云原生多模数据库 Lindorm计算引擎支持通过数据管理DMS的任务编排功能来调度Lindorm Spark任务,并查看Lindorm Spark任务发布记录和日志,满足用户在数据生产、交互式分析、机器学习和图计算等场景中的计算需求。本文介绍通过DMS管理Lindorm Spark作业的方法。
前提条件
已开通数据管理DMS服务。
已开通计算引擎。如何开通,请参见开通与变配。
已完成作业开发。如何开发,请参见JAR作业开发实践或Python作业开发实践。
已将作业上传至HDFS或OSS。如何上传至HDFS,请参见通过控制台上传文件。
创建Lindorm Spark任务流
登录数据管理DMS 5.0。
进入任务编排页面。
DMS极简模式:
在场景引导区域,单击数据传输与加工(DTS)。
在右侧数据加工区域,单击任务编排卡片。
DMS非极简模式:在顶部菜单栏中,选择。
在任务编排页面,单击新增任务流。
在新增任务流对话框中,输入任务流名称和描述,并单击确认。
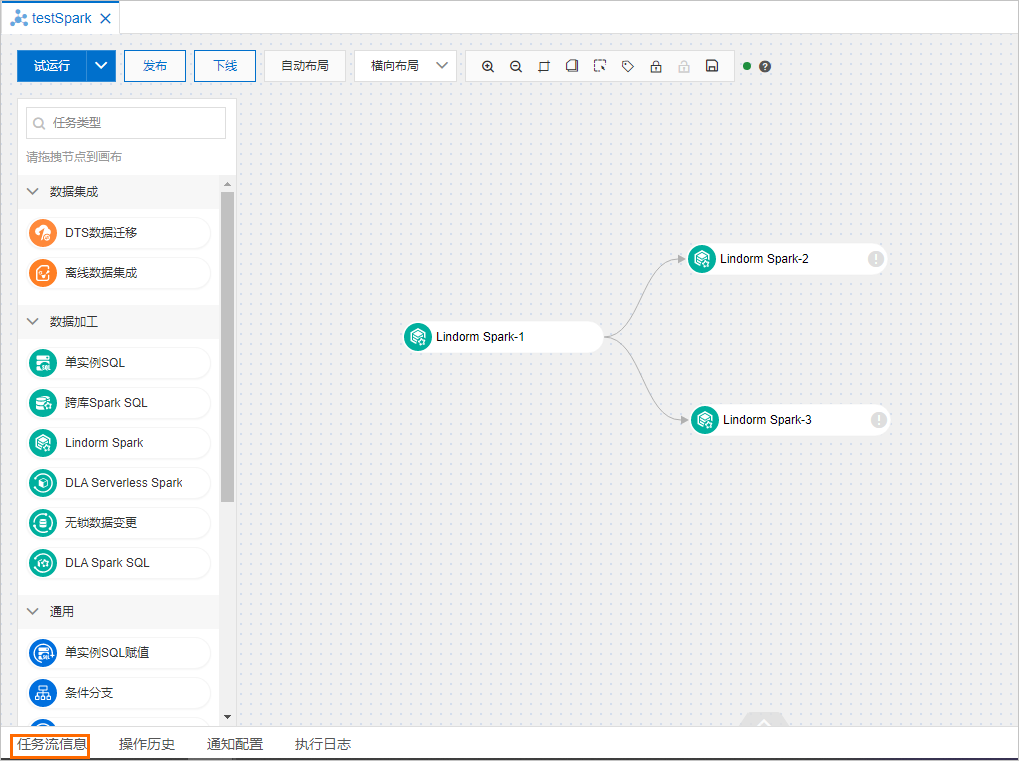
在左侧任务类型列表中,拖拽Lindorm Spark任务节点到空白区域,并通过连线的方式定义任务节点之间的依赖关系。
配置Lindorm Spark任务节点。
双击Lindorm Spark任务节点或者单击Lindorm Spark任务节点并选择
 。
。在打开的任务节点页面中,配置基础参数和运行作业的自定义参数。
在基础配置区域配置基础参数,基础参数说明如下表:
参数
说明
地域
选择目标Lindorm实例所属的地域。
Lindorm实例
选择目标Lindorm实例ID。
任务类型
选择Spark作业类型,支持以下两种:
JAR
Python
SQL
在作业配置区域配置运行作业的自定义参数。以下列出不同的Spark作业配置模板和自定义参数说明。
JAR作业配置模板和自定义参数说明如下:
{ "mainResource" : "oss://path/to/your/file.jar", "mainClass" : "path.to.main.class", "args" : [ "arg1", "arg2" ], "configs" : { "spark.hadoop.fs.oss.endpoint" : "", "spark.hadoop.fs.oss.accessKeyId" : "", "spark.hadoop.fs.oss.accessKeySecret" : "", "spark.hadoop.fs.oss.impl" : "org.apache.hadoop.fs.aliyun.oss.AliyunOSSFileSystem", "spark.sql.shuffle.partitions" : "20" } }参数
参数类型
是否必填
说明
示例值
mainResource
String
是
JAR包存储在HDFS或OSS的路径。
JAR包存储至HDFS:hdfs:///path/spark-examples_2.12-3.1.1.jar
JAR包存储至OSS:oss://testBucketName/path/spark-examples_2.12-3.1.1.jar
mainClass
String
是
JAR作业的程序入口类。
com.aliyun.ldspark.SparkPi
args
Array
否
传入mainClass参数。
["arg1", "arg2"]
configs
Json
否
Spark系统参数配置。此外,如果您已将作业上传至OSS,则需要在此增加以下配置:
spark.hadoop.fs.oss.endpoint:存储作业的OSS地址。
spark.hadoop.fs.oss.accessKeyId:通过阿里云控制台创建的Access Key ID,获取方法请参见创建AccessKey。
spark.hadoop.fs.oss.accessKeySecret:通过阿里云控制台获取Access Key Secret,获取方法请参见创建AccessKey。
spark.hadoop.fs.oss.impl:访问OSS的类。固定值为:org.apache.hadoop.fs.aliyun.oss.AliyunOSSFileSystem。
{ "spark.sql.shuffle.partitions": "200"}
Python作业配置模板和自定义参数说明如下:
{ "mainResource" : "oss://path/to/your/file.py", "args" : [ "arg1", "arg2" ], "configs" : { "spark.hadoop.fs.oss.endpoint" : "", "spark.hadoop.fs.oss.accessKeyId" : "", "spark.hadoop.fs.oss.accessKeySecret" : "", "spark.hadoop.fs.oss.impl" : "org.apache.hadoop.fs.aliyun.oss.AliyunOSSFileSystem", "spark.submit.pyFiles" : "oss://path/to/your/project_file.py,oss://path/to/your/project_module.zip", "spark.archives" : "oss://path/to/your/environment.tar.gz#environment", "spark.sql.shuffle.partitions" : "20" } }参数
参数类型
是否必选
说明
示例值
mainResource
String
是
Python文件存储在OSS或者HDFS的路径。
Python文件存储至OSS:oss://testBucketName/path/spark-examples.py
Python文件存储至HDFS:hdfs:///path/spark-examples.py
args
Array
否
传入mainClass参数。
["arg1", "arg2"]
configs
Json
否
Spark系统参数配置。如果将作业上传至OSS,需要在此配置以下参数:
spark.hadoop.fs.oss.endpoint:存储作业的OSS地址。
spark.hadoop.fs.oss.accessKeyId:通过阿里云控制台创建的Access Key ID,获取方法请参见创建AccessKey。
spark.hadoop.fs.oss.accessKeySecret:通过阿里云控制台获取Access Key Secret,获取方法请参见创建AccessKey。
spark.hadoop.fs.oss.impl:访问OSS的类。固定值为:org.apache.hadoop.fs.aliyun.oss.AliyunOSSFileSystem。
{"spark.sql.shuffle.partitions": "200"}
SQL作业配置模板和自定义参数说明如下:
{ "mainResource" : "oss://path/to/your/file.sql", "configs" : { "spark.hadoop.fs.oss.endpoint" : "", "spark.hadoop.fs.oss.accessKeyId" : "", "spark.hadoop.fs.oss.accessKeySecret" : "", "spark.hadoop.fs.oss.impl" : "org.apache.hadoop.fs.aliyun.oss.AliyunOSSFileSystem", "spark.sql.shuffle.partitions" : "20" } }参数
参数类型
是否必选
说明
示例
mainResource
String
是
SQL文件存储在OSS或者HDFS的路径。
SQL文件存储至OSS:oss://testBucketName/path/spark-examples.sql
SQL文件存储至HDFS:hdfs:///path/spark-examples.sql
configs
Json
否
SQL作业的其他相关配置。
{ "spark.executor.memory" : "8g"}
完成以上配置后,单击页面左上方的试运行,检查作业运行效果是否符合预期。
发布任务流。所有的任务节点配置完成后,单击任务流名称页面左上方的发布。
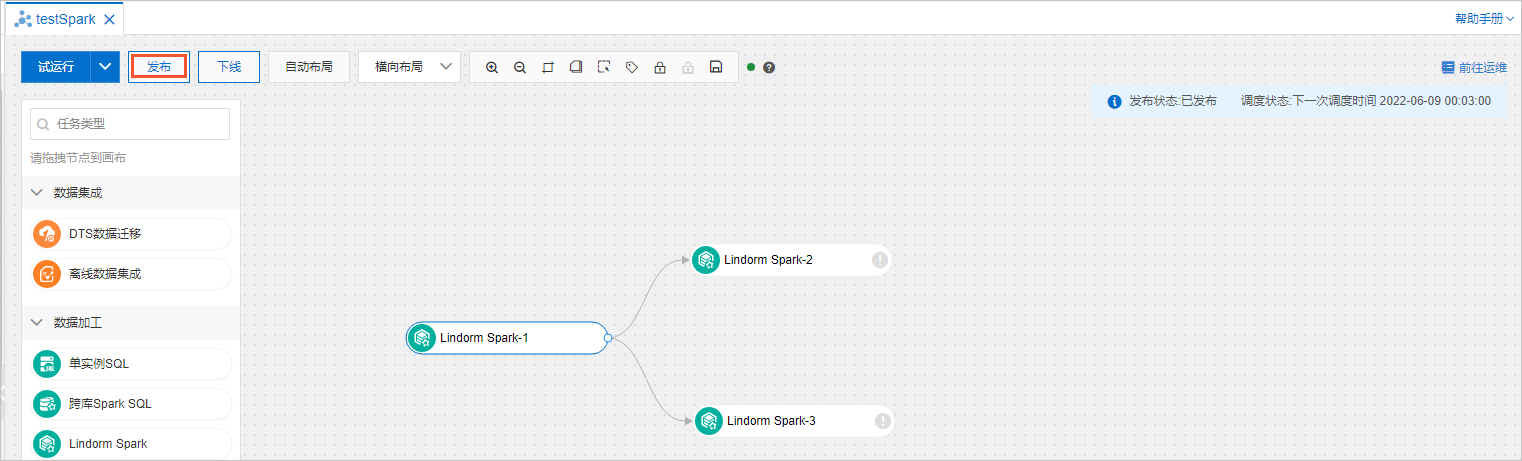
查看任务流的发布记录和日志
在任务编排页面单击目标任务流名称。
单击任务流名称页面右上角的前往运维。
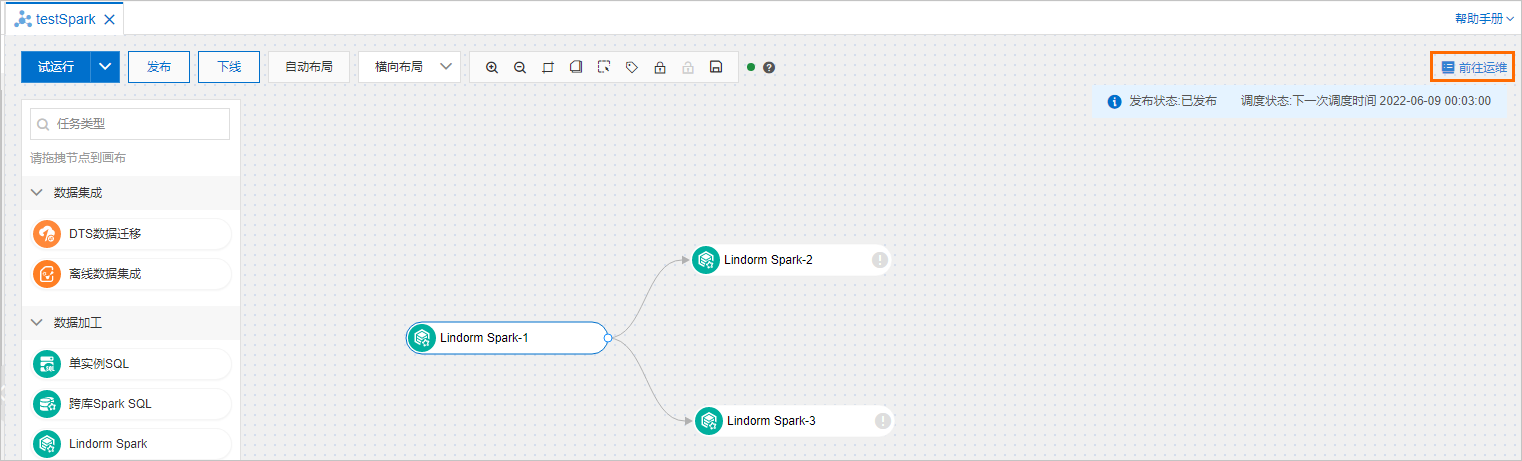
查看任务流的发布记录和日志。
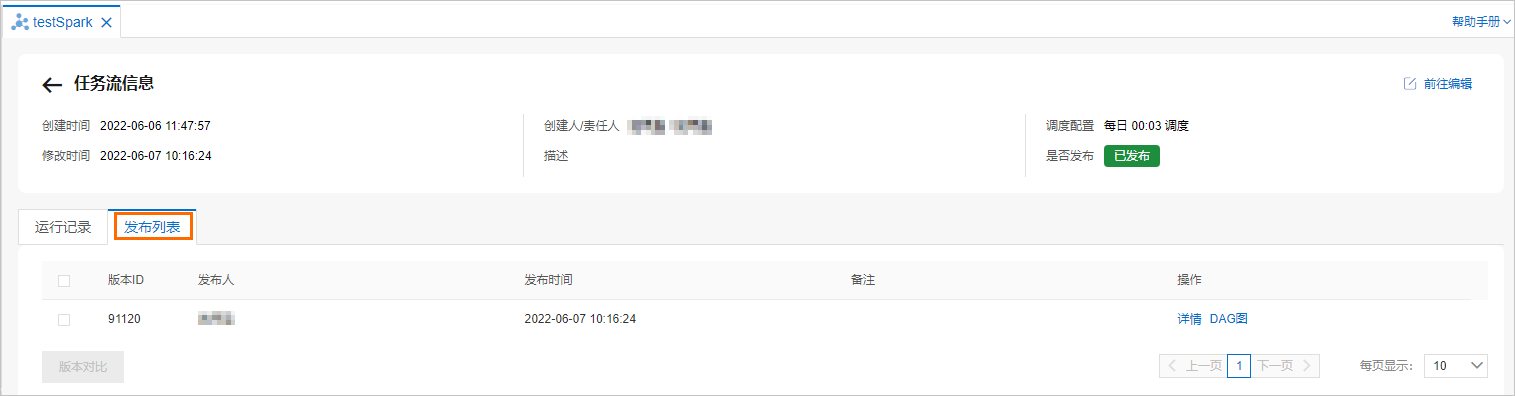
查看任务流的发布记录。在任务流信息页面,单击发布列表页签可以查看任务流的发布记录。
查看任务流的日志。
在运行记录页签左上方的下拉列表中选择定时触发或者手动触发,可以查看任务流中所有任务节点的详细信息。
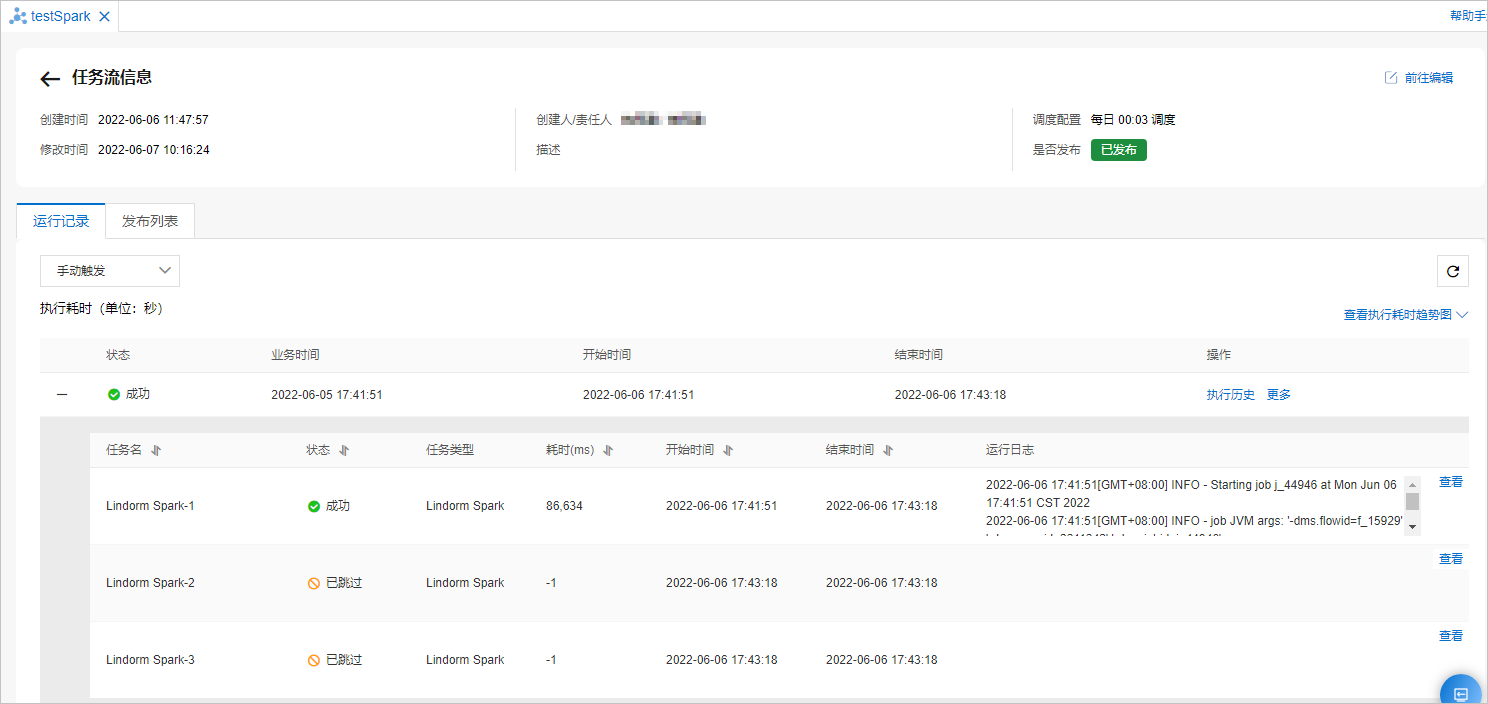
单击任务节点名称后面的查看,可以查看Lindorm Spark任务作业的提交日志,获取该任务节点的JobID和SparkUI。
说明如果任务提交失败,请将JobID和SparkUI提供给工单处理人员并提交工单。
任务流高级配置
通过数据管理DMS控制台对Lindorm Spark任务流进行相关配置,配置完成后需要重新发布任务流。
调度配置
根据业务需求配置相应的调度策略,Lindorm Spark任务流会根据该调度策略自动执行。配置方法如下:
在任务编排页面单击目标任务流名称。
单击任务流名称页面左下角的任务流信息。
在右侧调度配置区域,打开开启调度开关,配置调度策略,配置项说明如下表。
配置项
说明
调度类型
选择调度类型:
周期调度:周期性调度任务,例如一周执行一次任务。
调度一次:在指定时间执行一次任务,仅需要配置执行任务的具体时间。
生效时间
选择调度周期生效的区间,默认1970-01-01~9999-01-01,表示一直生效。
调度周期
选择调度任务的周期:
小时:按设定的小时执行任务调度,需要配置定时调度。
日:按每日一次的频率执行任务调度,需要配置每日调度的具体时间。
周:以周为周期,每个指定天执行一次任务调度,需要配置指定时间和具体时间。
月:以月为周期,每个指定天执行一次任务调度,需要配置指定时间和具体时间。
定时调度
提供了2种定时调度的方式:
固定间隔时间调度:
开始时间:执行任务的开始时间。
间隔时间:执行任务的间隔时间,单位为小时。
结束时间:执行任务的结束时间。
例如,配置开始时间为00:00、间隔时间为6小时、结束时间为20:59,系统将在0点、6点、12点、18点执行任务。
指定时间调度:选择执行任务的目标时间点。
例如选择和0小时和5小时,系统将在0点和5点执行任务。
指定时间
如果调度周期为周,选择星期几执行任务,支持多选。
如果调度周期为月,选择每月几号执行任务,支持多选。
具体时间
设置执行任务流的具体时间。
例如配置02:55,系统将在指定天的02时55分执行任务。
cron表达式
不需要手动配置,系统会根据您配置的周期、具体时间自动展现。
调度配置示例:如果需要配置任务流在每天0点和12点进行调度,调度策略配置如下。
调度类型选择周期调度。
调度周期选择小时。
定时调度选择指定时间,同时在指定时间列表中选择0小时和12小时。
变量配置
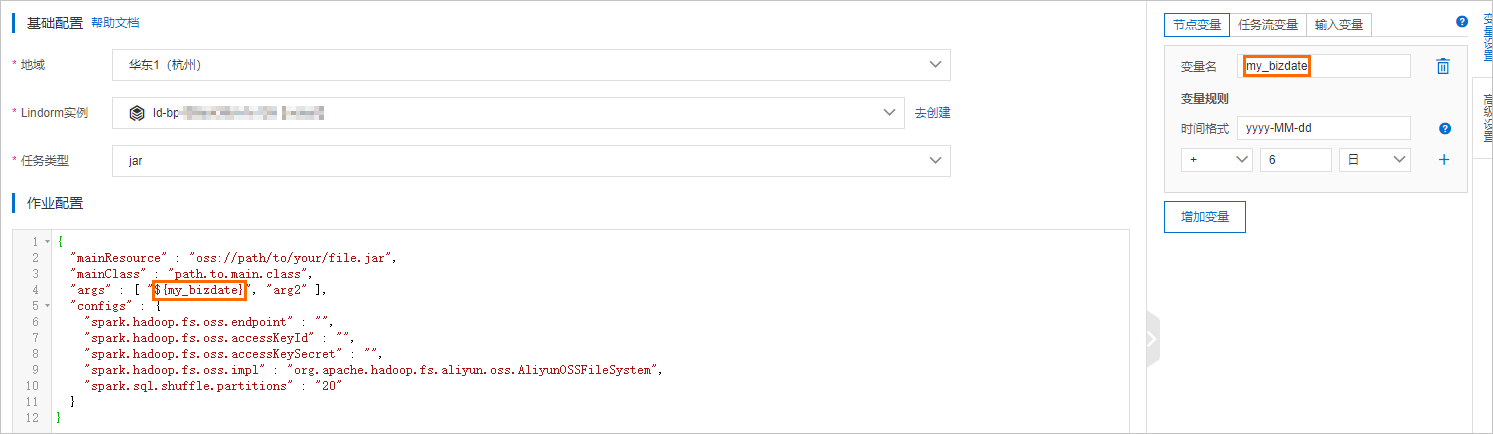
对于周期调度的任务流,可以将调度时间作为参数传递给要执行的任务。例如:将业务时间bizdate(运行时间的前一天)传递给任务节点,按照如下步骤配置时间变量。
在任务流名称页面,双击Lindorm Spark任务节点或者Lindorm Spark任务节点并选择
。在右侧菜单栏选择变量设置。
在节点变量或者任务流变量页签中添加变量名。
在作业配置区域中使用变量。更多变量请参见变量概述。
通知配置
如果打开通知开关,系统会根据任务流执行的结果发送相应的通知消息。打开通知方法如下:
单击任务流名称页面左下角的通知配置。
根据业务需求打开对应的通知开关。
基本通知
成功通知:任务流执行成功发送通知信息。
失败通知:任务流执行失败发送通知信息。
超时通知:任务流执行超时发送通知信息。
预警通知:任务即将开始时发送通知信息。
可选:配置消息接收人,请参见消息通知管理。
交互式SQL
登录数据管理DMS 5.0。
单击首页页签。
在左侧导航栏,单击
 新建实例。
新建实例。在新增实例对话框中,选择NoSQL数据库分类中的Lindorm_Compute。
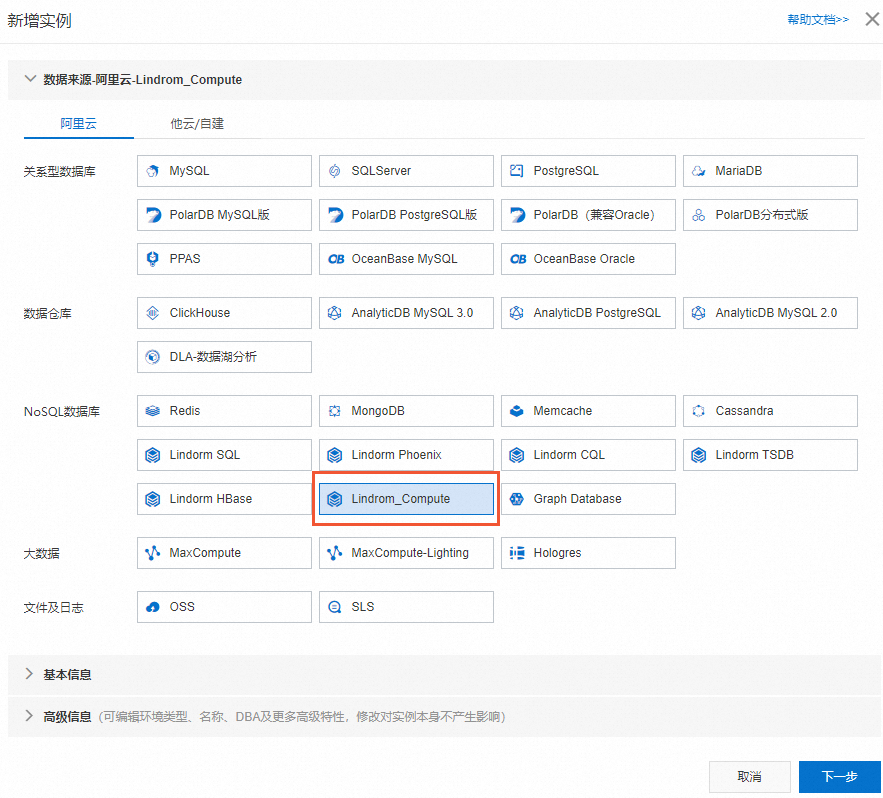
填写Lindorm实例的实例地区、实例ID、数据库账号和数据库密码,并单击提交。
在弹出的对话框中单击确定,进入SQL编辑窗口。
在SQLConsole输入SQL语句,单击执行。
相关文档
有关数据管理DMS的任务编排功能,详情请参见任务编排概述。