本文为您介绍如何创建物化表,以及进行历史数据回刷、修改新鲜度、查看物化表血缘关系。
使用限制
仅实时计算引擎VVR 8.0.10及以上版本支持。
目前仅支持元数据存储类型为Filesystem或DLF的Paimon Catalog,自定义的Paimon Catalog不支持创建物化表。
需要具备开发及部署作业权限,详情请参见开发控制台授权。
暂不支持引用临时对象,如temporary table/temporary function/temporary view。
创建物化表
语法结构
CREATE MATERIALIZED TABLE [catalog_name.][db_name.]table_name
-- 主键约束
[([CONSTRAINT constraint_name] PRIMARY KEY (column_name, ...) NOT ENFORCED)]
[COMMENT table_comment]
-- 分区键
[PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]
-- With选项
[WITH (key1=val1, key2=val2, ...)]
-- 数据新鲜度
FRESHNESS = INTERVAL '<num>' { SECOND | MINUTE | HOUR | DAY }
-- 刷新模式
[REFRESH_MODE = { CONTINUOUS | FULL }]
AS <select_statement>参数说明
参数 | 是否必填 | 说明 |
FRESHNESS | 是 | 用于指定物化表的数据新鲜度。定义了物化表数据相对于源表更新的最大延迟时间。 说明
|
AS <select_statement> | 是 | 该子句用于定义填充物化表数据的查询。上游表可以是物化表、表或视图。SELECT语句支持所有Flink SQL查询。 |
PRIMARY KEY | 否 | 定义了一组可选的列,用于唯一标识表中的每一行。被标识字段列必须非空。 |
PARTITIONED BY | 否 | 定义了一组可选的列,用于对物化表进行分区。 |
WITH Options | 否 | 可以定义创建物化表所需的表属性和分区字段的时间格式参数。 例如,分区字段的时间格式参数 |
REFRESH_MODE | 否 | 用于指定物化表的刷新模式。指定的刷新模式比框架根据新鲜度自动推导的模式具有更高的优先级,以满足特定场景的需求。
|
操作步骤
登录实时计算管理控制台。
单击目标工作空间操作列下的控制台。
在左侧导航栏选择数据管理,单击目标Paimon Catalog。
单击目标数据库后,单击创建物化表。
假设有一张基础表orders(主键order_id,类目名称order_name,日期ds)。下面将展示基于该表创建物化表:
基于orders表构建物化表mt_order,查询所有字段结果为表字段,数据新鲜度为5秒。
CREATE MATERIALIZED TABLE mt_order FRESHNESS = INTERVAL '5' SECOND AS SELECT * FROM `paimon`.`db`.`orders` ;基于物化表mt_order创建物化表mt_id,查询order_id、ds为表字段,且设置order_id为主键,ds为分区字段,数据新鲜度为30分钟。
CREATE MATERIALIZED TABLE mt_id ( PRIMARY KEY (order_id) NOT ENFORCED ) PARTITIONED BY(ds) FRESHNESS = INTERVAL '30' MINUTE AS SELECT order_id,ds FROM mt_order ;创建物化表mt_ds,基础表为物化表mt_order,为
ds分区字段列指定了date-formatter(时间格式)。每次调度时,调度时间减去新鲜度将转换为相应的ds分区值。例如,设定数据新鲜度为1小时的情况下,在2024-01-01 00:00:00的调度时间,则计算出来的ds=20231231,只有分区ds = '20231231'的数据会被刷新。如果定时调度时间为2024-01-01 01:00:00,计算出来的ds=20240101,则分区ds = '20240101'的数据会被刷新。CREATE MATERIALIZED TABLE mt_ds PARTITIONED BY(ds) WITH ( 'partition.fields.ds.date-formatter' = 'yyyyMMdd' ) FRESHNESS = INTERVAL '1' HOUR AS SELECT order_id,order_name,ds FROM mt_order ;说明partition.fields.#.date-formatter中的'#'字段必须是有效的字符串类型分区字段。partition.fields.#.date-formatter指定物化表的时间分区格式化,其中'#'为字符串类型的分区字段名称,可以提示系统在刷新数据时,刷新哪个分区的数据。
开始/停止更新物化表。
单击对应Catalog下的目标物化表。
单击右侧开始更新/停止更新。
说明在停止更新时,如果最近一次更新正在进行,将在此次数据更新完成后停止。
查询物化表作业详情。
在表结构详情页签中,查看基本信息,单击数据更新作业或工作流对应的作业ID,即可查看详情。
修改物化表查询语句
使用限制
仅实时计算引擎VVR 11.1及以上版本支持新建的物化表修改Query。
修改Query时仅支持追加列和修改计算逻辑,不支持调整现有列的顺序或修改已有列的定义。
操作类型
是否支持
说明
追加新列
支持
可保持列顺序的同时,在schema后添加新列。
修改现有列的计算逻辑(不改变列名和类型)
支持
例如修改计算逻辑,但列名和数据类型需保持一致。
修改现有列的顺序
不支持
列顺序固定,需删除并重新创建物化表。
修改现有列的名称或数据类型
不支持
需删除并重新创建物化表。
修改示例
单击编辑表,修改对应的Query。示例参考如下:
ALTER MATERIALIZED TABLE `paimon`.`default`.`mt-orders` AS SELECT *, price * quantity AS total_price FROM orders WHERE price * quantity > 1000 ;点击预览,查看前后对比。

单击确认后,可在表结构详情看到新增的对应列和查询逻辑。
新增字段通常不会影响下游,但如果下游使用动态解析(如 SELECT * 或自动映射字段)同步上游物化表,可能导致同步任务失败或出现数据格式不匹配的报错。建议尽量避免动态解析,优先使用固定字段,并在上游变更时及时同步更新下游表结构。
物化表增量更新
使用限制
仅实时计算引擎VVR 8.0.11及以上版本支持。
物化表的更新模式
物化表提供三种更新模式:流更新模式、全量批更新模式、增量批更新模式。
物化表的流批模式由数据新鲜度决定(小于30分钟为流模式,大于等于30分钟为批模式)。在批处理模式下,全量更新或增量更新由引擎自动判断。增量更新仅计算自上次更新以来的增量数据,并将其合并至物化表中;而全量更新则会计算整个表或整个分区的数据,并对物化表中的数据进行覆盖。批模式下引擎优先考虑使用增量更新,当增量更新无法支持此物化表时,才会使用全量更新。
增量更新条件
仅当物化表满足以下条件时,才会使用增量更新。
在定义物化表时,未配置
partition.fields.#.date-formatter参数指定分区字段的时间格式。源表未定义主键。
物化表中的查询语句支持增量更新情况如下:
SQL语句
支持情况
SELECT
支持选择列以及标量函数表达式(包括用户自定义函数),暂不支持聚合函数。
FROM
支持表名或子查询。
WITH
支持公用表表达式Common Table Expression(CTE)。
WHERE
支持过滤条件包括各种标量函数表达式(包括用户自定义函数),不支持包含子查询(如 WHERE [NOT] EXISTS <子查询>、WHERE <列名> [NOT] IN <子查询> 等)。
UNION
仅支持UNION ALL。
JOIN
支持INNER JOIN。
暂不支持LEFT/RIGHT/FULL [OUTER] JOIN,除了以下LATERAL JOIN及Lookup Join的情况。
支持[LEFT [OUTER]] JOIN LATERAL table函数表达式(包括用户自定义函数)。
Lookup Join仅支持A [LEFT [OUTER]] JOIN B FOR SYSTEM_TIME AS OF PROCTIME()。
说明支持不带JOIN关键字的JOIN,例如SELECT * FROM a, b WHERE a.id = b.id。
当前INNER JOIN的增量计算仍然会读取两个源表的全量数据。
GROUP BY
暂不支持。
增量更新示例
示例一:对源表orders数据使用标量函数进行处理。
CREATE MATERIALIZED TABLE mt_shipped_orders (
PRIMARY KEY (order_id) NOT ENFORCED
)
FRESHNESS = INTERVAL '30' MINUTE
AS
SELECT
order_id,
COALESCE(customer_id, 'Unknown') AS customer_id,
CAST(order_amount AS DECIMAL(10, 2)) AS order_amount,
CASE
WHEN status = 'shipped' THEN 'Completed'
WHEN status = 'pending' THEN 'In Progress'
ELSE 'Unknown'
END AS order_status,
DATE_FORMAT(order_ts, 'yyyyMMdd') AS order_date,
UDSF_ProcessFunction(notes) AS notes
FROM
orders
WHERE
status = 'shipped';示例二:对源表orders数据使用Lateral Join以及Lookup Join进行信息补充。
CREATE MATERIALIZED TABLE mt_enriched_orders (
PRIMARY KEY (order_id, order_tag) NOT ENFORCED
)
FRESHNESS = INTERVAL '30' MINUTE
AS
WITH o AS (
SELECT
order_id,
product_id,
quantity,
proc_time,
e.tag AS order_tag
FROM
orders,
LATERAL TABLE(UDTF_StringSplitFunction(tags, ',')) AS e(tag))
SELECT
o.order_id,
o.product_id,
p.product_name,
p.category,
o.quantity,
p.price,
o.quantity * p.price AS total_amount,
order_tag
FROM o
LEFT JOIN
product_info FOR SYSTEM_TIME AS OF PROCTIME() AS p
ON
o.product_id = p.product_id;历史数据回刷
以往在使用流作业后,如需利用前一天的全量数据来订正流处理的结果,则必须单独开发一个批作业进行处理。而使用物化表后,可以直接选择物化表的历史数据分区进行数据回刷。这一改变降低了开发和运维成本,实现了流批一体化的能力。
单击目标Catalog下的物化表。
在数据信息页签,进行数据回刷。
在创建物化表中,如果已声明分区字段,则为分区表;否则为非分区表。
分区表
查看数据分区,如果为首次回刷或没有所需要的分区,单击手动更新。如果已有分区,可以选择对应的分区回刷,单击回刷。
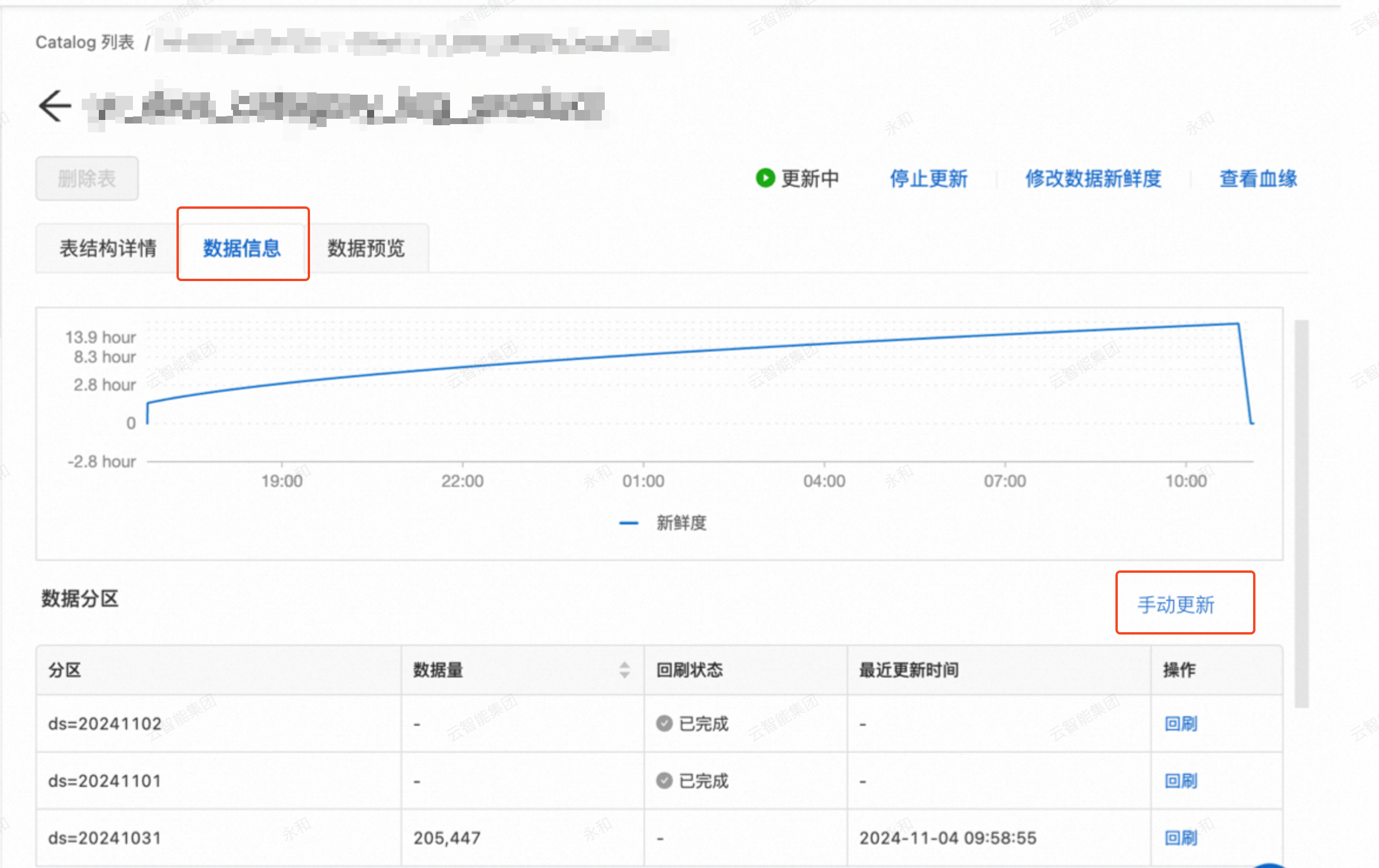
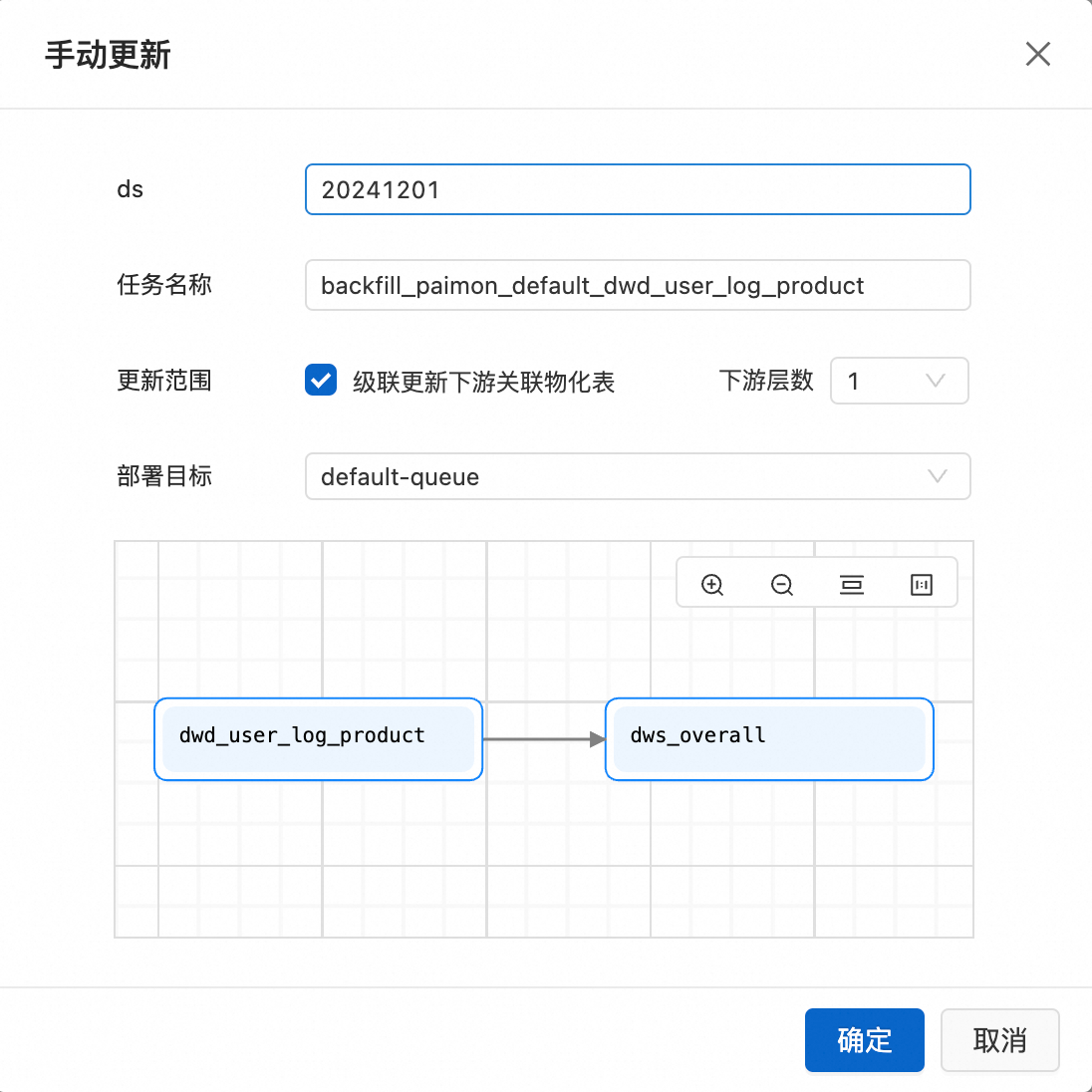
参数说明:
分区字段:该参数为表分区字段。例如填写20241201,将会回刷所有ds=20241201的数据。
任务名称:数据回刷任务名称。
更新范围(可选):是否级联更新下游关联物化表。以该表为起点,更新链路上的所有物化表。(下游层数最大为6)。
说明分区表更新,下游的物化表在分区字段上需与起始表完全一致,否则更新操作将失败。
链路中某个物化表更新失败时,下游节点将会全部失败。
部署目标:支持选择queue和Session队列。默认选择default-queue。
非分区表
查看数据情况,单击回刷。
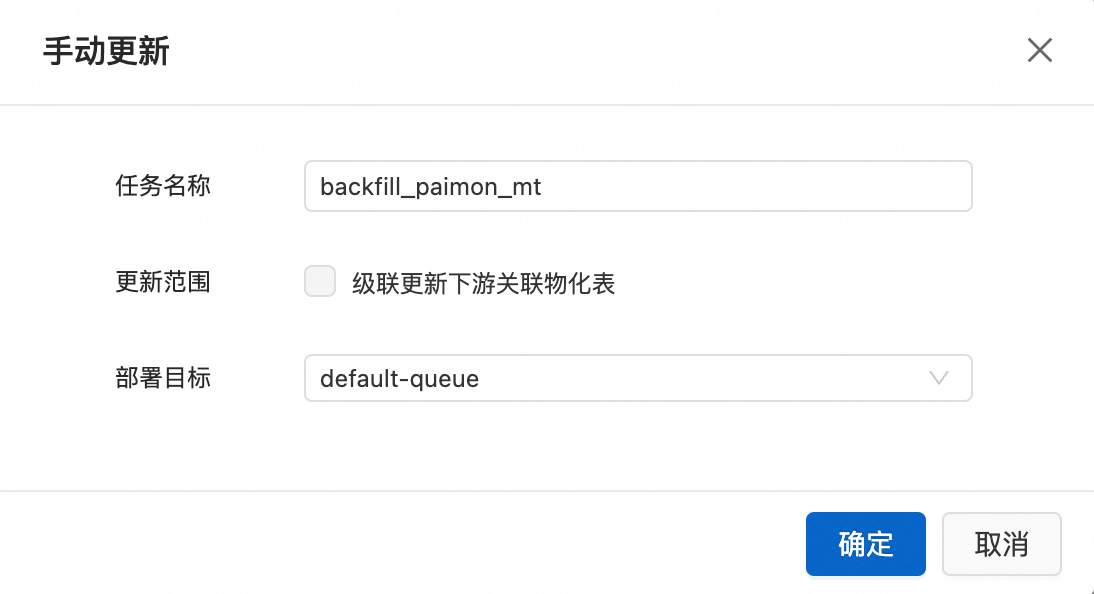
参数说明:
任务名称:数据回刷任务名称。
更新范围:非分区表不可选。
说明更新时下游数据将进行全量刷新。
链路中某个物化表更新失败时,下游节点将会全部失败。
起始表的新鲜度被系统判定为流任务且为非分区表时,不支持级联更新。
部署目标:支持选择queue和Session队列。默认选择default-queue。
定时回刷与批量回刷。
使用任务编排创建物化表工作流,进行周期调度,从而实现定时回刷功能。同时,也可以通过工作流的数据回刷功能,选择时间范围,进行数据批量回刷。
修改数据新鲜度
单击对应Catalog下的materialized table库,单击对应的物化表。
单击右侧修改数据新鲜度。
当物化表为非主键表时,不允许更改任务的流批属性。例如,若将数据新鲜度从2秒修改为1小时,此时Flink会把流作业转变为批作业;反之亦然,不可进行此类操作。(小于30分钟为流作业,大于等于30分钟为批作业)
当基础表为物化表时,需确保下游的数据新鲜度是上游的1~N倍(N为正整数)。
数据新鲜度最大不能超过1天。
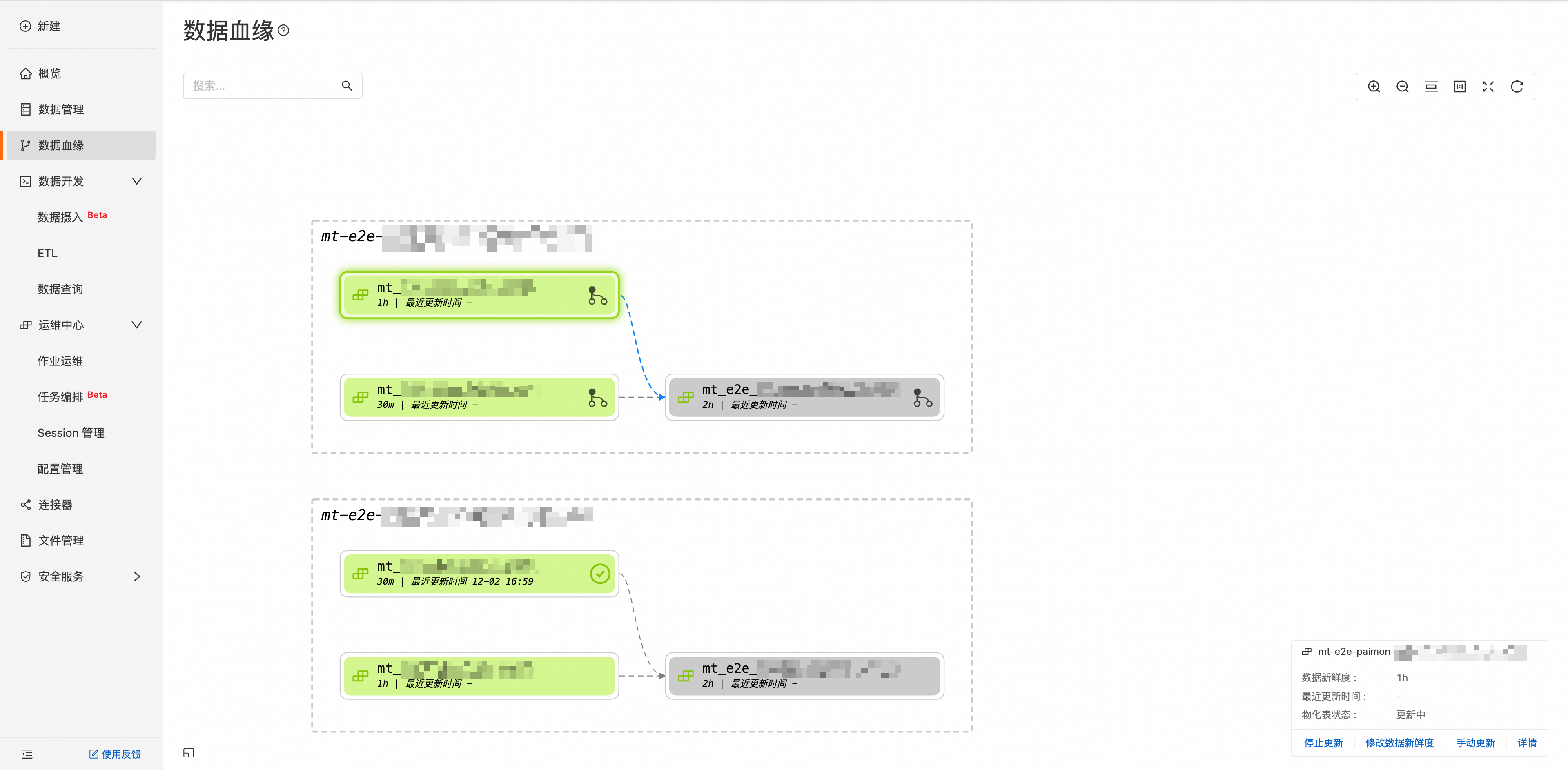
查看数据血缘
数据血缘页面可以查询所有物化表之间的血缘关系,并支持在该页面直接对物化表进行开始/停止更新,修改数据新鲜度等操作,单击详情,即可跳转到对应的物化表进行查看。
相关文档
物化表介绍详情请参见物化表管理。
基于Paimon和物化表,构建流批一体的湖仓分析处理链路,以及通过修改表数据新鲜度,完成由批到流的切换,实现数据实时更新,详情请参见物化表快速入门(构建流批一体湖仓)。