在实际业务开发过程中,企业通常要求作业能在期望的时间节点前产出结果,并根据结果做进一步决策,这就需要作业开发人员及时关注作业运行状态,识别并优化慢作业。您可以通过MaxCompute的Logview功能诊断慢作业。本文为您介绍导致出现慢作业的原因及如何查看慢作业并提供对应的解决措施。
分析运行出错作业
作业运行失败时,通过Logview中的Result页签可以查看出错信息,对于失败的作业,打开Logview默认会跳转到Result页签。
常见失败原因包括:
SQL语法错误,此时不会有DAG和Fuxi jobs,因为还未提交到计算集群执行。
用户UDF出错,在Job Details页签中查看DAG图,确定出问题的UDF,并查看StdOut或StdErr等报错信息。
其他报错,可以参见文档错误码以及解决方案。
分析运行慢作业
编译阶段
作业处于编译阶段的特征是有Logview,但还未执行计划。根据Logview的子状态(SubStatusHistory)可以进一步细分为调度、优化、生成物理执行计划、数据跨集群复制等子阶段。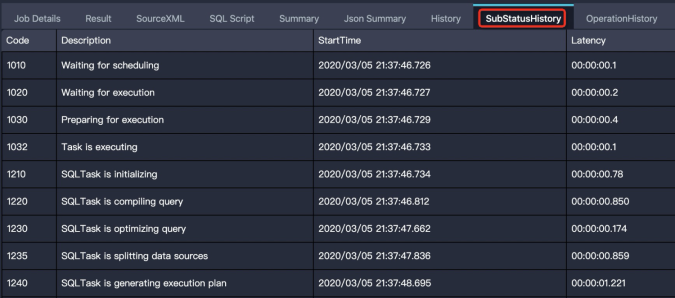 编译阶段的问题主要表现为在某个子阶段卡住,即作业长时间停留在某一个子阶段。下面将介绍作业停留在每个子阶段的可能原因和解决措施。
编译阶段的问题主要表现为在某个子阶段卡住,即作业长时间停留在某一个子阶段。下面将介绍作业停留在每个子阶段的可能原因和解决措施。
调度阶段
问题现象:子状态为
Waiting for cluster resource,作业排队等待被编译。产生原因:计算集群资源紧缺。
解决措施:查看计算集群的状态,需要等待计算集群的资源,如果是预付费客户可以综合考虑,对资源进行扩容。
优化阶段
问题现象:子状态为
SQLTask is optimizing query,优化器正在优化执行计划。产生原因:执行计划复杂,需要较长时间做优化。
解决措施:请耐心等待,正常不会超过10分钟。
生成物理执行计划阶段
问题现象:子状态为
SQLTask is generating execution plan。产生原因一:读取的分区过多。
解决措施:需要优化设计SQL,减少分区的数量,包括:分区裁剪、过滤掉不需要读的分区、把大作业拆成小作业。如何判断SQL中分区剪裁是否生效,以及分区裁剪失效的常见场景请参考文章:分区剪裁合理性评估。
产生原因二:小文件过多。 产生小文件的原因主要有两个:
使用Tunnel上传数据时操作不正确(例如每上传一条数据就重新建一个
upload session),具体可以参考文档:Tunnel命令常见问题。对分区表进行
insert into操作时,会在partition目录下面生成一个新文件。
解决措施:
使用TunnelBufferedWriter接口,可以更简单地进行上传功能,同时避免存在过多小文件。
手工执行一次小文件合并,把小文件Merge起来,更多内容请参考官方文档:合并小文件。
说明小文件个数在万以上可以执行小文件合并动作,系统每天会自动进行小文件合并,但是在一些特殊场景小文件合并失败后,需要手工执行合并。
数据跨集群复制阶段
问题现象:子状态列表里面出现多次
Task rerun,Result里有错误信息FAILED: ODPS-0110141:Data version exception。作业看似失败了,实际还在执行,说明作业正在做数据的跨集群复制。产生原因一:Project刚做集群迁移,往往前一两天有大量需要跨集群复制的作业。
解决措施:这种情况是预期中的跨集群复制,需要用户等待。
产生原因二:Project做过迁移,分区过滤未能处理好,导致读取了比较老的分区。
解决措施:过滤掉不必要读取的老分区。
执行阶段
Logview的Job Details界面有执行计划(执行计划没有全部完毕),且作业状态还是Running。执行阶段卡住或执行时间比预期长的主要原因有等待资源、数据倾斜、UDF执行低效、数据膨胀等,下面将具体介绍每种情况的特征和解决思路。
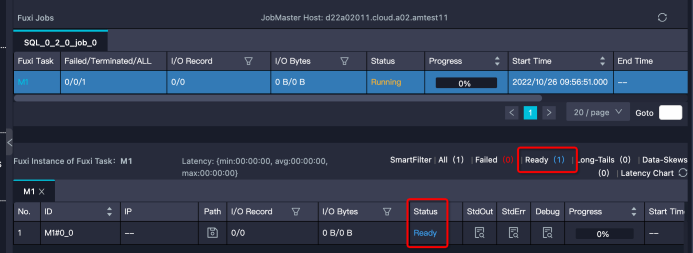
等待资源
特征:Instance处于Ready状态,或部分Instance是Running状态,部分是Ready状态。需要注意的是,如果Instance状态是Ready,但有Debug历史信息,那么可能是Instance Fail触发重试,而不是在等待资源。
解决思路:。
确定排队状态是否正常。可以通过Logview的排队信息
Queue Length查看作业在队列的位置:如下图所示。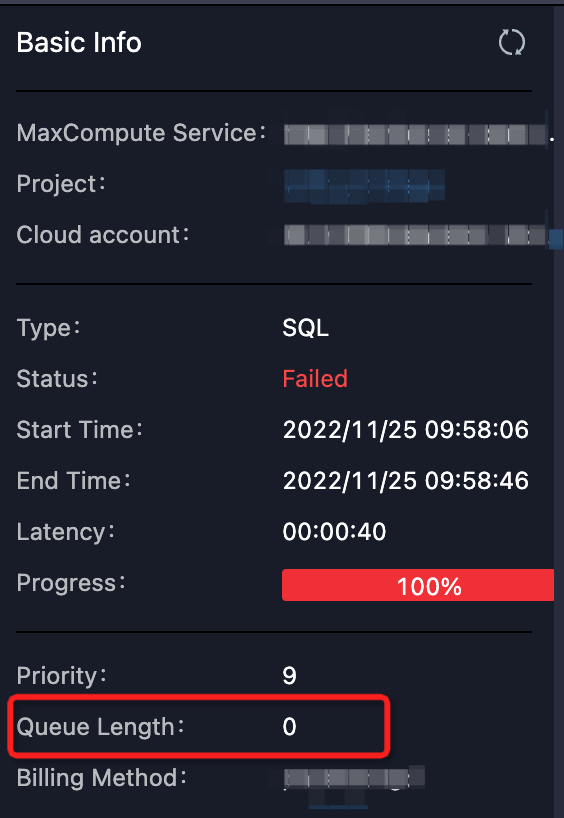 或者通过MaxCompute控制台查看对应Quota组的资源使用情况。如果某项资源的使用率已经接近甚至超过配额了,那么证明Quota组资源紧张,作业有排队是正常的。作业的调度顺序不仅与作业提交时间、优先级有关,还和作业所需内存或CPU资源大小能否被满足有关。
或者通过MaxCompute控制台查看对应Quota组的资源使用情况。如果某项资源的使用率已经接近甚至超过配额了,那么证明Quota组资源紧张,作业有排队是正常的。作业的调度顺序不仅与作业提交时间、优先级有关,还和作业所需内存或CPU资源大小能否被满足有关。查看Quota组中运行的作业。
可能存在误交了低优先级的大作业(或批量提交了很多小作业),占用了大量的资源,可以和作业的负责人协商,先把作业终止掉,让出资源。
考虑走其他Quota组的项目。
对资源进行扩容(包年包月客户)。
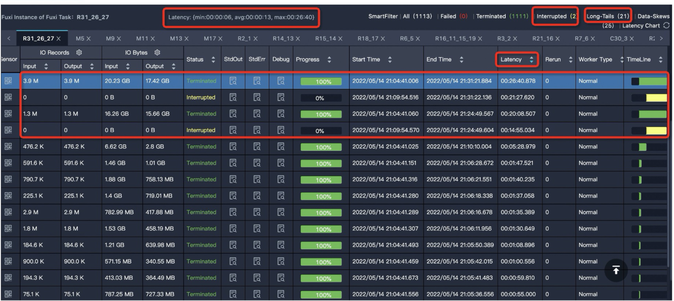
数据倾斜
特征:Task中大多数Instance都已经结束了,但仍有几个Instance却迟迟不结束(长尾)。如下图中大多数Instance都结束了,但是还有21个的状态是Running,这些Instance运行慢,可能是因为处理的数据较多。
解决思路:您可参考数据倾斜调优,其中介绍了一些导致数据倾斜的常见原因及对应的优化思路。
UDF执行低效
这里的UDF泛指各种用户自定义的扩展,包括UDF、UDAF、UDTF、UDJ和UDT等。
特征:某个Task执行效率低,且该Task中有用户自定义的扩展。甚至是UDF的执行超时报错:
Fuxi job failed - WorkerRestart errCode:252,errMsg:kInstanceMonitorTimeout, usually caused by bad udf performance。排查方法:任务报错时,可以在Logview的Job Details页签中,快速通过DAG图判断报错的Task中是否包含UDF。可以看到报错的Task R4_3包含用户使用Java语言编写的UDF,如下图所示。
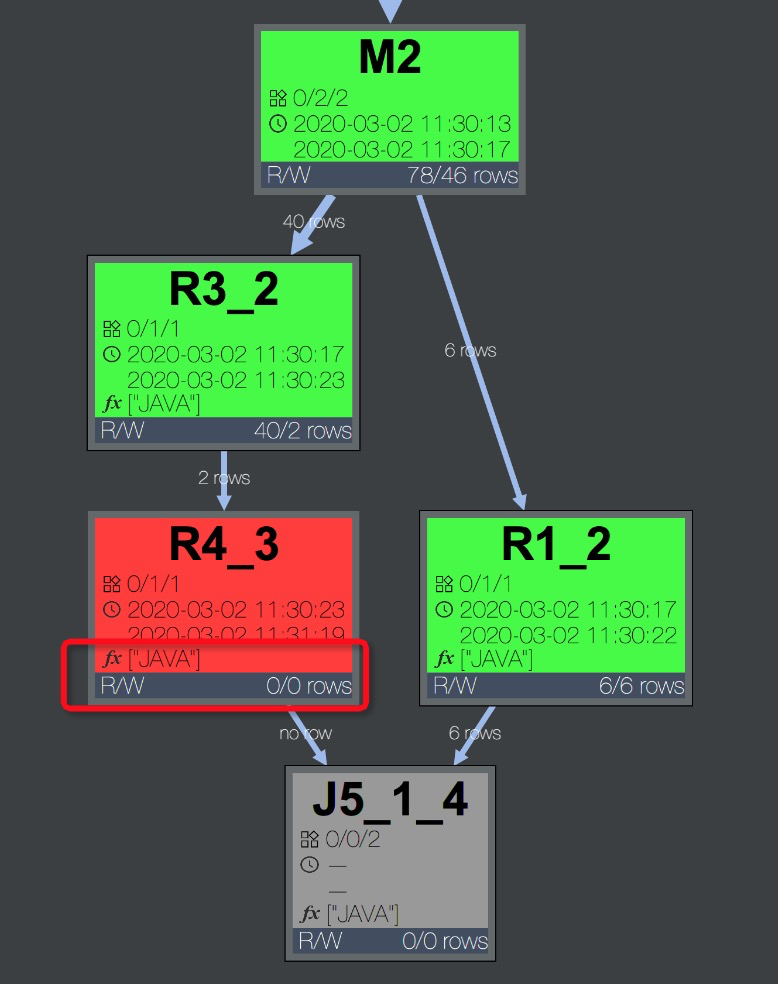 双击R4_3展开Operator视图,可以看到该Task包含的所有UDF名称,如下图所示。
双击R4_3展开Operator视图,可以看到该Task包含的所有UDF名称,如下图所示。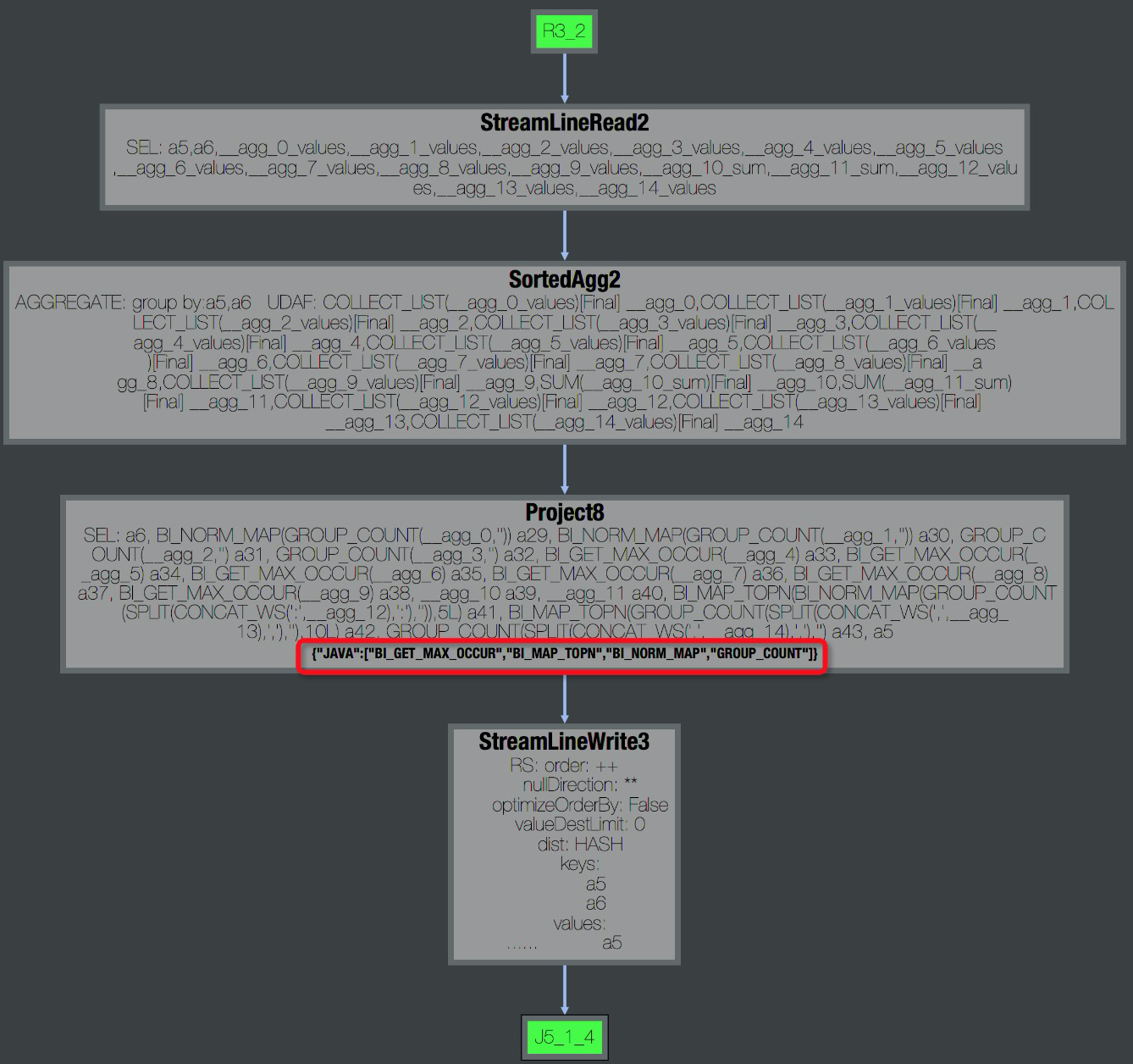 此外,在Task的StdOut日志里,UDF框架会打印UDF输入的记录数、输出记录数、以及处理时间,如下图所示,通过这些数据可以看出UDF是否有性能问题。一般正常情况
此外,在Task的StdOut日志里,UDF框架会打印UDF输入的记录数、输出记录数、以及处理时间,如下图所示,通过这些数据可以看出UDF是否有性能问题。一般正常情况Speed(records/s)在百万或者十万级别,如果降到万级别,那么基本上就存在性能问题了。
解决思路:当出现性能问题时,可以按照下述方法进行排查和优化:
检查UDF是否出错。
有时候是由于某些特定的数据值引起的,比如出现某个值的时候会引起死循环。 MaxCompute Studio支持下载表的部分Sample数据到本地运行,进行排查,详情请参考MaxCompute Studio开发手册:Java UDF、Python UDF 。
检查UDF函数是否与内置函数同名。
内置函数是有可能被同名UDF覆盖的,当看到一个函数像是内置函数时,需要确定是否有同名UDF覆盖了内置函数。
使用内置函数代替UDF。
有相似功能的内置函数的情况下,尽可能不要使用UDF。内置函数一般经过验证,实现比较高效,并且内置函数对优化器而言是白盒,能够做更多的优化。更多内置函数的用法请参考官方文档:内建函数。
将UDF函数进行功能拆分,部分使用内置函数替换,内置函数无法实现的再使用UDF。
优化UDF的evaluate方法。
evaluate中只做与参数相关的必要操作。因为evaluate方法会被反复执行,所以尽可能将一些初始化的操作,或者一些重复计算事先计算好。
预估UDF的执行时间。
先在本地模拟1个Instance处理的数据量测试UDF的运行时间,优化UDF的实现。默认UDF运行时限是30分钟,也就是30分钟内UDF必须要返回数据,或者用
context.progress()来报告心跳。如果UDF预计运行时间本身就大于30分钟,可以通过参数设置UDF超时时间:默认为1800秒。取值范围为1s~3600s --设置UDF超时时间,单位秒,默认为600秒 --可手动调整区间[0,3600]调整内存参数。
UDF效率低的原因并不一定是计算复杂度,有可能是受存储复杂度影响。比如:
某些UDF在内存计算、排序的数据量比较大时,会报内存溢出错误。
内存不足引起GC频率过高。
这时可以尝试调整内存参数,不过此方法只能暂时缓解,具体的优化还是需要从业务上去处理。示例如下:
set odps.sql.udf.jvm.memory= --设定UDF JVM Heap使用的最大内存,单位M,默认1024M --可手动调整区间[256,12288]说明目前如果使用了UDF可能会导致分区剪裁失效。从新版本开始,MaxCompute支持了
UdfProperty注解。UDF的作者在定义UDF时,可以指定这个注解,让编译器知道这个函数是确定性的,如:@com.aliyun.odps.udf.annotation.UdfProperty(isDeterministic = true) public class AnnotatedUdf extends com.aliyun.odps.udf.UDF { public String evaluate(String x) { return x; } }改写SQL语句为如下所示,就可以在分区过滤中使用UDF了。
--原来的写法 SELECT * FROM t WHERE pt = udf('foo'); --pt 是 t 的一个分区列 --改成下面的样子 SELECT * FROM t WHERE pt = (SELECT udf('foo')); --pt 是 t 的一个分区列
数据膨胀
特征:Task的输出数据量比输入数据量大很多。比如1 GB的数据经过处理,变成了1 TB,在一个Instance下处理1 TB的数据,运行效率肯定会大大降低。作业运行完成后输入输出数据量体现在Task的I/O Records中,如果作业在Join阶段长时间不结束,可以选择几个Running状态的Fuxi Instance查看StdOut里的日志,如下图所示:
 StdOut里一直在打印Merge Join的日志,说明对应的单个Worker一直执行Merge Join,红框中Merge Join输出的数据条数已经超过1433亿条,有严重的数据膨胀,需要检查JOIN条件和Join Key是否合理,如下图所示:
StdOut里一直在打印Merge Join的日志,说明对应的单个Worker一直执行Merge Join,红框中Merge Join输出的数据条数已经超过1433亿条,有严重的数据膨胀,需要检查JOIN条件和Join Key是否合理,如下图所示: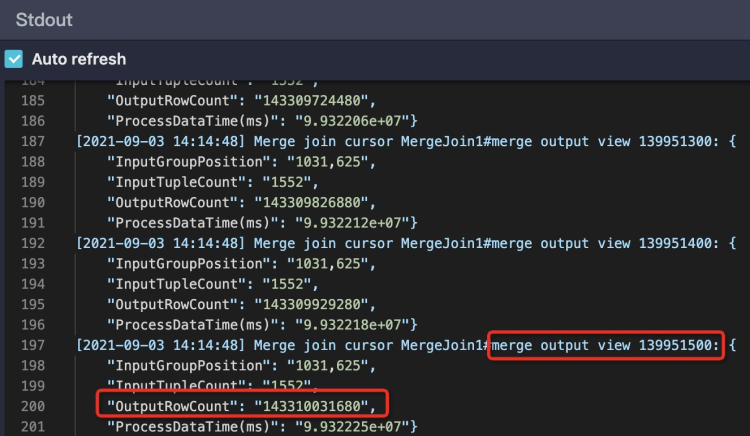
解决思路:
检查代码是否有误:JOIN条件是否写错,是否写成笛卡尔积了、UDTF是否正常,是否输出过多数据。
检查Aggregation引起的数据膨胀。
因为大多数Aggregator是recursive的,中间结果先做了一层Merge,中间结果不大,而且大多数Aggregator的计算复杂度比较低,即使数据量不小,也能较快完成。所以通常情况下这些操作问题不大,如以下两种情况:
SELECT中使用Aggregation按照不同维度做DISTINCT,每一次DISTINCT都会使数据做一次膨胀。
使用GROUPING SETS 、CUBE | ROLLUP,中间数据可能会扩展很多倍。但是,有些操作如COLLECT_LIST、MEDIAN操作需要把全量中间数据都保留下来,可能会产生问题。
避免Join引起的数据膨胀。
例如:两个表Join,左表是人口数据,数据量很大,但是由于并行度足够,效率可观。右表是个维表,记录每种性别对应的一些信息(比如每种性别可能的坏毛病),虽然只有两种性别,但是每种都包含数百行。那么如果直接按照性别来Join,可能会让左表膨胀数百倍。要解决这个问题,可以考虑先将右表的行做聚合,变成两行数据,这样Join的结果就不会膨胀了。
由于Grouping Set导致的数据膨胀。Grouping Set操作会有一个扩展过程,输出数据会按照Group数倍增。 目前的plan没有能力适配Grouping Set并做下游Task dop的调整,用户可以手动设置下游Task的dop。示例如下:
set odps.stage.reducer.num = xxx; set odps.stage.joiner.num = xxx;
结束阶段
大部分SQL作业在Fuxi作业结束后即停止。但有时Fuxi作业结束时,作业总体进度仍然处于运行状态。如下图中的Logview,右侧Job Details页面显示Fuxi作业所有阶段为Terminated,但左侧代表作业整体进度的Status仍然显示Running: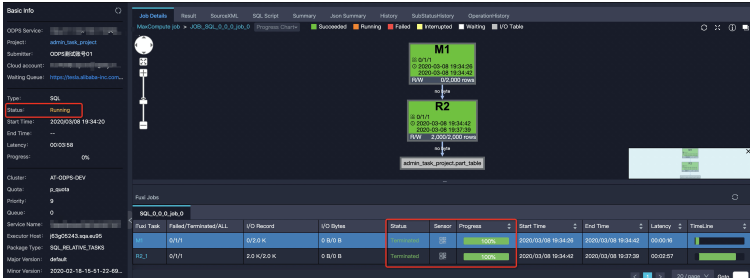 造成这种现象一般分为两种情况:
造成这种现象一般分为两种情况:
一个SQL作业可能包含多个Fuxi作业,比如子查询存在多阶段执行,作业输出小文件过多导致的自动合并作业。
SQL在结束阶段运行于控制集群的逻辑占用时间较长,比如更新动态分区的元数据,下面将举例介绍几种典型。
子查询多阶段执行
大部分情况下,MaxCompute SQL的子查询会被编译进同一个Fuxi DAG,即所有子查询和主查询都通过一个Fuxi作业完成。但也有一些特殊子查询需要先将子查询单独执行。如下示例:
SELECT product, sum(price) FROM sales WHERE ds in (SELECT DISTINCT ds FROM t_ds_set) GROUP BY product;子查询
SELECT DISTINCT ds FROM t_ds_set先执行,其结果需要被用来做分区裁剪,来优化主查询需要读取的分区数。这两次运行分别是两个Fuxi作业,Logview中体现的是两个tab页来显示:第一个tab页显示job_0全部成功,实际上第二个tab页的job_1作业还正在执行。如下图所示: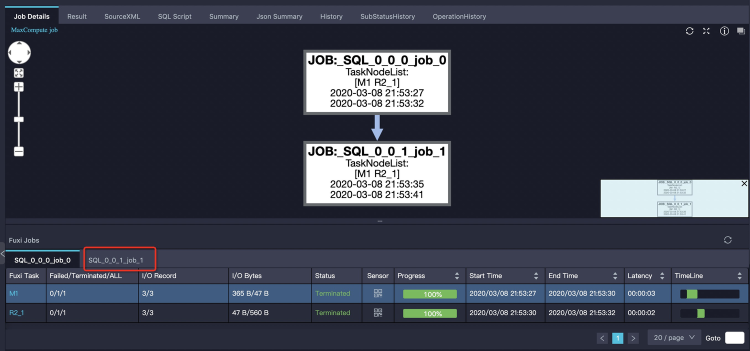 这时我们只需单击第二个tab页可以看到job_1的执行情况,如下图所示:
这时我们只需单击第二个tab页可以看到job_1的执行情况,如下图所示:
过多小文件
小文件主要带来存储和计算两方面问题。
存储方面:小文件过多会给Pangu文件系统带来一定的压力,且影响空间的有效利用。
计算方面:ODPS处理单个大文件比处理多个小文件效率高,小文件过多会影响整体的计算执行性能。因此,为了避免系统产生过多小文件,SQL作业在结束时会针对一定条件自动触发合并小文件的操作。
解决措施:通过Logview可以查看作业是否触发了自动合并小文件。与前面介绍过的子查询多阶段执行类似,Merge作业也是作为一个单独的tab页显示,自动合并小文件多出来的Merge Task,虽然会增加当前作业整体执行时间,但是会让结果表在合并后产生的文件数和文件大小更合理,从而避免对文件系统产生过大压力,也使得表被后续的作业使用时,拥有更好的读取性能。如下图所示:
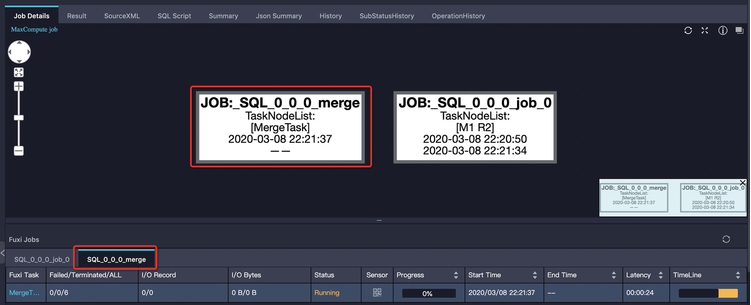
小文件过多除了造成上文说的问题外,还会导致SELECT屏显也在作业结束阶段长时间运行。因为在汇聚屏显结果时,需要打开大量小文件进行读取,耗费大量时间在文件操作上。对于这种情况,需要尽量避免使用SELECT语句造成屏显数量巨大的结果,如果需要大批量返回结果应该使用Tunnel进行下载数据。另外如果结果实际不大,但是文件数过多,那么最好是先检查前文所述的小文件阈值配置是否正确。了解更多关于合并小文件的知识,请查阅官方文档:合并小文件。
动态分区元数据更新
问题现象:Fuxi作业执行完后,可能还有一些元数据操作。比如要把结果数据挪到特定目录去,然后更新表的元数据。有可能动态分区输出了太多分区,也会消耗一定的时间。例如,对分区表sales使用
insert into ... values命令新增2000个分区,如下所示:INSERT INTO TABLE sales partition (ds)(ds, product, price) VALUES ('20170101','a',1),('20170102','b',2),('20170103','c',3), ...;Fuxi作业执行结束后,仍需要一段时间进行表的元数据更新。如下图Logview的子状态所示,可以看到作业卡在
SQLTask is updating meta information。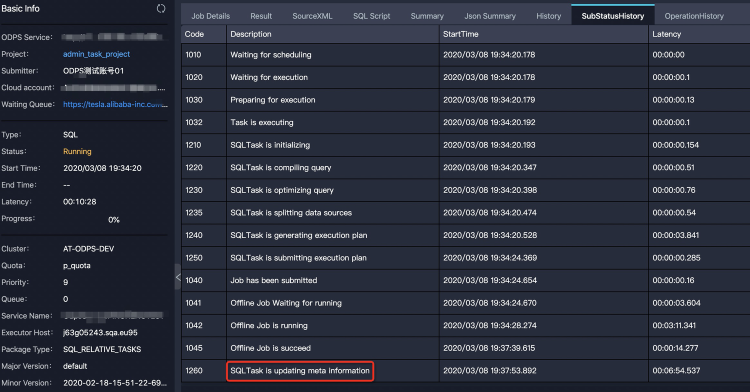
输出文件size变大
问题现象:在输入输出条数相差不大的情况,可能存在结果膨胀几倍。
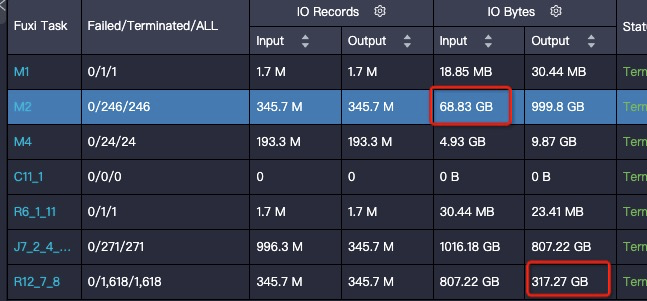
解决思路:一种情况是数据分布变化导致的,在向表中写数据的过程中,会对数据进行压缩,而压缩算法对于重复数据的压缩率是最高的,所以在写数据的过程中,如果相同的数据都排布在一起,就可以获得很高的压缩率。数据分布情况主要取决于数据写入的阶段(对应上图的R12)是如何Shuffle和排序的,上图给出的SQL最后的操作是JOIN,JOIN Key为如下代码:
on t1.query = t2.query and t1.item_id=t2.item_id研究一下数据的特征,大部分列都是item的属性,即相同的
item_id其余的列都完全相同,按照Query排序会把item完全打乱,导致压缩率降低非常多。这里调整JOIN顺序为如下所示,调整后数据减少到原来的三分之一。on t1.item_id=t2.item_id and t1.query = t2.query调整后数据减少到原来的三分之一。
另一种情况,JOIN或者
group by产生的Shuffle都没有包含对压缩来说最理想的排序列,这时候也可以考虑使用Zorder的方式增加一个本地的排序,以较小的代价获得较高的压缩率。也可以单独执行distributed by sort by命令,手动进行重排布,但是这样计算的代价会比较大。