本文将为您介绍Aggregator的执行机制、相关API,并以Kmeans Clustering为例说明Aggregator的具体用法。
Aggregator是MaxCompute Graph作业中常用的特征,特别适用于解决机器学习问题。MaxCompute Graph中,Aggregator用于汇总并处理全局信息。
Aggregator机制
Aggregator的逻辑分为两部分:
一部分在所有Worker上执行,即分布式执行。
一部分只在Aggregator Owner所在的Worker上执行,即单点执行。
其中,在所有Worker上执行的操作包括创建初始值及局部聚合,然后将局部聚合结果发送给Aggregator Owner所在的Worker上。Aggregator Owner所在的Worker上聚合普通Worker发送过来的局部聚合对象,得到全局聚合结果,然后判断迭代是否结束。全局聚合的结果会在下一轮超步(迭代)分发给所有Worker,供下一轮迭代使用。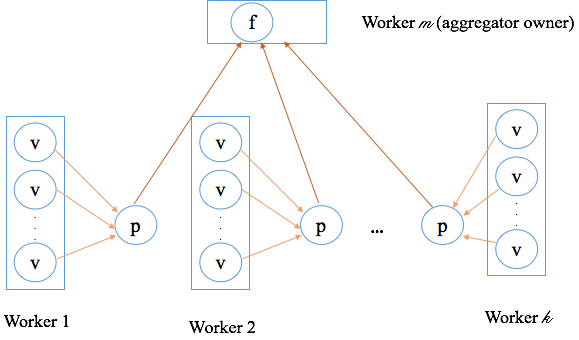
Aggregator的基本流程如下:
每个Worker启动时执行createStartupValue用于创建AggregatorValue。
每轮迭代开始前,每个Worker执行createInitialValue来初始化本轮的AggregatorValue。
一轮迭代中每个点通过
context.aggregate()来执行aggregate()实现Worker内的局部迭代。每个Worker将局部迭代结果发送给AggregatorOwner所在的Worker。
AggregatorOwner所在Worker执行多次
merge,实现全局聚合。AggregatorOwner所在Worker执行
terminate用于处理全局聚合结果,并决定是否结束迭代。
Aggregator的API
Aggregator共提供了5个API供您实现。API的调用时机及常规用途如下:
createStartupValue(context)
该API在所有Worker上执行一次,调用时机是所有超步开始之前,通常用于初始化
AggregatorValue。在第0轮超步中,调用WorkerContext.getLastAggregatedValue()或ComputeContext.getLastAggregatedValue()可以获取该API初始化的AggregatorValue对象。createInitialValue(context)
该API在所有Worker上每轮超步开始时调用一次,用于初始化本轮迭代所用的
AggregatorValue。通常操作是通过WorkerContext.getLastAggregatedValue()得到上一轮迭代的结果,然后执行部分初始化操作。aggregate(value, item)
该API同样在所有Worker上执行,与上述API不同的是,该API由用户显示调用
ComputeContext#aggregate(item)来触发,而上述两个API由框架自动调用。该API用于执行局部聚合操作,其中第一个参数value是本Worker在该轮超步已经聚合的结果(初始值是createInitialValue返回的对象),第二个参数是您的代码调用ComputeContext#aggregate(item)传入的参数。该API中通常用item来更新value实现聚合。所有aggregate执行完后,得到的value就是该Worker的局部聚合结果,然后由框架发送给Aggregator Owner所在的Worker。merge(value, partial)
该API执行于Aggregator Owner所在Worker,用于合并各Worker局部聚合的结果,达到全局聚合对象。与
aggregate类似,value是已经聚合的结果,而partial待聚合的对象,同样用partial更新value。假设有3个Worker,分别是w0、w1、w2,其局部聚合结果是p0、p1、p2。例如,发送到Aggregator Owner所在Worker的顺序为p1、p0、p2,则
merge执行次序为:首先执行
merge(p1, p0),这样p1和p0就聚合为p1。然后执行
merge(p1, p2),p1和p2聚合为p1,而p1即为本轮超步全局聚合的结果。
由上述示例可见,当只有一个Worker时,不需要执行
merge方法,即merge()不会被调用。terminate(context, value)
当Aggregator Owner所在Worker执行完
merge()后,框架会调用terminate(context, value)执行最后的处理。其中第二个参数value,即为merge()最后得到全局聚合,在该方法中可以对全局聚合继续修改。执行完terminate()后,框架会将全局聚合对象分发给所有Worker,供下一轮超步使用。terminate()方法的一个特殊之处在于,如果返回True,则整个作业就结束迭代,否则继续执行。在机器学习场景中,通常判断收敛后返回True以结束作业。
Kmeans Clustering示例
下面以典型的Kmeans Clustering为例,为您介绍Aggregator的具体用法。
完整代码请参见Kmeans,此处为解析代码。
GraphLoader部分
GraphLoader部分用于加载输入表,并转换为图的点或边。这里我们输入表的每行数据为一个样本,一个样本构造一个点,并用Vertex的Value来存放样本。
首先定义一个Writable类
KmeansValue作为Vertex的value类型。public static class KmeansValue implements Writable { DenseVector sample; public KmeansValue() { } public KmeansValue(DenseVector v) { this.sample = v; } @Override public void write(DataOutput out) throws IOException { wirteForDenseVector(out, sample); } @Override public void readFields(DataInput in) throws IOException { sample = readFieldsForDenseVector(in); } }KmeansValue中封装一个DenseVector对象来存放一个样本,这里DenseVector类型来自matrix-toolkits-java,而wirteForDenseVector()及readFieldsForDenseVector()用于实现序列化及反序列化。自定义的
KmeansReader代码,如下所示。public static class KmeansReader extends GraphLoader<LongWritable, KmeansValue, NullWritable, NullWritable> { @Override public void load( LongWritable recordNum, WritableRecord record, MutationContext<LongWritable, KmeansValue, NullWritable, NullWritable> context) throws IOException { KmeansVertex v = new KmeansVertex(); v.setId(recordNum); int n = record.size(); DenseVector dv = new DenseVector(n); for (int i = 0; i < n; i++) { dv.set(i, ((DoubleWritable)record.get(i)).get()); } v.setValue(new KmeansValue(dv)); context.addVertexRequest(v); } }KmeansReader中,每读入一行数据创建一个点,这里用recordNum作为点的ID,将record内容转换成DenseVector对象并封装进VertexValue中。Vertex部分
自定义的
KmeansVertex代码如下。逻辑非常简单,每轮迭代要做的事情就是将自己维护的样本执行局部聚合。具体逻辑参见下面Aggregator的实现。public static class KmeansVertex extends Vertex<LongWritable, KmeansValue, NullWritable, NullWritable> { @Override public void compute( ComputeContext<LongWritable, KmeansValue, NullWritable, NullWritable> context, Iterable<NullWritable> messages) throws IOException { context.aggregate(getValue()); } }Aggregator部分
整个Kmeans的主要逻辑集中在Aggregator中。首先是自定义的
KmeansAggrValue,用于维护要聚合及分发的内容。public static class KmeansAggrValue implements Writable { DenseMatrix centroids; DenseMatrix sums; // used to recalculate new centroids DenseVector counts; // used to recalculate new centroids @Override public void write(DataOutput out) throws IOException { wirteForDenseDenseMatrix(out, centroids); wirteForDenseDenseMatrix(out, sums); wirteForDenseVector(out, counts); } @Override public void readFields(DataInput in) throws IOException { centroids = readFieldsForDenseMatrix(in); sums = readFieldsForDenseMatrix(in); counts = readFieldsForDenseVector(in); } }KmeansAggrValue维护了3个对象:centroids是当前的K个中心点。如果样本是m维,centroids就是一个K*m的矩阵。sums是和centroids大小一样的矩阵,每个元素记录了到特定中心点最近的样本特定维之和。例如sums(i,j)是到第i个中心点最近的样本的第j维度之和。counts是个K维的向量,记录到每个中心点距离最短的样本个数。sums和counts一起用于计算新的中心点,也是要聚合的主要内容。
接下来是自定义的Aggregator实现类
KmeansAggregator,按照上述API的顺序分析其实现。createStartupValue()的实现。public static class KmeansAggregator extends Aggregator<KmeansAggrValue> { public KmeansAggrValue createStartupValue(WorkerContext context) throws IOException { KmeansAggrValue av = new KmeansAggrValue(); byte[] centers = context.readCacheFile("centers"); String lines[] = new String(centers).split("\n"); int rows = lines.length; int cols = lines[0].split(",").length; // assumption rows >= 1 av.centroids = new DenseMatrix(rows, cols); av.sums = new DenseMatrix(rows, cols); av.sums.zero(); av.counts = new DenseVector(rows); av.counts.zero(); for (int i = 0; i < lines.length; i++) { String[] ss = lines[i].split(","); for (int j = 0; j < ss.length; j++) { av.centroids.set(i, j, Double.valueOf(ss[j])); } } return av; } }在该方法中初始化一个
KmeansAggrValue对象,然后从资源文件centers中读取初始中心点,并赋值给centroids。而sums和counts初始化为0。createInitialValue()的实现。@Override public KmeansAggrValue createInitialValue(WorkerContext context) throws IOException { KmeansAggrValue av = (KmeansAggrValue)context.getLastAggregatedValue(0); // reset for next iteration av.sums.zero(); av.counts.zero(); return av; }该方法首先获取上一轮迭代的
KmeansAggrValue,然后将sums和counts清零,只保留了上一轮迭代出的centroids。aggregate()的实现。@Override public void aggregate(KmeansAggrValue value, Object item) throws IOException { DenseVector sample = ((KmeansValue)item).sample; // find the nearest centroid int min = findNearestCentroid(value.centroids, sample); // update sum and count for (int i = 0; i < sample.size(); i ++) { value.sums.add(min, i, sample.get(i)); } value.counts.add(min, 1.0d); }该方法中调用
findNearestCentroid()找到样本item距离最近的中心点索引,然后将其各个维度加到sums上,最后counts计数加1。
以上3个方法执行于所有Worker上,实现局部聚合。在Aggregator Owner所在Worker执行的全局聚合相关操作如下:
merge()的实现。@Override public void merge(KmeansAggrValue value, KmeansAggrValue partial) throws IOException { value.sums.add(partial.sums); value.counts.add(partial.counts); }merge的实现逻辑很简单,就是把各个Worker聚合出的sums和counts相加即可。terminate()的实现。@Override public boolean terminate(WorkerContext context, KmeansAggrValue value) throws IOException { // Calculate the new means to be the centroids (original sums) DenseMatrix newCentriods = calculateNewCentroids(value.sums, value.counts, value.centroids); // print old centroids and new centroids for debugging System.out.println("\nsuperstep: " + context.getSuperstep() + "\nold centriod:\n" + value.centroids + " new centriod:\n" + newCentriods); boolean converged = isConverged(newCentriods, value.centroids, 0.05d); System.out.println("superstep: " + context.getSuperstep() + "/" + (context.getMaxIteration() - 1) + " converged: " + converged); if (converged || context.getSuperstep() == context.getMaxIteration() - 1) { // converged or reach max iteration, output centriods for (int i = 0; i < newCentriods.numRows(); i++) { Writable[] centriod = new Writable[newCentriods.numColumns()]; for (int j = 0; j < newCentriods.numColumns(); j++) { centriod[j] = new DoubleWritable(newCentriods.get(i, j)); } context.write(centriod); } // true means to terminate iteration return true; } // update centriods value.centroids.set(newCentriods); // false means to continue iteration return false; }teminate()中首先根据sums和counts调用calculateNewCentroids()求平均计算出新的中心点。然后调用isConverged()根据新老中心点欧拉距离判断是否已经收敛。如果收敛或迭代次数达到最大数,则将新的中心点输出并返回True,以结束迭代。否则更新中心点并返回False以继续迭代。
main方法main方法用于构造GraphJob,然后设置相应配置,并提交作业。public static void main(String[] args) throws IOException { if (args.length < 2) printUsage(); GraphJob job = new GraphJob(); job.setGraphLoaderClass(KmeansReader.class); job.setRuntimePartitioning(false); job.setVertexClass(KmeansVertex.class); job.setAggregatorClass(KmeansAggregator.class); job.addInput(TableInfo.builder().tableName(args[0]).build()); job.addOutput(TableInfo.builder().tableName(args[1]).build()); // default max iteration is 30 job.setMaxIteration(30); if (args.length >= 3) job.setMaxIteration(Integer.parseInt(args[2])); long start = System.currentTimeMillis(); job.run(); System.out.println("Job Finished in " + (System.currentTimeMillis() - start) / 1000.0 + " seconds"); }说明job.setRuntimePartitioning(false)设置为False后,各个Worker加载的数据不再根据Partitioner重新分区,即谁加载的数据谁维护。