其分区的enable和disable标记会被保留。
禁止表的生命周期功能后,仍然可以修改表及分区的生命周期配置。
使用示例
示例1:禁止表sale_detail_rename的生命周期功能。
ALTER TABLE sale_detail_rename disable LIFECYCLE;示例2:禁止表sale_detail_rename中时间为201912分区的生命周期功能。
-- 插入测试数据 ALTER TABLE sale_detail_rename ADD IF NOT EXISTS PARTITION (sale_date= '201910',region = 'shanghai') PARTITION (sale_date= '201911',region = 'shanghai') PARTITION (sale_date= '201912',region = 'shanghai') PARTITION (sale_date= '202001',region = 'shanghai') PARTITION (sale_date= '202002',region = 'shanghai') PARTITION (sale_date= '201910',region = 'beijing') PARTITION (sale_date= '201911',region = 'beijing') PARTITION (sale_date= '201912',region = 'beijing') PARTITION (sale_date= '202001',region = 'beijing') PARTITION (sale_date= '202002',region = 'beijing'); ALTER TABLE sale_detail_rename PARTITION (sale_date= '201912',region='shanghai') disable LIFECYCLE;
添加分区
为已存在的分区表新增分区。
限制条件
对于有多级分区的表,如果需要添加新的分区值,必须指明全部的分区。
仅支持新增分区值,不支持新增分区字段。
命令格式
ALTER TABLE <table_name> ADD [IF NOT EXISTS] PARTITION <pt_spec> [PARTITION <pt_spec> PARTITION <pt_spec>...];参数说明
参数
是否必填
说明
table_name
是
待新增分区的分区表名称。
IF NOT EXISTS
否
如果未指定IF NOT EXISTS而同名的分区已存在,会执行失败并返回报错。
pt_spec
是
新增的分区,格式为:
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)。其中partition_col是分区字段,partition_col_value是分区值。分区字段不区分大小写,分区值区分大小写。使用示例
创建普通分区表
sale_detail,创建和删除表,详情请参见创建和删除表。CREATE TABLE IF NOT EXISTS sale_detail( shop_name STRING, customer_id STRING, total_price DOUBLE) PARTITIONED BY (sale_date STRING, region STRING);示例1:给表
sale_detail添加一个分区,用来存储2025年12月杭州地区的销售记录。ALTER TABLE sale_detail ADD IF NOT EXISTS PARTITION (sale_date='202512', region='hangzhou');示例2:给表
sale_detail同时添加两个分区,用来存储2025年12月北京和上海地区的销售记录。ALTER TABLE sale_detail ADD IF NOT EXISTS PARTITION (sale_date='202512', region='beijing') PARTITION (sale_date='202512', region='shanghai');示例3:给表
sale_detail添加分区,仅指定一个分区字段sale_date,返回报错,需要同时指定2个分区字段sale_date和region。ALTER TABLE sale_detail ADD IF NOT EXISTS PARTITION (sale_date='20260111'); -- 错误信息如下: FAILED: ODPS-0130071:[1,58] Semantic analysis exception - provided partition spec does not match table partition spec示例4:增加Delta Table表分区
-- 创建Delta Table表 CREATE TABLE delta_table_test_par ( pk BIGINT NOT NULL PRIMARY KEY, val BIGINT NOT NULL) PARTITIONED BY (dd STRING, hh STRING) TBLPROPERTIES ("transactional"="true"); -- 添加分区 ALTER TABLE delta_table_test_par ADD PARTITION (dd='01', hh='01'); CREATE TABLE delta_table_test_nonpar ( pk BIGINT NOT NULL PRIMARY KEY, val BIGINT NOT NULL) TBLPROPERTIES ("transactional"="true");示例5:修改PK Delta Table表属性
-- PK Delta Table分区表更新bucket数。 ALTER TABLE delta_table_test_par SET tblproperties("write.bucket.num"="64"); -- PK Delta Table非分区表更新bucket数,修改后存量数据会按照新bucket数重新分布。 ALTER TABLE delta_table_test_nonpar REWRITE tblproperties("write.bucket.num"="128"); -- 更新retain属性,表示TimeTravel可查询数据历史状态的时间范围(单位为小时)。 ALTER TABLE delta_table_test_par SET tblproperties("acid.data.retain.hours"="60");
修改分区的更新时间
MaxCompute SQL提供touch操作,用于修改分区表中分区的LastModifiedTime。此操作会将LastModifiedTime修改为当前时间。此时,MaxCompute会认为数据有变动,重新计算生命周期。
使用限制
对于有多级分区的表,必须指明全部的分区。
命令格式
ALTER TABLE <table_name> touch PARTITION (<pt_spec>);参数说明
参数
是否必填
说明
table_name
是
待修改分区更新时间的分区表名称。如果表不存在,则返回报错。
pt_spec
是
需要修改更新时间的分区信息。格式为:
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)。其中partition_col是分区字段,partition_col_value是分区值。如果指定的分区字段或分区值不存在,则返回报错。使用示例
-- 修改表sale_detail的分区sale_date='202512', region='shanghai'的LastModifiedTime。 ALTER TABLE sale_detail touch PARTITION (sale_date='202512', region='shanghai');
修改分区值
MaxCompute SQL支持通过rename操作更改分区表的分区值。
使用限制
不支持修改分区列的列名,只能修改分区列对应的值。
对于有多级分区的表,必须指明全部的分区。
命令格式
ALTER TABLE <table_name> PARTITION (<pt_spec>) rename TO PARTITION (<new_pt_spec>);参数说明
参数
是否必填
说明
table_name
是
待修改分区值的表名称。
pt_spec
是
需要修改分区值的分区信息。格式为:
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)。其中partition_col是分区字段,partition_col_value是分区值。如果指定的分区字段或分区值不存在,则返回报错。new_pt_spec
是
修改后的分区信息。格式为:
(partition_col1 = new_partition_col_value1, partition_col2 = new_partition_col_value2, ...)。其中partition_col是分区字段,new_partition_col_value是新分区值。使用示例
-- 修改表sale_detail的分区值。 ALTER TABLE sale_detail PARTITION (sale_date = '201312', region = 'hangzhou') rename TO PARTITION (sale_date = '201310', region = 'beijing');
合并分区
MaxCompute SQL提供merge partition合并分区表的分区,即将同一个分区表下的多个分区合并成一个分区,同时删除被合并的分区维度的信息,把数据移动到指定分区。
使用限制
不支持外部表,聚簇表合并后的分区会消除聚簇属性。
一次性合并分区数量限制为4000个。
命令格式
ALTER TABLE <table_name> MERGE [IF EXISTS] PARTITION (<predicate>) [, PARTITION(<predicate2>) ...] overwrite PARTITION (<fullpartitionSpec>) [purge];参数说明
参数
是否必填
说明
table_name
是
待合并分区的分区表名称。
IF EXISTS
否
如果未指定IF EXISTS,且分区不存在,会执行失败并返回报错。如果指定IF EXISTS后不存在满足
merge条件的分区,则不生成新分区。如果运行过程中出现源数据被并发修改(包括insert、rename或drop)时,即使指定IF EXISTS也会报错。predicate
是
筛选待合并分区需要满足的条件。
fullpartitionSpec
是
目标分区信息。
purge
否
可选关键字。选择该字段,则会清理session目录,默认清理3天内的日志。详情请参见Purge。
使用示例
示例1:合并满足指定条件的分区到目标分区。
-- 查看分区表的分区。 SHOW PARTITIONS sale_detail; -- 示例返回结果: sale_date=202512/region=beijing sale_date=202512/region=shanghai sale_date=202602/region=beijin --合并所有满足sale_date='201512'的分区到sale_date='202601',region='hangzhou'中。 ALTER TABLE sale_detail MERGE PARTITION(sale_date='202512') overwrite PARTITION(sale_date='202601', region='hangzhou'); --查看合并后的分区。 SHOW PARTITIONS sale_detail; -- 示例返回结果: sale_date=202601/region=hangzhou sale_date=202602/region=beijing示例2:合并指定的多个分区到目标分区。
-- 合并多个指定分区。 ALTER TABLE sale_detail MERGE IF EXISTS PARTITION(sale_date='202601', region='hangzhou'), PARTITION(sale_date='202602', region='beijing') overwrite PARTITION(sale_date='202603', region='shanghai') purge; -- 查看分区表的分区。 SHOW PARTITIONS sale_detail; -- 示例返回结果: sale_date=202603/region=shanghai
删除分区
为已存在的分区表删除分区。
MaxCompute支持通过条件筛选方式删除分区。如果希望一次性删除符合某个规则条件的多个分区,可以使用表达式指定筛选条件,通过筛选条件匹配分区并批量删除分区。
限制条件
每个分区过滤子句只能访问一个分区列。
表达式用到的函数必须是内建的Scalar函数。
注意事项
删除分区之后,MaxCompute项目的存储量会降低。
结合MaxCompute提供的生命周期功能,能够实现自动回收旧分区。
命令格式
未指定筛选条件
-- 一次删除一个分区。 ALTER TABLE <table_name> DROP [IF EXISTS] PARTITION <pt_spec>; -- 一次删除多个分区。 ALTER TABLE <table_name> DROP [IF EXISTS] PARTITION <pt_spec>,PARTITION <pt_spec>[,PARTITION <pt_spec>....];指定筛选条件
ALTER TABLE <table_name> DROP [IF EXISTS] PARTITION <partition_filtercondition>;
参数说明
参数
是否必填
说明
table_name
是
待删除分区的分区表名称。
IF EXISTS
否
如果未指定IF EXISTS且分区不存在,则返回报错。
pt_spec
是
删除的分区。格式为:
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)。其中partition_col是分区字段,partition_col_value是分区值。分区字段不区分大小写,分区值区分大小写。partition_filtercondition
否
指定筛选条件时必填。分区筛选条件,不区分大小写。格式如下:
partition_filtercondition : PARTITION (<partition_col> <relational_operators> <partition_col_value>) | PARTITION (scalar(<partition_col>) <relational_operators> <partition_col_value>) | PARTITION (<partition_filtercondition1> AND|OR <partition_filtercondition2>) | PARTITION (NOT <partition_filtercondition>) | PARTITION (<partition_filtercondition1>)[,PARTITION (<partition_filtercondition2>), ...]介绍如下:
partition_col:分区名称。
relational_operators:关系运算符,详情请参见运算符。
partition_col_value:分区列比较值或正则表达式,与分区列数据类型保持一致。
scalar():Scalar函数。Scalar函数基于输入值生成对应的标量,对分区列的值(partition_col)进行处理后再按照指定的关系运算符relational_operators与partition_col_value做比较。
分区过滤条件支持逻辑运算符NOT、AND和OR。支持通过NOT过滤条件子句,取过滤规则的补集。支持多个过滤条件子句以AND或OR的关系组成整体分区匹配规则。
支持多个分区过滤子句,当多个分区过滤子句以英文逗号(,)分隔时,每个过滤子句的逻辑以OR的关系组成整体分区匹配规则。
使用示例
未指定筛选条件
-- 从表sale_detail中删除一个分区,2026年3月上海分区的销售记录。 ALTER TABLE sale_detail DROP IF EXISTS PARTITION(sale_date='202603',region='shanghai'); -- 从表sale_detail中同时删除两个分区,2024年12月杭州和上海分区的销售记录。 ALTER TABLE sale_detail DROP IF EXISTS PARTITION(sale_date='202412',region='hangzhou'),PARTITION(sale_date='202412',region='shanghai');指定筛选条件
分区表
-- 创建分区表 CREATE TABLE IF NOT EXISTS sale_detail_del( shop_name STRING, customer_id STRING, total_price DOUBLE) partitioned BY (sale_date STRING); -- 添加分区 ALTER TABLE sale_detail_del ADD if NOT EXISTS PARTITION (sale_date= '201910') PARTITION (sale_date= '201911') PARTITION (sale_date= '201912') PARTITION (sale_date= '202001') PARTITION (sale_date= '202002') PARTITION (sale_date= '202003') PARTITION (sale_date= '202004') PARTITION (sale_date= '202005') PARTITION (sale_date= '202006') PARTITION (sale_date= '202007'); -- 批量删除分区 ALTER TABLE sale_detail_del DROP IF EXISTS PARTITION(sale_date < '201911'); ALTER TABLE sale_detail_del DROP IF EXISTS PARTITION(sale_date >= '202007'); ALTER TABLE sale_detail_del DROP IF EXISTS PARTITION(sale_date LIKE '20191%'); ALTER TABLE sale_detail_del DROP IF EXISTS PARTITION(sale_date IN ('202002','202004','202006')); ALTER TABLE sale_detail_del DROP IF EXISTS PARTITION(sale_date BETWEEN '202001' AND '202007'); ALTER TABLE sale_detail_del DROP IF EXISTS PARTITION(substr(sale_date, 1, 4) = '2020'); ALTER TABLE sale_detail_del DROP IF EXISTS PARTITION(sale_date < '201912' OR sale_date >= '202006'); ALTER TABLE sale_detail_del DROP IF EXISTS PARTITION(sale_date > '201912' AND sale_date <= '202004'); ALTER TABLE sale_detail_del DROP IF EXISTS PARTITION(NOT sale_date > '202004'); -- 支持多个分区过滤表达式,表达式之间是OR的关系 ALTER TABLE sale_detail_del DROP IF EXISTS PARTITION(sale_date < '201911'), PARTITION(sale_date >= '202007'); -- 添加其他格式分区 ALTER TABLE sale_detail_del ADD IF NOT EXISTS PARTITION (sale_date= '2019-10-05') PARTITION (sale_date= '2019-10-06') PARTITION (sale_date= '2019-10-07'); -- 批量删除分区,使用正则表达式匹配分区。 ALTER TABLE sale_detail_del DROP IF EXISTS PARTITION(sale_date RLIKE '2019-\\d+-\\d+');多级分区表
-- 创建多级分区表 CREATE TABLE IF NOT EXISTS region_sale_detail( shop_name STRING, customer_id STRING, total_price DOUBLE) partitioned BY (sale_date STRING , region STRING ); -- 添加分区 ALTER TABLE region_sale_detail ADD IF NOT EXISTS PARTITION (sale_date= '201910',region = 'shanghai') PARTITION (sale_date= '201911',region = 'shanghai') PARTITION (sale_date= '201912',region = 'shanghai') PARTITION (sale_date= '202001',region = 'shanghai') PARTITION (sale_date= '202002',region = 'shanghai') PARTITION (sale_date= '201910',region = 'beijing') PARTITION (sale_date= '201911',region = 'beijing') PARTITION (sale_date= '201912',region = 'beijing') PARTITION (sale_date= '202001',region = 'beijing') PARTITION (sale_date= '202002',region = 'beijing'); -- 执行如下语句批量删除多级分区,两个匹配条件是或的关系,会将sale_date小于201911或region等于beijing的分区都删除掉。 ALTER TABLE region_sale_detail DROP IF EXISTS PARTITION(sale_date < '201911'),PARTITION(region = 'beijing'); -- 如果删除sale_date小于201911且region等于beijing的分区,可以使用如下方法。 ALTER TABLE region_sale_detail DROP IF EXISTS PARTITION(sale_date < '201911', region = 'beijing');批量删除多级分区时,在一个
partition过滤子句中,不能根据多个分区列编写组合条件匹配分区,如下语句会报错FAILED: ODPS-0130071:[1,82] Semantic analysis exception - invalid column reference region, partition expression must have one and only one column reference。-- 分区过滤子句只能访问一个分区列,如下语句报错。 ALTER TABLE region_sale_detail DROP IF EXISTS PARTITION(sale_date < '201911' AND region = 'beijing');
添加列或注释
为已存在的非分区表或分区表添加列或注释,请注意表结构变更适用范围。MaxCompute已支持添加STRUCT类型的列,例如STRUCT<x: STRING, y: BIGINT>、MAP<STRING, STRUCT<x: DOUBLE, y: DOUBLE>>。
参数设置
设置参数
setproject odps.schema.evolution.enable=true;开通功能。权限要求:该参数为项目空间的Project级属性,需操作账号为项目的Owner或者账号被赋予了项目级别的Super_Administrator或Admin角色,操作详情请参见为用户赋予内置管理角色。
生效时间:修改该参数需要等待10分钟后才会生效。
命令格式
ALTER TABLE <table_name> ADD COLUMNS [IF NOT EXISTS] (<col_name1> <type1> COMMENT ['<col_comment>'] [, <col_name2> <type2> COMMENT '<col_comment>'...] );参数说明
参数
是否必填
说明
table_name
是
待新增列的表名称。添加的新列不支持指定顺序,默认在最后一列。
col_name
是
新增列的名称。
type
是
新增列的数据类型。
col_comment
否
新增列的注释。
使用示例
示例1:给表sale_detail添加两个列。
ALTER TABLE sale_detail ADD COLUMNS IF NOT EXISTS(customer_name STRING, education BIGINT);示例2:给表sale_detail添加两个列并同时添加列注释。
ALTER TABLE sale_detail ADD COLUMNS (customer_name STRING COMMENT '客户', education BIGINT COMMENT '教育' );示例3:给表sale_detail添加一个复杂数据类型列。
ALTER TABLE sale_detail ADD COLUMNS (region_info struct<province:string, area:string>);示例4:给表sale_detail增加ID列SQL会返回成功,但实际并不会重复增加。
-- 返回成功,但实际并不会重复增加ID列。 ALTER TABLE sale_detail ADD COLUMNS IF NOT EXISTS(id bigint);示例5:增加Delta Table的列。
CREATE TABLE delta_table_test (pk BIGINT NOT NULL PRIMARY KEY, val BIGINT) TBLPROPERTIES ("transactional"="true"); ALTER TABLE delta_table_test ADD COLUMNS (val2 bigint);
删除列
为已存在的非分区表或分区表删除指定的单个或多个列,请注意表结构变更适用范围。
参数设置
设置参数
setproject odps.schema.evolution.enable=true;开通功能。权限要求:该参数为项目空间的Project级属性,需操作账号为项目的Owner或者账号被赋予了项目级别的Super_Administrator或Admin角色,操作详情请参见为用户赋予内置管理角色。
生效时间:修改该参数需要等待10分钟后才会生效。
命令格式
-- 删除单个列。 ALTER TABLE <table_name> DROP COLUMN <col_name>; -- 删除多列。 ALTER TABLE <table_name> DROP COLUMNS <col_name1>[, <col_name2>...];参数说明
table_name:必填。待删除列的表名称。
col_name:必填。待删除的列名称。
使用示例
-- 示例1:删除表sale_detail的单个列customer_id ALTER TABLE sale_detail DROP COLUMNS customer_id; -- 示例2:删除表sale_detail的多个列shop_name和total_price ALTER TABLE sale_detail DROP COLUMNS shop_name, total_price;
更改列数据类型
为已存在的列更改数据类型,请注意表结构变更适用范围。
参数设置
设置参数
setproject odps.schema.evolution.enable=true;开通功能。权限要求:该参数为项目空间的Project级属性,需操作账号为项目的Owner或者账号被赋予了项目级别的Super_Administrator或Admin角色,操作详情请参见为用户赋予内置管理角色。
生效时间:修改该参数需要等待10分钟后才会生效。
命令格式
ALTER TABLE <table_name> CHANGE [COLUMN] <old_column_name> <new_column_name> <new_data_type>;参数说明
参数
是否必填
说明
table_name
是
待修改列数据类型的表名称。
old_column_name
是
待修改列数据类型的列名称。
new_column_name
是
修改列数据类型后的列名称。
old_column_name可以与new_column_name保持一致,表示不修改列名称。但是new_column_name不能与除old_column_name之外的列名称相同。
new_data_type
是
待修改的列修改后的数据类型。
使用示例
-- 将sale_detail表的id字段类型由BIGINT转化为STRING。 ALTER TABLE sale_detail CHANGE COLUMN id id STRING;数据类型支持转换表
说明Y表示支持转换;N表示不支持转换;-表示不涉及;Y()表示满足括号内的条件支持转换。
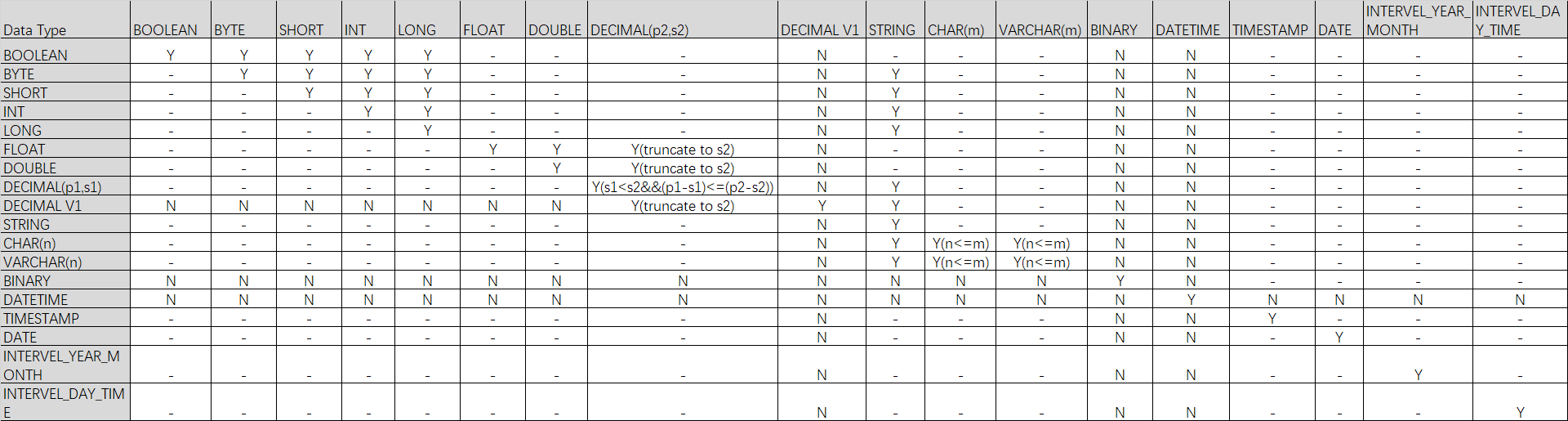
修改列的顺序
为已存在的非分区表或分区表修改列顺序,请注意表结构变更适用范围。
参数设置
设置参数
setproject odps.schema.evolution.enable=true;开通功能。权限要求:该参数为项目空间的Project级属性,需操作账号为项目的Owner或者账号被赋予了项目级别的Super_Administrator或Admin角色,操作详情请参见为用户赋予内置管理角色。
生效时间:修改该参数需要等待10分钟后才会生效。
命令格式
ALTER TABLE <table_name> CHANGE <old_column_name> <new_column_name> <column_type> AFTER <column_name>;参数说明
参数
是否必填
说明
table_name
是
待修改列顺序的表名称。
old_column_name
是
待修改顺序的列的原始名称。
new_col_name
是
修改后的列名称。
new_col_name可以与old_column_name保持一致,表示不修改列名称。但new_col_name不能与除old_column_name的之外的列名称相同。
column_type
是
待修改的列的原始数据类型。不可修改。
column_name
是
将待调整顺序的列调整至column_name之后。
使用示例
-- 将表sale_detail的列customer修改为customer_id并位于total_price之后。 ALTER TABLE sale_detail CHANGE customer customer_id STRING AFTER total_price; -- 修改表sale_detail的列customer_id位于total_price之后,不修改列名称。 ALTER TABLE sale_detail CHANGE customer_id customer_id STRING AFTER total_price;
修改列名
为已存在的非分区表或分区表修改列名称。
命令格式
ALTER TABLE <table_name> CHANGE COLUMN <old_col_name> RENAME TO <new_col_name>;参数说明
参数
是否必填
说明
table_name
是
待修改列名的表名称。
old_col_name
是
待修改的列名称。必须是已存在的列。
new_col_name
是
修改后的列名称,列名称不能重复。
使用示例
-- 修改表sale_detail的列名customer_name为customer。 ALTER TABLE sale_detail CHANGE COLUMN customer_name RENAME TO customer;
修改列注释
为已存在的非分区表或分区表修改列注释。
语法格式
ALTER TABLE <table_name> CHANGE COLUMN <col_name> COMMENT '<col_comment>';参数说明
参数
是否必填
说明
table_name
是
待修改列注释的表名称。
col_name
是
待修改注释的列名称。必须是已存在的列。
col_comment
是
修改后的注释信息。注释内容为长度不超过1024字节的有效字符串,否则报错。
使用示例
-- 修改表sale_detail的列customer的注释。 ALTER TABLE sale_detail0113 CHANGE COLUMN customer COMMENT 'customer';
修改列名及注释
修改非分区表或分区表的列名或注释。
命令格式
ALTER TABLE <table_name> CHANGE COLUMN <old_col_name> <new_col_name> <column_type> COMMENT '<col_comment>';参数说明
参数
是否必填
说明
table_name
是
需要修改列名以及注释的表名称。
old_col_name
是
需要修改的列名称。必须是已存在的列。
new_col_name
是
新的列名称,列名称不能重复。
column_type
是
列的数据类型。
col_comment
可选
修改后的注释信息,内容最长为1024字节。
使用示例
-- 修改表sale_detail的列名customer为customer_newname,注释“客户”为“customer”。 ALTER TABLE sale_detail CHANGE COLUMN customer customer_newname STRING COMMENT 'customer';
修改表的列非空属性
修改表的非分区列的非空属性。即如果表的非分区列值禁止为NULL,可以通过本命令修改分区列值允许为NULL。
修改分区列值允许为NULL后,不可回退,不支持再修改分区列值禁止为NULL,请谨慎操作。
通过
DESC EXTENDED table_name;命令查看Nullable属性值,判断列的非空属性:如果
Nullable为true,表示允许为NULL;如果
Nullable为false,表示禁止为NULL。
命令格式
ALTER TABLE <table_name> CHANGE COLUMN <old_col_name> NULL;参数说明
参数
是否必填
说明
table_name
是
待修改列非空属性的表名称。
old_col_name
是
待修改的非分区列的名称。必须是已存在的非分区列。
使用示例
-- 创建一张分区表,id列禁止为NULL。 CREATE TABLE null_test(id INT NOT NULL, name STRING) PARTITIONED BY (ds string); -- 查看表属性 DESC EXTENDED null_test; -- 返回结果如下: +------------------------------------------------------------------------------------+ | Native Columns: | +------------------------------------------------------------------------------------+ | Field | Type | Label | ExtendedLabel | Nullable | DefaultValue | Comment | +------------------------------------------------------------------------------------+ | id | int | | | false | NULL | | | name | string | | | true | NULL | | +------------------------------------------------------------------------------------+ | Partition Columns: | +------------------------------------------------------------------------------------+ | ds | string | | +------------------------------------------------------------------------------------+ -- 修改id列允许为NULL。 ALTER TABLE null_test CHANGE COLUMN id NULL; -- 查看表属性 DESC EXTENDED null_test; -- 返回结果如下: +------------------------------------------------------------------------------------+ | Native Columns: | +------------------------------------------------------------------------------------+ | Field | Type | Label | ExtendedLabel | Nullable | DefaultValue | Comment | +------------------------------------------------------------------------------------+ | id | int | | | true | NULL | | | name | string | | | true | NULL | | +------------------------------------------------------------------------------------+ | Partition Columns: | +------------------------------------------------------------------------------------+ | ds | string | | +------------------------------------------------------------------------------------+
合并Transactional表文件
Transactional表底层物理存储为不支持直接读取的Base文件和Delta文件。对Transactional表执行update或delete操作时,只会追加Delta文件,不会修改Base文件。因此,更新或删除次数越多,表的存储占用越大,查询费用也会增加。
对同一表或分区,执行多次update或delete操作,会生成较多Delta文件。系统读数据时,需要加载这些Delta文件来确定哪些行被更新或删除,较多的Delta文件会影响数据读取效率。此时您可以将Base文件和Delta合并,减少存储以便提升数据读取效率。
命令格式
ALTER TABLE <table_name> [PARTITION (<partition_key> = '<partition_value>' [, ...])] compact {minor|major};参数说明
table_name:必填。待合并文件的Transactional表名称。
partition_key:可选。当Transactional表为分区表时,指定分区列名。
partition_value:可选。当Transactional表为分区表时,指定分区列名对应的列值。
major|minor:至少选择其中一个。二者的区别是:
minor:只将Base文件及其下所有的Delta文件合并,消除Delta文件。major:不仅将Base文件及其下所有的Delta文件合并,消除Delta文件,还会把表对应的Base文件中的小文件进行合并。当Base文件较小(小于32 MB)或有Delta文件的情况下,等价于重新对表执行insert overwrite操作,但当Base文件足够大(大于等于32 MB ),且不存在Delta文件的情况下,不会重写。
使用示例
示例1:基于Transactional表acid_delete,合并表文件。命令示例如下:
ALTER TABLE acid_delete compact minor;返回结果如下:
Summary: Nothing found to merge, set odps.merge.cross.paths=true IF cross path merge is permitted. OK示例2:基于Transactional表acid_update_pt,合并表文件。命令示例如下:
ALTER TABLE acid_update_pt PARTITION (ds = '2019') compact major;返回结果如下:
Summary: table name: acid_update_pt /ds=2019 instance count: 2 run time: 6 before merge, file count: 8 file size: 2613 file physical size: 7839 after merge, file count: 2 file size: 679 file physical size: 2037 OK
合并小文件
分布式文件系统按块Block存放,文件大小比块大小(64 M)小的文件称之为小文件。分布式系统不可避免会产生小文件,比如SQL或其他分布式引擎计算结果,tunnel数据采集都会产生小文件,小文件合并可以提高计算性能。
命令格式
ALTER TABLE <tablename> [PARTITION(<partition_key>=<partition_value>)] MERGE SMALLFILES;参数说明
table_name:必填。待合并文件的表名称。
partition_key:可选。当表为分区表时,指定分区列名。
partition_value:可选。当表为分区表时,指定分区列名对应的列值。
使用示例
SET odps.merge.cross.paths=true; SET odps.merge.smallfile.filesize.threshold=128; SET odps.merge.max.filenumber.per.instance = 2000; ALTER TABLE tbcdm.dwd_tb_log_pv_di PARTITION (ds='20151116') MERGE smallfiles;
使用合并小文件功能需要用到计算资源,如果您购买的实例是按量计费,会产生相关费用,具体计费规则与SQL按量计费保持一致,详情请参见计算费用(按量付费)。
更多详情,请参见合并小文件。
相关命令
CREATE TABLE:创建非分区表、分区表、外部表或聚簇表。
TRUNCATE:将指定表中的数据清空。
DROP TABLE:删除分区表或非分区表。
DESC TABLE/VIEW:查看MaxCompute内部表、视图、物化视图、外部表、聚簇表或Transactional表的信息。
SHOW:查看表的SQL DDL语句、列出项目下所有的表和视图或列出一张表中的所有分区。\