本文将为您介绍在Hologres中Shard级别的Replication使用。
功能概述
从Hologres V1.1版本开始,支持通过设置Table Group副本数的方式来提高某个Table Group查询并发能力和可用性。您可以在创建Table Group的时候通过显式指定的replica count或者修改已有的replica count来打开Replication的功能。新增的副本属于内存级别的运行时副本,不会增加额外存储成本。
关于replica count的说明具体如下:
数据是按Shard分布的,不同Shard管理不同的数据,不同Shard之间的数据没有重复,所有的Shard在一起是一份完整的数据。
默认情况下每一个Shard只有一个副本,即
replica count = 1,其对应的属性为leader。您可以通过调整replica count的值,使相同的数据有多个副本,其他副本的属性为follower。写请求由Leader Shard负责,读请求会均衡由多个Follower Shard(也包含leader Shard)共同服务。当使用Follower Shard查询时,数据可能会出现10~20ms级别延迟。
replica count默认值是1,表示不启用Replication。大于1表示开启Replication,replica count数字越大,对资源的消耗也越大。由于Replica布局具有反亲和特性,即多个replica不可以布局在同一个计算节点上,因此replica count参数应小于等于计算节点数。从Hologres V1.3.53版本开始,replica count上限为worker个数,如若超过则会报错。有关不同规格拥有的计算节点数,参考实例管理。
考虑到计算节点计算力的均衡性,在增加Replication时,应该同步缩小shard_count,保持
shard_count * replica count = 默认实例推荐shard数时,具备最好的性能。Hologres从V1.3.45版本开始,支持查询高可用。
若您发现您的实例监控信息页面出现了类似如下图的情况:
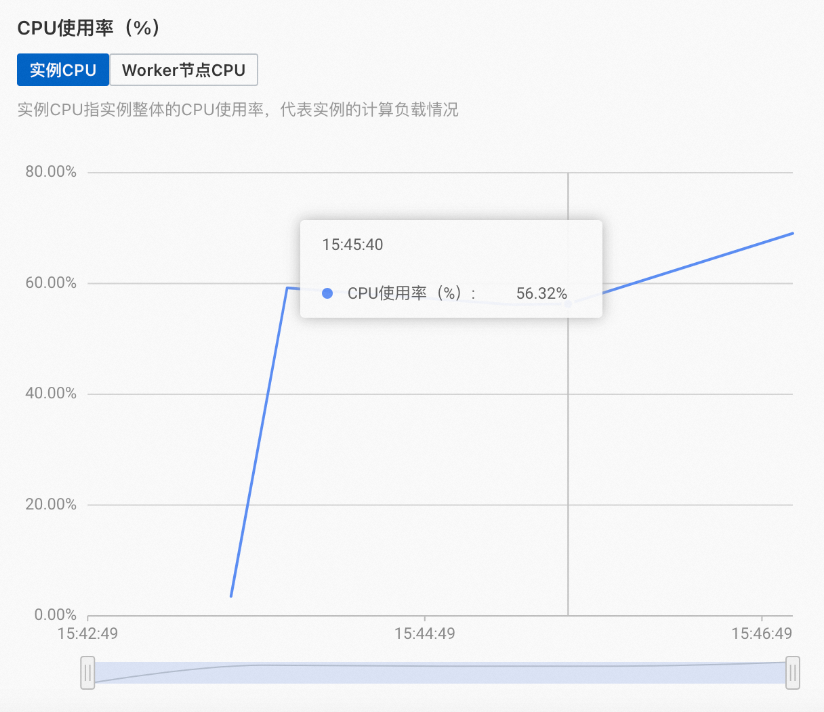
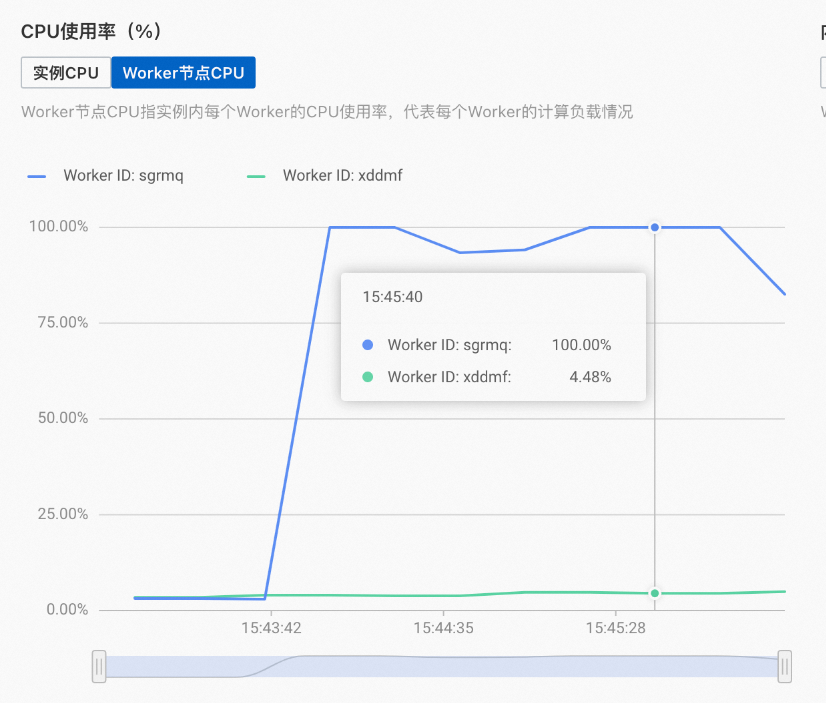
实例整体资源利用率不高,但是仅有小部分Worker计算资源使用率很高,其他Worker计算资源利用率很低,那么有可能是查询不均导致的,即大部分的查询仅用了其中几个Shard回答查询,此时您可以增加Shard的副本数量,让更多的Worker上有Shard的副本,该操作可以有效提高资源利用率和QPS。
说明Leader Shard和Follower Shard之间同步元数据需要消耗一定的资源,且副本数越多,消耗的资源越多。所以若非定位到是因为查询不均导致资源使用不均衡,否则不建议使用该方式提升QPS。
同时Leader Shard和Follower Shard会存在毫秒级的数据延迟。
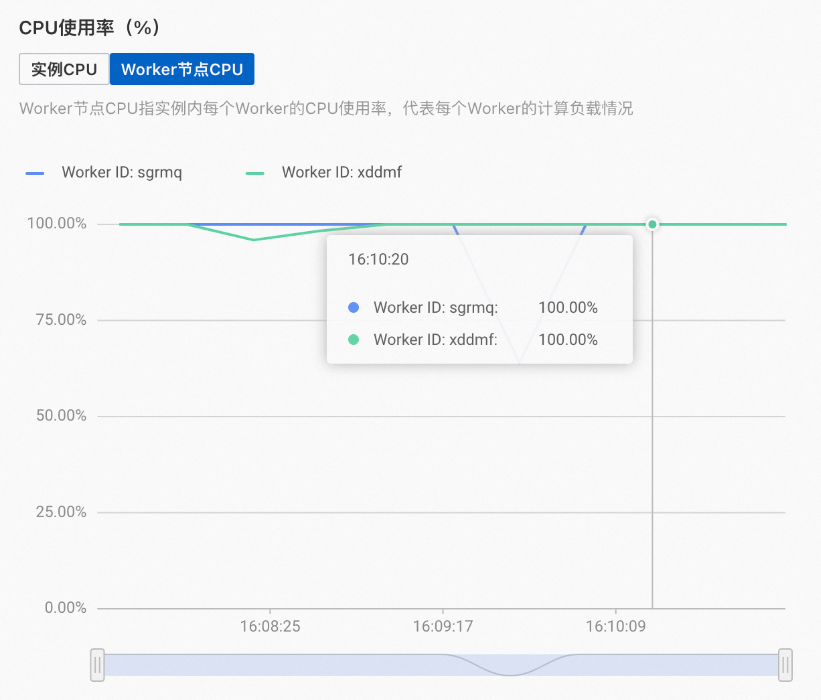
当增加replica后,同样的查询条件下,各个Worker的资源已经得到了充分的利用,如下所示。
使用限制
在Hologres中使用Shard级别的Replication时,仅Hologres V1.1及以上版本支持。
说明您可以在Hologres管控台的实例详情页查看当前实例版本,如果您的实例是V0.10以下版本,请您使用常见升级准备失败报错或加入Hologres钉钉交流群反馈,详情请参见如何获取更多的在线支持?。
replica_count必须小于等于计算节点数量。您可以在Hologres的管理控制台的实例详情页面中查看实例节点数量。
语法说明
查询当前DB的Table Group
您可以使用如下语法查看当前DB有哪些Table Group。
select * from hologres.hg_table_group_properties ;查询已有Table Group的replica count
语法示例
select property_value from hologres.hg_table_group_properties where tablegroup_name = 'table_group_name' and property_key = 'replica_count';参数说明
参数
说明
table_group_name
请输入您需要查询的Table Group名称。
replica_count
此处为固定参数名称,无需修改。
开启Replication
语法示例
通过以下命令调整Table Group的副本数量。
-- 调整Table Group的副本数量 call hg_set_table_group_property ('<table_group_name>', 'replica_count', '<replica_count>');参数说明
参数
说明
hg_set_table_group_property
修改Table Group的replica_count。
table_group_name:请输入您需要修改的Table Group名称。
replica_count:设置目标Table Group的副本数量,replica_count应小于等于计算节点数,一般是2。
设置是否开启Replication:1为默认值,表示不启用Replication功能。大于1的数值表示启用Replication功能。
关闭Replication
语法示例
-- 修改replica_count,关闭replication call hg_set_table_group_property ('table_group_name', 'replica_count', '1');参数说明
参数
说明
hg_set_table_group_property
修改Table Group的replica_count。
table_group_name:请输入您需要修改的Table Group名称。
replica_count:设置目标Table Group的副本数量。
设置是否开启Replication:1为默认值,表示不启用read replica功能。大于1的数值表示启用read replica功能。
查看加载情况
当您设置多replica之后,可以通过如下SQL查看每个Worker加载Shard的情况。
SELECT * FROM hologres.hg_worker_info;说明当Worker未完成Shard元数据加载之前,worker_id列可能为空。
示例返回结果如下:
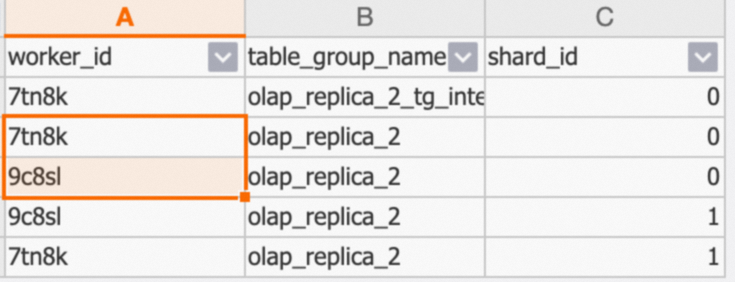
olap_replica_2有2个Shard,shard_id分别是0和1,分别在7tn8k和9c8slWorker上都有一份数据。
设置查询高可用和高吞吐策略
行为说明
当设置了Shard多副本时,如下图所示,Shard的副本会被加载到多个Worker上,此时查询会随机使用某个Worker上的Shard副本回答查询。
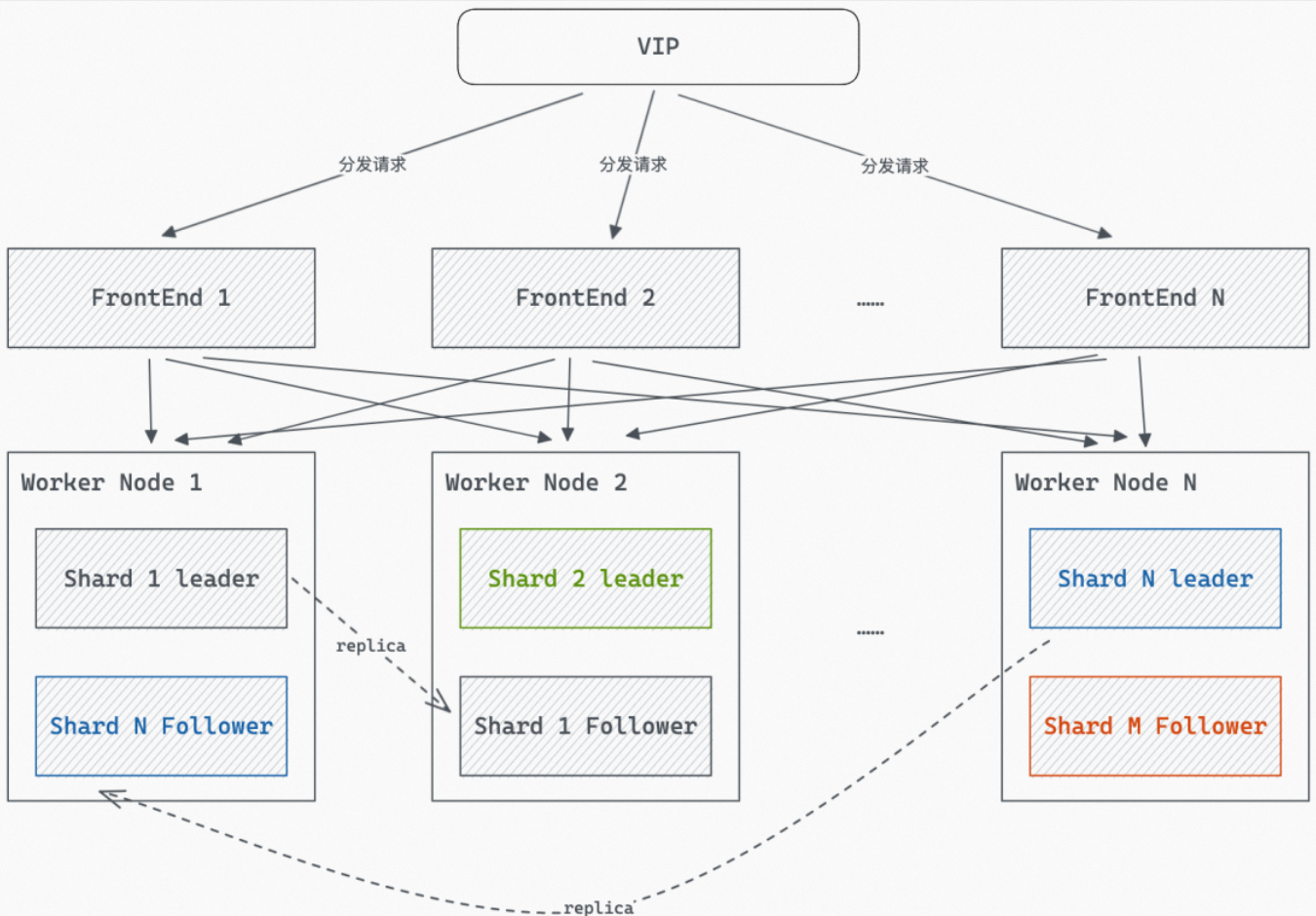
对于点查(Fixed Plan查询)场景,为了保证点查场景尽量能够返回结果,在点查场景下会进行查询重试,当查询超过一定时间未返回,会使用另一个Worker上的Shard再重试查询。
相关参数说明
hg_experimental_query_replica_mode:指定回答查询的Shard策略。使用场景
默认值
取值类型
可选值
使用示例
所有查询
leader_follower
TEXT
leader_follower(默认):表示会按照比例使用Leader Shard和Follower Shard回答查询。leader_only:表示仅使用Leader Shard回答查询,在该设置下即使replica数 > 1,也无法实现扩充吞吐和高可用的能力。follower_only:表示仅使用Follower Shard回答查询,在该设置下需要replica数 > 3,此时一个Follower Shard>=2,才能实现扩充吞吐和高可用的能力。
-- session 级别设置 SET hg_experimental_query_replica_mode = leader_follower; -- 数据库级别设置 ALTER DATABASE <database_name> SET hg_experimental_query_replica_mode = leader_follower;hg_experimental_query_replica_leader_weight:指定回答查询Leader Shard的权重。使用场景
默认值
取值类型
可选值
使用示例
所有查询
100
INT
最大值:10000
最小值:1
默认值:100
-- session 级别设置 SET hg_experimental_query_replica_leader_weight = 100; -- 数据库级别设置 ALTER DATABASE <database_name> SET hg_experimental_query_replica_leader_weight = 100;当表对应的Table Group的
replica_count >1,且查询是OLAP点查场景,查询根据hg_experimental_query_replica_mode和hg_experimental_query_replica_leader_weight设置的使用Leader Shard和Follower Shard按照一定比例回答查询。存在如下场景:场景1:当表对应的Table Group的
replica_count>1,hg_experimental_query_replica_mode=leader_follower,系统会根据Leader Shard回答查询的权重(hg_experimental_query_replica_leader_weight参数值默认为100),将查询路由到Leader Shard 和 Follower Shard进行查询,默认情况下每个Follower Shard回答查询的权重为100。例如replica_count=4,此时每个Shard有1个Leader Shard和3个Follower Shard,命中每个Leader Shard和Follower Shard的概率都是25%。场景2:当表对应的Table Group的
replica_count>1且hg_experimental_query_replica_mode=leader_only,无论replica_count是多少,系统仅使用Leader Shard回答查询。场景3:当表对应的Table Group的
replica_count>1且hg_experimental_query_replica_mode='follower_only',系统仅使用Follower Shard回答查询,默认情况下每个Follower Shard回答查询的权重为100。例如replica_count=4,此时每个Shard有1个Leader Shard和3个Follower Shard,此时只会使用3个Follower Shard回答查询,命中每个Follower Shard的概率是三分之一。
hg_experimental_query_replica_fixed_plan_ha_mode:指定点查(Fixed Plan查询)场景下高可用的模式策略。使用场景
默认值
取值类型
可选值
使用示例
点查(Fixed Plan查询)
any
TEXT
any(默认值):按照hg_experimental_query_replica_mode设定的Shard范围和hg_experimental_query_replica_leader_weight设置的权重将查询随机分发到Shard副本回答查询。leader_first:默认值,仅在hg_experimental_query_replica_mode值设为leader_follower时生效,表示优先发送查询到Leader Shard,仅在Leader Shard不可用(如超时)时才发送查询到Follower Shard。off:表示不执行重试,仅做一次查询。
-- session 级别设置 SET hg_experimental_query_replica_fixed_plan_ha_mode = any; -- 数据库级别设置 ALTER DATABASE <database_name> SET hg_experimental_query_replica_fixed_plan_ha_mode = any;hg_experimental_query_replica_fixed_plan_first_query_timeout_ms:指定点查(Fixed Plan查询)场景下高可用的模式时,表示首次查询的超时时间,超时后查询将被发送至另一个可用的Shard来重试。例如hg_experimental_query_replica_fixed_plan_first_query_timeout_ms=60表示如果查询60ms并未返回结果,系统会换一个Worker进行重试。使用场景
默认值
取值类型
可选值
使用示例
所有查询
60
INT
最大值:10000
最小值:0
默认值:60
-- session 级别设置 SET hg_experimental_query_replica_fixed_plan_first_query_timeout_ms = 60; -- 数据库级别设置 ALTER DATABASE <database_name> SET hg_experimental_query_replica_fixed_plan_first_query_timeout_ms = 60;
场景设置建议
场景1:多副本高吞吐场景
场景描述:发现监控出现了类似如下的情况,实例整体资源利用率不高,但是仅有小部分Worker计算资源使用率很高,其他Worker计算资源利用率很低,判断有可能是查询不均导致的,即大部分的查询仅用了其中几个Shard回答查询,此时您可以增加Shard的副本数量,使更多的Worker上有Shard的副本,该操作可以有效提高资源利用率和QPS。
具体操作:
增加副本数量:
例如出现数据库中有一个名为tg_replica的Table Group,您可以使用如下SQL将其副本数量设置为2。
-- 针对将名为tg_replica的table group的副本数量设置为2 call hg_set_table_group_property ('tg_replica', 'replica_count', '2');由于系统默认配置如下:
hg_experimental_query_replica_mode=leader_follower
hg_experimental_query_replica_leader_weight=100
所以增加副本数量后,系统会将查询随机分发到Leader Shard和Follower Shard对应的Worker节点上,以解决因为查询热点导致的QPS无法增加的问题。
检查Worker是否加载了Shard:
使用如下命令检查Worker是否加载了Shard。
SELECT * FROM hologres.hg_worker_info WHERE table_group_name = 'tg_replica';示例返回结果如下:
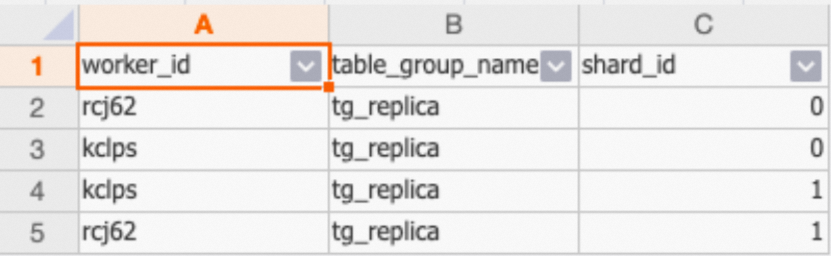
如上图所示,同一个Shard被多个Worker加载,表示设置成功。
场景2:多副本高可用场景
场景描述:您希望解决因为单Shard Failover时导致查询不可用情况。
具体操作:
增加副本数量:
例如出现数据库中有一个名为tg_replica的Table Group,您可以使用如下SQL将其副本数量设置为2。
-- 针对将名为tg_replica的table group的副本数量设置为2 call hg_set_table_group_property ('tg_replica', 'replica_count', '2');由于系统默认配置如下:
hg_experimental_query_replica_mode=leader_follower
hg_experimental_query_replica_fixed_plan_ha_mode=any
hg_experimental_query_replica_fixed_plan_first_query_timeout_ms=60
所以增加副本数量后:
此时对于OLAP场景,系统会将查询随机分发到Leader Shard和Follower Shard对应的Worker节点上。查询的同时,Master会定期检测每个Shard的是否可用,系统会主动将不可用的Shard剔除查询备选Shard,当Shard重新可用后,再加入查询备选Shard。由于发现Shard不可用需要5秒,且摘除Worker对应的FE需要10秒,所以在系统发现问题到摘除节点恢复查询需要15秒,即有15秒的查询失败持续时间,15秒后即可正常查询。
对于Fixed Plan场景,由于系统有重试机制,若一个Worker发生Failover,当时的查询响应时间变长,但是不会失败。
对于一些Fixed Plan查询场景,对于数据写入即可查的行为敏感,无法容忍Leader Shard和Follower Shard之间延迟的场景,可以将
hg_experimental_query_replica_fixed_plan_ha_mode设置为leader_first。表示在Fixed Plan下,查询始终先用Leader Shard回答查询,当Leader Shard查询超时时,再使用Follower Shard回答查询。说明此时Fixed Plan场景就不具有解决因为查询热点导致的QPS无法增加问题的能力。
检查Worker是否加载了Shard:
使用如下命令检查Worker是否加载了Shard。
SELECT * FROM hologres.hg_worker_info WHERE table_group_name = 'tg_replica';示例返回结果如下:
如上图所示,同一个Shard被多个Worker加载,表示设置成功。
常见问题
问题描述:按照场景1的场景设置参数后,查询并未分发到Follower Shard。Hologres管理控制台监控信息上仍然是设置多副本之前的Worker负载很高。
原因分析:Hologres V1.3版本之前存在
hg_experimental_enable_read_replicaGUC,用于控制Follower Shard是否能参数查询,且默认关闭。您可以使用如下SQL检查该参数是否开启。如果返回值是on表示开启,返回值是off表示关闭。SHOW hg_experimental_enable_read_replica;解决方法:如果
hg_experimental_enable_read_replica是关闭的,您可以使用如下SQL在数据库级别开启。ALTER DATABASE <database_name> SET hg_experimental_enable_read_replica = on;其中database_name为数据库名称。