您可以通过JDBC方式访问Lindorm计算引擎服务,使用Spark SQL完成数据查询、数据分析和数据生产等操作。
前提条件
- 已创建并开通Lindorm实例的宽表引擎,具体操作请参见创建实例。
- 已开通Lindorm实例的计算引擎服务,具体操作请参见开通与变配。
- 已安装Java环境,要求使用JDK 1.8及以上版本。
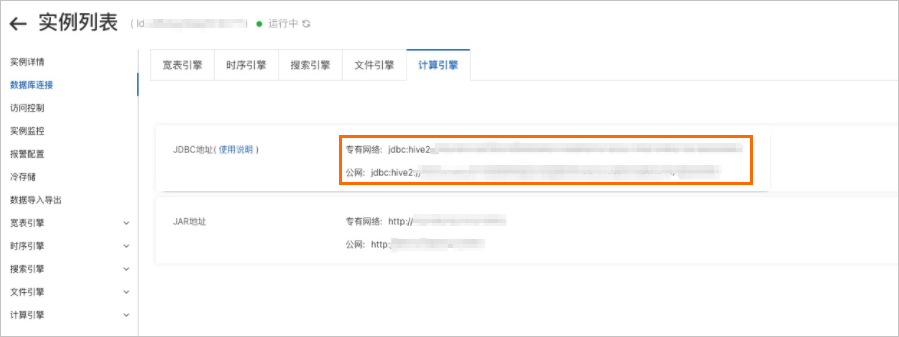
JDBC连接地址
查看Lindorm计算引擎连接地址的具体步骤请参见
查看连接地址。
使用Beeline访问JDBC服务
- 下载Spark发布包。
- 解压Spark发布包。
- 将解压后的路径配置为Spark路径。
export SPARK_HOME=/path/to/spark/;
- 填写配置文件:
$SPARK_HOME/conf/beeline.conf。
- endpoint:Lindorm计算引擎的JDBC连接地址。
- user:宽表用户名。
- password:宽表用户名对应的密码。
- shareResource:多个交互会话之间是否共享Spark资源,默认值为true。
- 运行
/bin/beeline命令。在交互会话中输入SQL语句。
Lindorm计算引擎支持各类数据源的访问,具体请参见使用须知。
以Hive数据为例,开通Lindorm Hive服务后您可以通过以下方式建表和读写数据。开通方法请参见
开通Hive服务。
CREATE TABLE test (id INT, name STRING);
INSERT INTO test VALUES (0, 'Jay'), (1, 'Edison');
SELECT id, name FROM test;
使用Java访问JDBC服务
- 添加JDBC环境依赖,以Maven为例。
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.3.8</version>
</dependency>
- 编写Java程序代码访问JDBC服务,代码示例如下:
import java.sql.*;
public class App {
public static void main(String[] args) throws Exception {
Class.forName("org.apache.hive.jdbc.HiveDriver");
String endpoint = "jdbc:hive2://123.234.XX.XX:10009/;?token=bisdfjis-f7dc-fdsa-9qwe-dasdfhhv8****";
String user = "";
String password = "";
Connection con = DriverManager.getConnection(endpoint, user, password);
Statement stmt = con.createStatement();
String sql = "SELECT * FROM test";
ResultSet res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1));
}
}
}
- 可选:如果您需要配置更多的作业参数可以在JDBC连接地址中指定,示例如下:
String endpoint = "jdbc:hive2://123.234.XX.XX:10009/;?token=bisdfjis-f7dc-fdsa-9qwe-dasdfhhv8****;spark.dynamicAllocation.minExecutors=3;spark.sql.adaptive.enabled=false";
使用Python访问JDBC服务
- 下载Spark发布包。
- 解压Spark发布包。
- 配置路径参数。
- 配置Spark路径。
export SPARK_HOME=/path/to/dir/;
- 配置CLASSPATH。
export CLASSPATH=$CLASSPATH:$SPARK_HOME/jars/*;
- 安装JayDeBeApi。
- 编写Python程序代码访问JDBC服务,代码示例如下:
import jaydebeapi
driver = 'org.apache.hive.jdbc.HiveDriver'
endpoint = 'jdbc:hive2://123.234.XX.XX:10009/;?token=bisdfjis-f7dc-fdsa-9qwe-dasdfhhv8****'
jarPath = '/path/to/sparkhome/jars/hive-jdbc-****.jar'
user = '****'
password = '****'
conn=jaydebeapi.connect(driver, endpoint, [user, password], [jarPath])
cursor = conn.cursor()
cursor.execute("select 1")
results = cursor.fetchall()
cursor.close()
conn.close()
- 可选:如果您需要配置更多的作业参数可以在JDBC连接地址中指定,示例如下:
endpoint = "jdbc:hive2://123.234.XX.XX:10009/;?token=bisdfjis-f7dc-fdsa-9qwe-dasdfhhv8****;spark.dynamicAllocation.minExecutors=3;spark.sql.adaptive.enabled=false"