本文为您介绍Hologres的执行引擎以及内部的各组件。
执行引擎优势
Hologres的执行引擎(主要以HQE为主)是自研的执行引擎,通过与大数据领域最新技术结合,实现了对各种查询类型的高性能处理,主要具有如下优势。
分布式执行
执行引擎是一个和存储计算分离架构配合的分布式执行模型。执行计划由异步算子组成的执行图DAG(有向无环图)表示,可以表达各种复杂查询,并且完美适配Hologres的数据存储模型,方便对接查询优化器,利用各种查询优化技术。
全异步执行
端到端的全异步处理框架,可以避免高并发系统的瓶颈,充分利用资源,并且最大可能地避免存储计算分离系统带来的读数据延迟的影响。
向量化和列处理
算子内部处理数据时最大可能地使用向量化执行,与存储引擎深度集成,通过灵活的执行模型,充分利用各种索引,最大化地延迟向量物化和延迟计算,避免不必要的读数据和计算。
自适应增量处理
对常见实时数据应用查询模式进行自适应增量处理。
特定查询深度优化
对一些特定查询模式的独特优化。
更多技术原理详情,请参见Hologres执行引擎揭秘。
Query执行过程
当客户端下发一个Query后,在执行引擎中实际上会有多个worker节点,以其中的一个worker节点为例,执行过程如下图所示。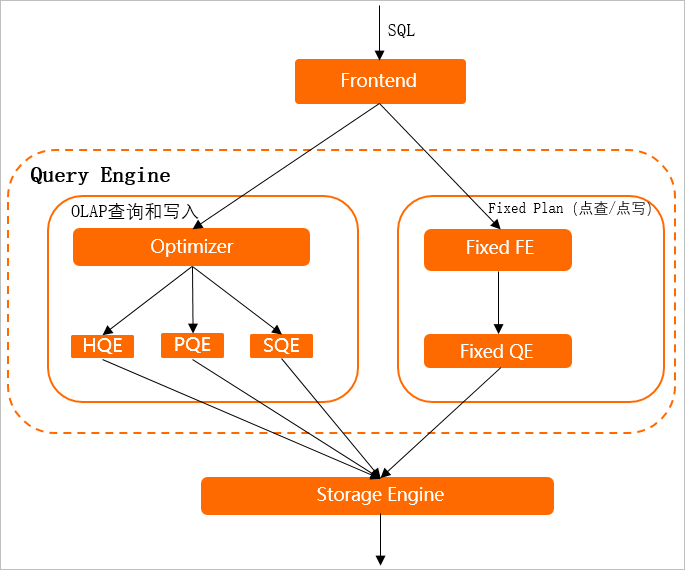
当客户端发起一个SQL后,执行过程如下。
Frontend(FE)节点对SQL进行解析和认证,并分发至执行引擎(Query Engine)的不同执行模块。
执行引擎(Query Engine)会根据SQL的特征走不同的执行路径。
如果是点查/点写的场景,会跳过优化器(Query Optimizer,QO),直接分发至后端获取数据,减少数据传送链路,从而实现更优的性能。整个执行链路也叫Fixed Plan,点查(与HBase的KV查询)、点写场景会直接走Fixed Plan。
如果是OLAP查询和写入场景:首先会由优化器(Query Optimizer,QO)对SQL进行解析,生成执行计划,在执行计划中会预估出算子执行Cost、统计信息、空间裁剪等。QO会通过生成的执行计划,决定使用HQE、PQE、SQE或者Hive QE对算子进行真正的计算。
HQE、PQE、SQE的对比介绍如下。
HQE(Hologres Query Engine)
Hologres自研执行引擎,采用可扩展的MPP架构全并行计算,向量化算子发挥CPU极致算力,从而实现极致的查询性能。(QE主要由HQE组成)。
PQE(Postgres Query Engine)
用于兼容Postgres提供扩展能力,支持PG生态的各种扩展组件,如PostGIS,UDF(PL/JAVA,PL/SQL,PL/Python)等。部分HQE还没有支持的函数和算子,会通过PQE执行,每个版本都在持续优化中,最终目标是去掉PQE。
SQE(Seahawks Query Engine)
无缝对接MaxCompute(ODPS)的执行引擎,实现对MaxCompute的本地访问,无需迁移和导入数据,就可以高性能和全兼容的访问各种MaxCompute文件格式,以及Hash/Range clustered table等复杂表,实现对PB级离线数据的交互式分析。
执行引擎决定正确的执行计划,然后会通过存储引擎(Storage Engine,SE)进行数据获取,最后对每个Shard上的数据进行合并,返回至客户端。