添加Spark数据源可以实现批量快速导入数据功能,本文介绍添加Spark数据源的方法。
前提条件
已购买引擎类型为LTS的Lindorm实例。
已创建Lindorm实例并开通计算引擎服务,创建方法请参见创建实例。
添加方式
通过云原生多模数据库 Lindorm控制台添加Spark数据源
登录Lindorm管理控制台。
在实例列表页,单击引擎类型为LTS的实例ID。
在左侧导航栏选择数据源管理。
切换至计算引擎数据源页签,单击添加数据源。
在添加数据源对话框中配置以下信息。
单击确定,状态为已关联表示Spark数据源已添加成功。
通过LTS服务添加Spark数据源
登录LTS服务,具体操作请参见登录LTS服务。
在左侧导航栏选择。
在添加数据源页面配置以下参数。
参数
说明
名称
固定填写lts_bulkload_spark。
数据源类型
固定选择Spark。
数据源参数
配置Spark数据源的相关参数。
{ "virtualClusterName":"token", "hdfsUri":"hdfs://nn1:8020,nn2:8020", "sparkEndpoint":"http://192.168.XX.XX:10099" }virtualClusterName:Lindorm计算引擎的JAR地址Token值。通过云原生多模数据库 Lindorm控制台的数据库连接获取,如下图所示。
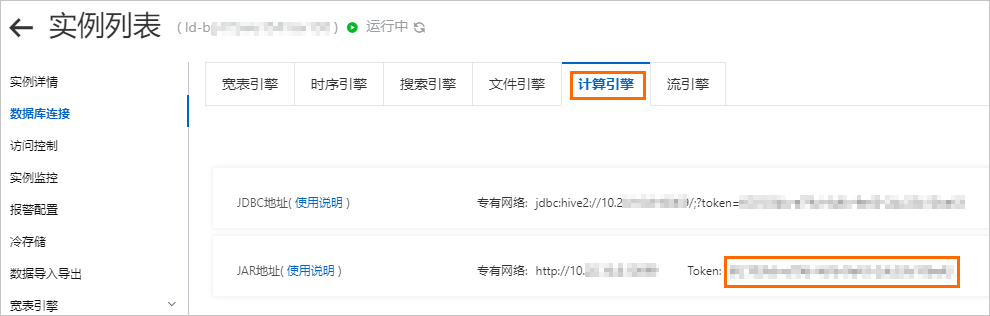
hdfsUri:Lindorm实例的HDFS连接地址,格式为:
hdfs://nn1:8020,nn2:8020。说明连接地址中获取
nn1和nn2的方法请提交工单sparkEndpoint:Lindorm计算引擎的JAR专有网络地址。通过云原生多模数据库 Lindorm控制台的数据库连接获取,如下图所示。
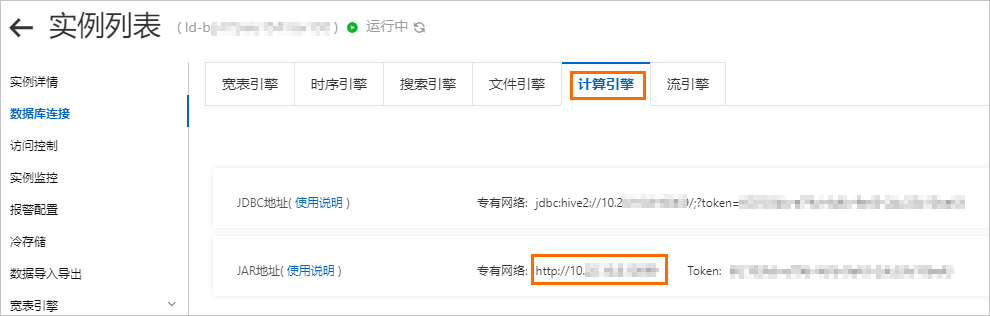
单击添加。