实时物化视图将对明细表的数据进行预先聚合,存储为物化视图,通过查询物化视图,减少计算量,显著提升查询性能。本文为您介绍在Hologres中如何使用物化视图。
背景信息
Hologres实时物化视图不需要手动刷新物化数据,明细表实时写入,会实时反映在对物化视图的查询上,写入即可见,写入即聚合。
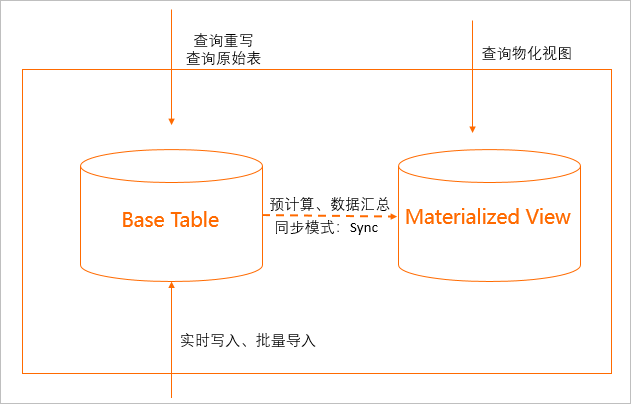 在实时物化视图中,实时写入的表叫明细表,也称Base Table,用户的Insert、Update、Delete都执行在明细表上,物化视图基于明细表的聚合规则定义,当明细表发生变更时,变更会实时同步到物化视图中。当前仅支持Insert类变更,后续会逐步增加更多类型的变更。
在实时物化视图中,实时写入的表叫明细表,也称Base Table,用户的Insert、Update、Delete都执行在明细表上,物化视图基于明细表的聚合规则定义,当明细表发生变更时,变更会实时同步到物化视图中。当前仅支持Insert类变更,后续会逐步增加更多类型的变更。
使用限制
当前实时物化视图不支持对明细表进行Delete或Update操作,所以需要将明细表设置
appendonly属性,当前对明细表任何的Delete或Update操作会提示:Table XXX is append-only。Flink实时写入时mutateType也只支持InsertOrIgnore。当前不支持异步创建物化视图,需要创建明细表的同时创建基于该表的物化视图。
当前仅支持单表的物化视图,不支持CTE、多表JOIN、子查询、不支持WHERE条件、ORDER BY、LIMIT、HAVING语句。
实时物化视图的GROUP BY Key和Value都不支持表达式,比如不支持
SUM(CASE WHEN COND THEN A ELSE B END)、SUM(col1 + col2)、GROUP BY date_trunc('hour', ts)。每张明细表最多创建10个物化视图,物化视图数量和资源消耗成正比。
如果基于分区表创建物化视图,物化视图的GROUP BY Key必须包含分区表的分区列,且不能对分区表的子表创建物化视图,只能针对分区表父表创建。
如果基于分区表创建物化视图,不支持
ATTACH PARTITION至父表语法,支持CREATE TABLE PARTITION OF语法。对于创建了物化视图的明细表,暂不支持
DROP COLUMN。物化视图的底层数据与明细表的TTL一致,不可以手动设置物化视图的TTL,否则会出现物化视图数据和明细表数据不一致的情况。
支持的聚合函数
物化视图当前支持如下聚合函数。
SUM
COUNT
AVG
MIN
MAX
RB_BUILD_CARDINALITY_AGG(只支持BIGINT,需创建Extension roaringbitmap)
SQL示例
创建实时物化视图
BEGIN; CREATE TABLE base_sales( day text not null, hour int , ts timestamptz, amount float, pk text not null primary key ); CALL SET_TABLE_PROPERTY('base_sales', 'mutate_type', 'appendonly'); --当实时物化视图被Drop后,可以取消明细表的appendonly属性,执行以下命令 --CALL SET_TABLE_PROPERTY('base_sales', 'mutate_type', 'none'); CREATE MATERIALIZED VIEW mv_sales AS SELECT day, hour, avg(amount) AS amount_avg FROM base_sales GROUP BY day, hour; COMMIT; insert into base_sales values(to_char(now(),'YYYYMMDD'),'12',now(),100,'pk1'); insert into base_sales values(to_char(now(),'YYYYMMDD'),'12',now(),200,'pk2'); insert into base_sales values(to_char(now(),'YYYYMMDD'),'12',now(),300,'pk3');分区表创建物化视图
BEGIN; CREATE TABLE base_sales_p( day text not null, hour int, ts timestamptz, amount float, pk text not null, primary key (day, pk) ) partition by list(day); CALL SET_TABLE_PROPERTY('base_sales_p', 'mutate_type', 'appendonly'); --day是分区列,要出现在视图的group by的条件中 CREATE MATERIALIZED VIEW mv_sales_p AS SELECT day, hour, avg(amount) AS amount_avg FROM base_sales_p GROUP BY day, hour; COMMIT; create table base_sales_20220101 partition of base_sales_p for values in('20220101');查询物化视图
SELECT * FROM mv_sales WHERE day = to_char(now(),'YYYYMMDD') AND hour = 12;删除物化视图
DROP MATERIALIZED VIEW mv_sales;查询物化视图占用存储空间
select pg_relation_size('mv_sales');查询所有物化视图底层占用空间
SELECT schemaname || '.' || matviewname AS mv_full_name, pg_size_pretty(pg_relation_size('"' || schemaname || '"."' || matviewname || '"')) AS mv_size, pg_relation_size('"' || schemaname || '"."' || matviewname || '"') AS order_size FROM pg_matviews ORDER BY order_size DESC;
使用物化视图提升精确UV计算性能
精确UV计算是计算复杂度非常高的算子,通常是系统的性能瓶颈部分。Hologres支持RB_BUILD_CARDINALITY_AGG聚合函数,通过利用RoaringBitmap数据结构,可以对BIGINT类数据(通常是表示业务ID字段)进行物化视图预聚合,实现UV统计实时去重,可按照如下方式创建物化视图,当前仅支持BIGINT类字段的聚合去重。
--UV计算依赖RoaringBitmap数据类型,需要提前创建RoaringBitmap extension
CREATE EXTENSION if not exists roaringbitmap;
BEGIN;
CREATE TABLE base_sales_r(
day text not null,
hour int ,
ts timestamptz,
amount float,
userid bigint,
pk text not null primary key
);
CALL SET_TABLE_PROPERTY('base_sales_r', 'mutate_type', 'appendonly');
CREATE MATERIALIZED VIEW mv_sales_r AS
SELECT
day,
hour,
avg(amount) AS amount_avg,
rb_build_cardinality_agg(userid) as user_count
FROM base_sales_r
GROUP BY day, hour;
COMMIT;
insert into base_sales_r values(to_char(now(),'YYYYMMDD'),'12',now(),100,1,'pk1');
insert into base_sales_r values(to_char(now(),'YYYYMMDD'),'12',now(),200,2,'pk2');
insert into base_sales_r values(to_char(now(),'YYYYMMDD'),'12',now(),300,3,'pk3');
select user_count as UV from mv_sales_r where day = to_char(now(),'YYYYMMDD') AND hour = 12;通过rb_build_cardinality_agg计算去重数,mv_sales_r中user_count代表userid去重数,查询user_count可获得去重数。
使用物化视图支持多维度聚合查询
假设定义了上述的mv_sales物化视图,且明细表base_sales中当前含有以下明细数据。
Day | Hour | Amount | PK |
20210101 | 12 | 2 | pk1 |
20210101 | 12 | 4 | pk2 |
20210101 | 13 | 6 | pk3 |
直接查询sales_mv将会有如下结果。
postgres=> select * from mv_sales;
day | hour | amount_avg
-----------+---------+--------------
20210101 | 12 | 3
20210101 | 13 | 6这时如果想更改查询物化视图的聚合维度,例如使用维度day进行avg聚合计算,则会得到的会是一个错误的结果,因为avg的avg不等于total的avg。
postgres=> select day, avg(amount_avg) from mv_sales group by day;
day | avg
-----------+--------
20210101 | 4.5这时候一种办法是再建一张以day为维度进行聚合的物化视图,但这样会导致物化视图的数量膨胀,Hologres提供了一种基于聚合中间状态的实现,使得用户仅用一张物化视图,实现不同维度聚合查询。这里以Avg为例,修改聚合视图的定义如下。
BEGIN;
CREATE TABLE base_sales(
day text not null,
hour int ,
ts timestamptz,
amount float,
pk text not null primary key
);
CALL SET_TABLE_PROPERTY('base_sales', 'mutate_type', 'appendonly');
CREATE MATERIALIZED VIEW mv_sales_partial AS
SELECT
day,
hour,
avg(amount) as avg,
avg_partial(amount) AS amt_avg_partial
FROM base_sales
GROUP BY day, hour;
COMMIT;原先的avg聚合函数重新定义为avg_partial聚合函数,amount_avg_partial列存储的是聚合结果的中间状态,查询时需要修改查询函数,将avg聚合函数改写为avg_final最终聚合函数,声明是对聚合结果中间状态的最终聚合。
postgres=> select day, avg(avg) as avg_avg, avg_final(amt_avg_partial) as real_avg from mv_sales_partial group by day;
day | avg_avg | real_avg
-----------+-----------+----------
20210101 | 4.5 | 4目前支持以下聚合函数及对应的partial聚合函数。
普通聚合函数 | Partial聚合函数 | 最终聚合函数 |
AVG | AVG_PARTIAL | AVG_FINAL |
RB_BUILD_CARDINALITY_AGG | RB_BUILD_AGG | RB_OR_CARDINALITY_AGG |
TTL说明
如果明细表设置了TTL,并创建了物化视图,那么在TTL临界点附近的数据,Hologres无法保证明细表和物化视图查询结果的一致性,查询TTL临界点附近的物化视图数据的结果,是个未定义行为。下面以明细表base_sales_table和物化视图sales_mv为例。
为base_sales_table设置了TTL,如果数据由于TTL到期被回收掉,那么此时查询明细表的结果如下所示。
postgres=> SELECT
day,
hour,
avg(amount) AS amount_avg
FROM base_sales
GROUP BY day, hour;
--查询结果
day | hour | amount_avg
-----------+---------+--------------
20210101 | 12 | 4
20210101 | 13 | 6但是由于被回收的数据,已经物化到了物化视图的数据中,所以查询物化视图时有可能得到的结果如下。
postgres=> select * from mv_sales;
--查询结果
day | hour | amount_avg
-----------+---------+--------------
20210101 | 12 | 3
20210101 | 13 | 6此时查询结果不一致,建议改进方案如下。
明细表不要设置TTL。
明细表设置TTL,但是物化视图的GROUP BY含有数据的时间字段,且查询物化视图的时候,不会去查询在TTL临界点附近的数据。
明细表建成分区表,不设置TTL,回收数据通过删除(Drop)分区表来实现。
实时物化视图使用最佳实践
建表时建议将物化视图的GROUP BY Key设置为明细表的Distribution Key,这样能进一步提升数据的压缩率,提升查询性能。
查询时建议将查询物化视图时常用的过滤条件,放在GROUP BY Key的前列(符合Clustering Key左匹配原则)。
物化视图的智能路由
查询时不需要显式指定物化视图表名称,可以像之前一样基于基础表进行查询。如果有匹配的物化视图表,优化器会智能路由到最佳的物化视图表来加速查询。在查询时,物化视图表的选择规则如下:
选择包含所有查询列或可以通过间接计算得到的物化视图表。
选择GROUP BY列字段包含原始查询GROUP BY所有列的物化视图表。
当有多个物化视图表符合条件时,选择GROUP BY列字段少的物化视图表。
当前支持智能路由的聚合函数有SUM、COUNT、MIN和MAX。