本文主要介绍全增量数据同步的使用场景,功能列表,迁移优势,使用限制以及创建数据同步任务等操作。
使用场景
大版本升级:HBase1.x升级HBase2.x。
跨地域迁移 :例如从青岛机房迁移到北京机房。
跨账号迁移:支持不同账号迁移数据。
集群升配:从4核8G迁移到8核16G集群。
业务拆分:将部分业务迁移到新的集群。
功能列表
支持094、098、1.x、2.x、Lindorm任意版本之间的不停机迁移。
支持表结构迁移、实时数据同步、全量数据迁移。
支持整库迁移、namespace迁移、表级别迁移。
迁移支持表重命名。
迁移支持指定时间范围、rowkey范围、指定列。
提供OpenAPI,支持调用API创建迁移任务。
迁移优势
不停服数据迁移,同时搞定历史数据迁移、实时增量数据的同步。
迁移过程中不会和源集群的HBASE交互,只读取源集群的HDFS,尽可能减少对源集群在线业务的影响。
文件层的数据拷贝比通常API层的数据迁移通常能节省50%以上的流量高效性。
单个节点迁移速度可达到150MB/s,节点数支持水平扩展,能够满足支持TB、PB级别的数据迁移稳定性。
有完善的错误重试机制,实时监控任务速度和进度,支持任务失败报警。
自动同步Schema,保证分区一致。
使用限制
不支持开启Kerberos集群。
不支持单节点云HBase实例。
由于网络原因,不支持经典网络下的云HBase实例。
增量数据同步基于HBase WAL实现异步数据同步, Bulkload的数据和不写WAL的数据将不会被同步。
增量同步中的日志管理
开启增量同步后,如果不消费数据,默认日志会保留48小时,超时后订阅关系自动取消,保留的数据自动删除。
什么场景会导致“不消费数据”:没有终止任务的前提下直接释放LTS集群;同步任务暂停;任务异常阻塞
注意事项
迁移前请确认目标集群的HDFS容量,防止迁移过程中出现容量写满的情况。
增量同步提交前,推荐修改一下源集群的日志保留时间,给增量同步出错预留一些处理的时间 (hbase-site.xml 的 hbase.master.logcleaner.ttl 调大为12小时以上,重启HMaster )。
客户无需在目标集群创建表,BDS同步服务会自动创建和源集群一样的表,包括分区的信息。客户自建的目标表可能会和源表分区很不一致,这可能会导致迁移完成之后,目标表会进行频繁的split、compaction,如果表的数据量十分庞大,可能会导致这个过程非常耗时。
如果源表带有coprocessor, 在创建目标表的时候需要确保目标集群包含coprocessor对应的jar包。
准备工作
检查源集群、目标集群、LTS的网络连通性。
添加HBase、Lindorm数据源。
登录LTS操作页面。
创建任务
在左侧导航选择Lindorm/HBase迁移 > 一键迁移。
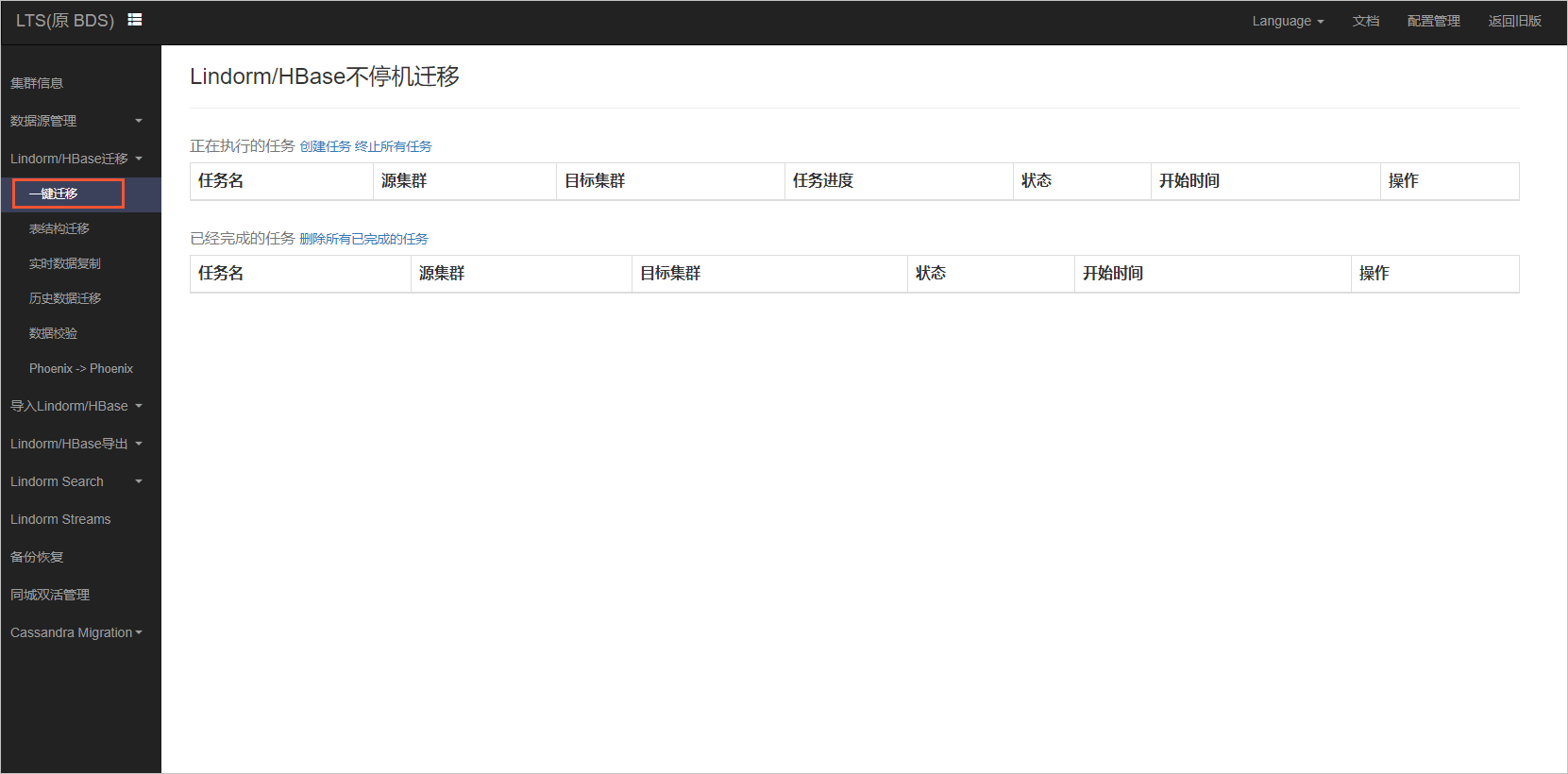
单击创建任务。
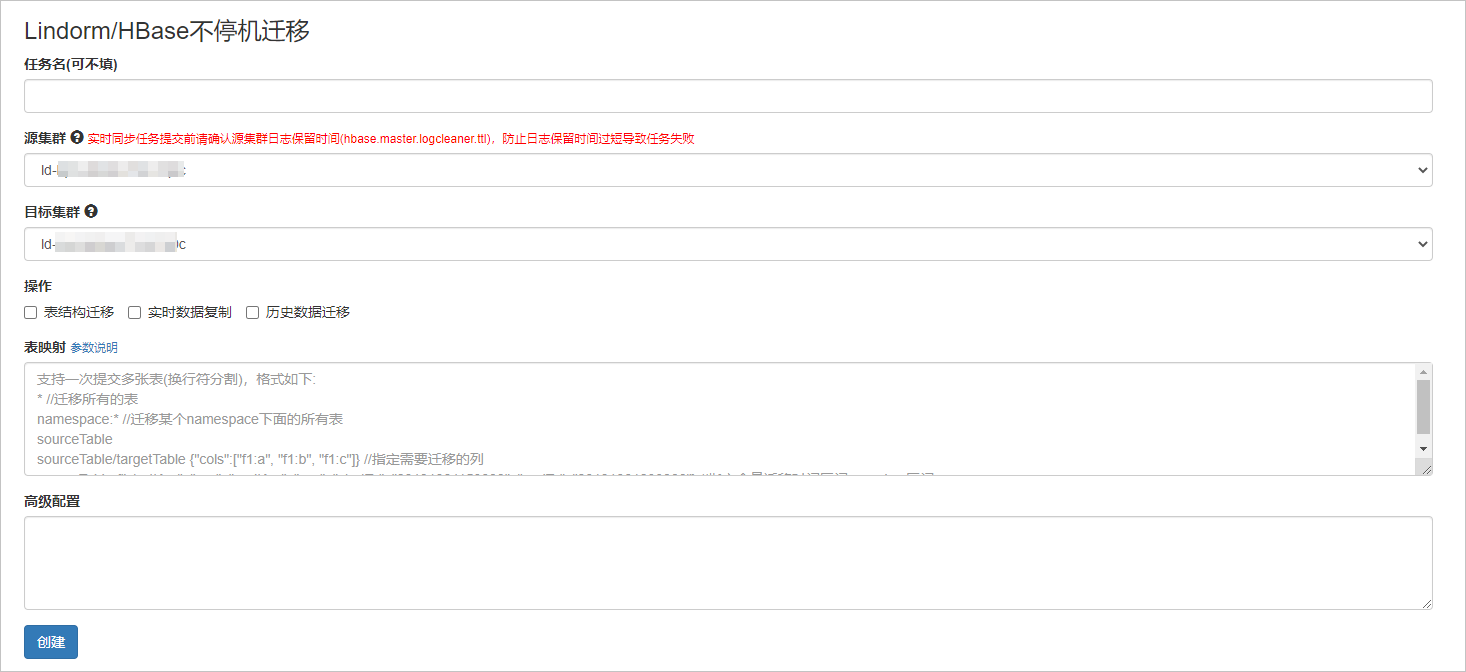
任务名:只支持英文字符、数字,非必填,默认任务ID作为任务名。
根据界面提示设置源集群和目标集群。
选择需要的操作
表结构迁移:在目标集群创建表(schema、分区信息一致), 目标集群表已存在会跳过。
实时数据复制:同步源集群实时增量的数据。
历史数据迁移:文件级别的全量文件物理迁移。
表映射:填写表名,使用换行符分割。
高级配置:可不填。
查看任务
在左侧导航选择Lindorm/HBase迁移 > 一键迁移查看任务。
查看任务详情
在左侧导航选择Lindorm/HBase迁移 > 一键迁移。
单击需要查看的任务名。查看对应任务的执行情况。
关于切流
等待全量任务迁移完成,增量同步的时延比较小(几秒或者几百毫秒)。
开启LTS数据抽样校验,对于大表的抽样校验,抽样比例不宜过大,避免对在线业务产生影响。
业务验证。
业务切流。